La creazione di grafici statistici in Python può essere una seccatura, soprattutto se li stai generando manualmente. Ma con l'aiuto della libreria di visualizzazione dei dati Python di Seaborn, puoi semplificare il tuo lavoro e creare bellissimi grafici rapidamente e con meno righe di codice.
Con Seaborn, creare bellissimi grafici statistici per i tuoi dati è un gioco da ragazzi. Questa guida ti mostrerà come utilizzare questa potente libreria attraverso esempi di vita reale.
Prerequisiti
Questo tutorial sarà una dimostrazione pratica. Se desideri continuare, assicurati di avere quanto segue:
- Un computer Windows o Linux con Python e Anaconda installati. Questo tutorial utilizzerà Anaconda 2021.11 con Python 3.9 su un PC Windows 10.
Cos'è la libreria Python di Seaborn?
La libreria Seaborn Python è una libreria di visualizzazione dei dati Python basata sulla libreria Matplotlib. Seaborn offre un ricco set di strumenti di alto livello per la creazione di grafici e grafici statistici. La capacità di Seaborn di integrarsi con gli oggetti Pandas Dataframe ti consente di visualizzare i dati rapidamente.
Un DataFrame rappresenta dati tabulari, come quelli che troveresti in una tabella, in un foglio di lavoro o in un file CSV con valori separati da virgole.
Seaborn funziona con Pandas DataFrames e converte i dati nascosti in codice che Matplotlib può comprendere.
Sebbene siano disponibili molte trame di alta qualità, in questo tutorial imparerai le tre famiglie di trame Seaborn integrate più comuni per aiutarti a iniziare.
- Trame relazionali.
- Grafici di distribuzione.
- Grafici categoriali.
Seaborn include molte altre trame e questo tutorial non può coprire tutto. La documentazione dell'API Seaborn e il tutorial sono ottimi punti di partenza per conoscere tutti i diversi tipi di trame Seaborn.
Impostazione di un nuovo ambiente JupyterLab e Seaborn Python
Prima di iniziare il tuo viaggio in Seaborn, devi prima configurare un ambiente Jupyter Lab. Inoltre, per coerenza con gli esempi, lavorerai su un set di dati specifico insieme a questo tutorial.
JupyterLab è un'applicazione Web che consente di combinare codice, rich text, grafici e altri media in un unico documento. Puoi anche condividere i taccuini online con altri o utilizzarli come documenti eseguibili.
Per iniziare a configurare il tuo ambiente, segui questi passaggi.
1. Apri Anaconda Navigato r sul tuo computer.
un. Su un computer Windows:fai clic su Avvia —> Anaconda3 —> Navigatore Anaconda .
b. Su un computer Linux:esegui anaconda-navigator comando sul terminale.
2. Su Anaconda Navigator, cerca JupyterLab applicazione e fare clic su Avvia . In questo modo si aprirà un'istanza di JupyterLab in un browser web.

3. Dopo aver avviato JypyterLab, apri la barra laterale del Browser dei file e crea una nuova cartella chiamata ATA_Seaborn sotto il tuo profilo o directory home. Questa nuova cartella sarà la directory del tuo progetto.
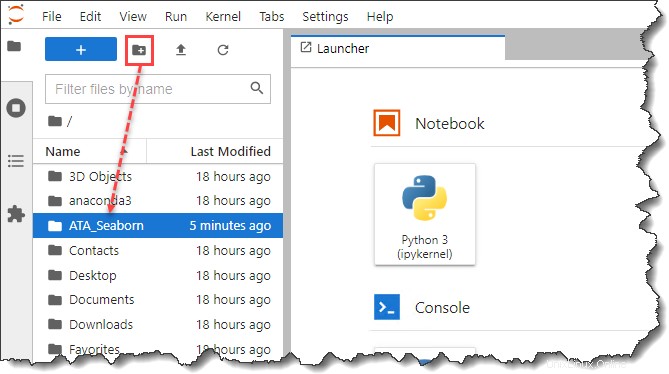
4. Quindi, apri una nuova scheda del browser e scarica il Pokemon set di dati. Assicurati di salvare ata_pokemon.csv file nella directory del progetto che hai creato, che, in questo esempio, è ATA_Seaborn .
5. Di nuovo su JupyterLab, fare doppio clic su ATA_Seaborn cartella. Ora dovresti vedere ata_pokemon.csv sotto quella cartella.
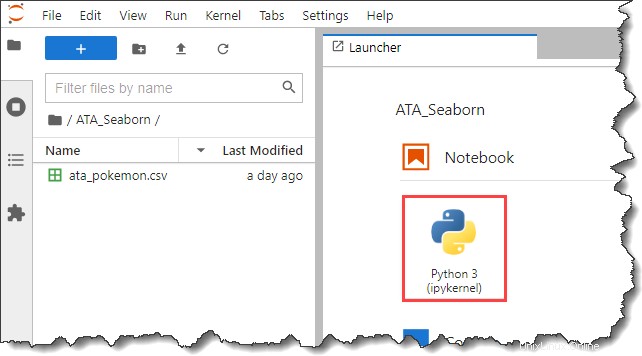
6. Ora, fai clic su Python 3 pulsante sotto il Notebook sezione sul Lancio di avvio scheda per creare un nuovo taccuino.
7. Ora, fai clic sul nuovo taccuino Untitled.ipynb e premi F2 per rinominare il file. Cambia il nome del file in ata_pokemon.ipynb .

8. Quindi, aggiungi un titolo al tuo taccuino. Questo passaggio è facoltativo ma consigliato per rendere più identificabile il tuo progetto.
Sulla barra degli strumenti dei tuoi taccuini, fai clic sul menu a discesa che dice Codice e fai clic su Ribasso.
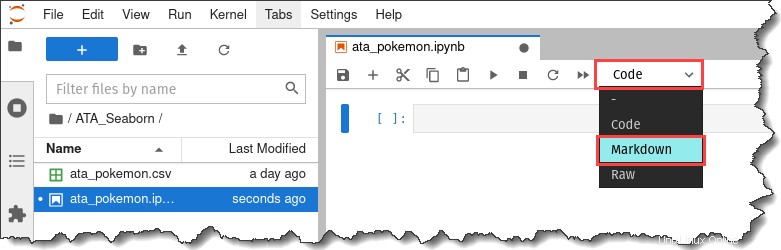
9. Inserisci il testo, "# Visualizzazione dati Pokemon", all'interno della cella markdown e premi i tasti Maiusc + Invio.
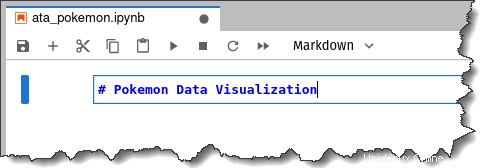
La selezione del tipo di cella cambia automaticamente in Codice e il taccuino avrà il titolo Pokemon Data Visualization in cima.
10. Infine, salva il tuo lavoro premendo i tasti Ctrl + S.
Assicurati di salvare frequentemente il tuo lavoro. Dovresti salvare spesso il tuo lavoro per evitare di perdere qualcosa in caso di problemi con la connessione Internet. Ogni volta che apporti una modifica, premi
CTRL+Sper salvare i tuoi progressi. Puoi anche fare clic sul pulsante Salva sulla barra degli strumenti.
Importazione delle librerie Pandas e Seaborn Python
Il codice Python in genere inizia con l'importazione delle librerie necessarie. E in questo progetto lavorerai con le librerie Pandas e Seaborn Python.
Per importare Pandas e Seaborn, copia il codice qui sotto e incollalo nella cella di comando sul tuo taccuino.
Ricorda questo:per eseguire il codice o i comandi nella cella di comando, premi i tasti Maiusc + Invio.
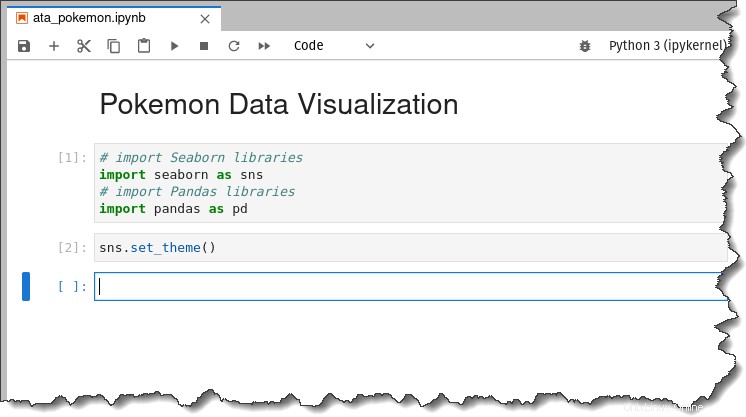
# import Seaborn libraries
import seaborn as sns
# import Pandas libraries
import pandas as pdQuindi, esegui il comando seguente per applicare l'estetica del tema predefinito di Seaborn alle trame che genererai.
sns.set_theme()
Seaborn ha cinque temi integrati disponibili. Sono darkgrid (predefinito), whitegrid , dark , white e ticks .
Importazione del set di dati di esempio
Ora che hai configurato il tuo ambiente JupyterLab, importiamo i dati dal set di dati al tuo ambiente Jupyter.
1. Esegui pd.read_csv() comando nella cella per importare i dati. Il nome del file del dataset deve essere racchiuso tra parentesi per indicare il file da importare racchiuso tra virgolette.
Il comando seguente importerà ata_pokemon.csv e salva il set di dati nel pokemon variabile.
pokemon = pd.read_csv("ata_pokemon.csv")
2. Esegui pokemon.head() comando per visualizzare in anteprima le prime cinque righe del set di dati importato.
pokemon.head()Otterrai il seguente output.
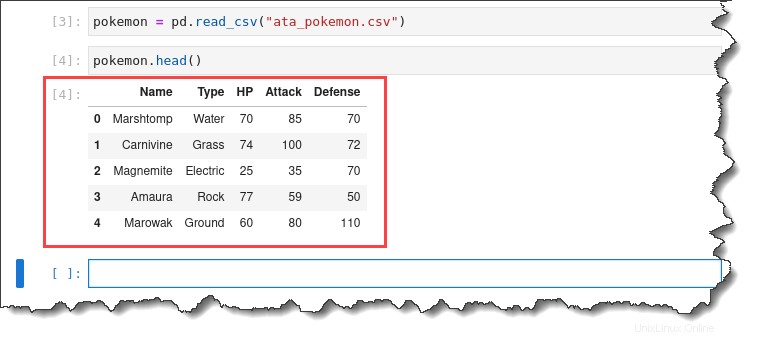
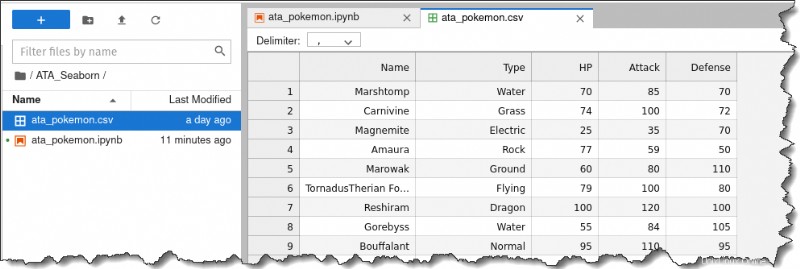
3. Fare doppio clic su ata_pokemon.csv file a sinistra per ispezionare ogni singola riga. Otterrai il seguente output.
Come puoi vedere, è abbastanza comodo lavorare con questo set di dati perché elenca ogni osservazione per riga e tutte le informazioni numeriche sono in colonne separate.
Ora, poniamo alcune domande sul set di dati per aiutare con l'analisi.
- Qual è la relazione tra Attacco e HP?
- Qual è la distribuzione di Attack?
- Qual è la relazione tra Attacco e Tipo?
- Qual è la distribuzione dell'Attacco per ogni Tipo?
- Qual è l'attacco medio o medio per ogni tipo?
- E qual è il conteggio dei Pokemon per ogni Tipo?
Nota che molte di queste domande si concentrano sulle relazioni tra dati numerici e categoriali. Dati categoriali significa dati non numerici, che, in questo set di dati di esempio, sono il tipo di Pokemon.
A differenza di Matplotlib, che è ottimizzato per creare grafici con dati rigorosamente numerici, puoi utilizzare Seaborn per analizzare i dati che contengono sia dati categoriali che numerici.
Creazione di grafici di relazioni
Quindi hai importato un set di dati. Qual è il prossimo? Ora utilizzerai i tuoi dati importati e ne genererai grafici statistici. Iniziamo con la creazione di tracciati relazionali o relazionali per scoprire la relazione tra HP e Attacco dati.
Il tracciamento delle relazioni è pratico quando si identificano possibili relazioni tra le variabili nel set di dati. Seaborn ha due grafici per tracciare le relazioni:grafici a dispersione e grafici a linee.
Tracciamento a linee
La creazione di un grafico lineare richiede di chiamare il Seaborn Python lineplot() funzione. Questa funzione accetta tre parametri:data= , x=' e y=' '.
Copia il comando seguente ed eseguilo nella cella di comando di Jupyter. Questo comando usa il pokemon oggetto come origine dati che hai importato in precedenza, il HP dati della colonna per l'asse x e Attack dati per l'asse y.
sns.lineplot(data=pokemon, x='HP', y='Attack')Come puoi vedere di seguito, il grafico a linee non fa un ottimo lavoro nel mostrarti le informazioni che puoi analizzare rapidamente. Un grafico a linee è migliore per mostrare un asse x che segue una variabile continua come il tempo.
In questo esempio, stai tracciando una variabile discreta HP. Quindi quello che succede è che la trama della linea va dappertutto. Ed è più difficile dedurre una tendenza.
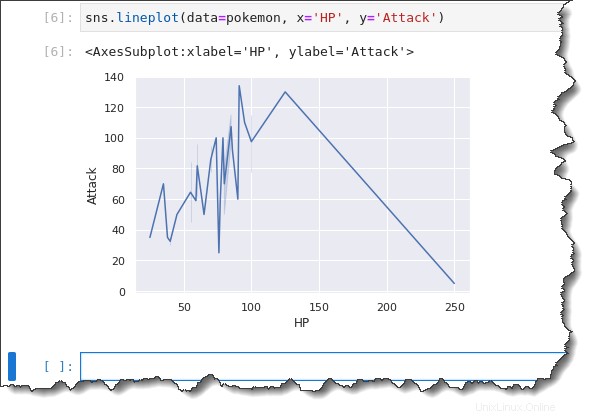
Grafico a dispersione
Una parte dell'analisi esplorativa dei dati consiste nel provare diverse cose per vedere cosa funziona bene. E così facendo, imparerai che alcuni grafici possono mostrarti approfondimenti migliori di altri.
Cosa rende una trama di relazioni migliore dei grafici a linee, quindi? — Grafici a dispersione.
Per creare un grafico a dispersione, chiama la funzione grafico a dispersione, sns.scatterplot e passa tre parametri: data=pokemon , x=HP e y=Attack .
Esegui il comando seguente per creare un grafico a dispersione per il set di dati pokemon.
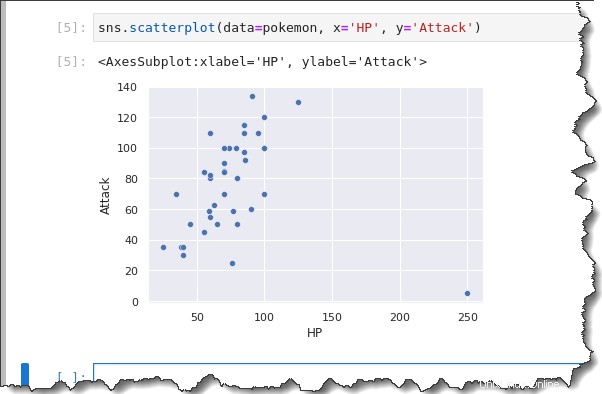
sns.scatterplot(data=pokemon, x='HP', y='Attack')Come puoi vedere nel risultato di seguito, il grafico a dispersione mostra che potrebbe esserci una correlazione positiva generale tra HP (asse x) e Attacco (asse y), con un valore anomalo.
Generalmente, all'aumentare degli HP, aumenta anche l'Attacco. I Pokemon con punti salute maggiori tendono ad essere più forti.
Tracciamento a dispersione con leggende
Sebbene il grafico a dispersione presentasse già una visualizzazione dei dati più sensata, puoi ancora migliorare ulteriormente il grafico scomponendo la distribuzione del tipo con una legenda.
Esegui il sns.scatterplot() funzione di nuovo nell'esempio seguente. Ma questa volta, aggiungi il hue='Type' parola chiave, che creerà una legenda che mostra i diversi tipi di Pokemon. Di nuovo nella scheda del tuo taccuino Jupyter, esegui il comando seguente.
sns.scatterplot(data=pokemon, x='HP', y='Attack', hue='Type')Nota sul risultato di seguito, il grafico a dispersione ora ha colori diversi. Analizzare gli aspetti categoriali dei tuoi dati ora è molto meglio grazie alle distinzioni visive fornite dalla legenda.
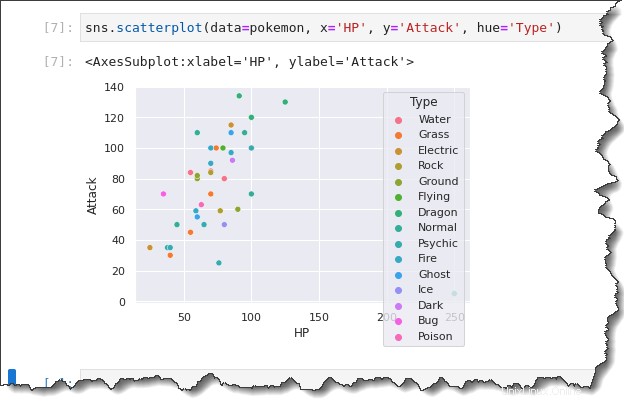
La cosa ancora migliore è che puoi ancora scomporre ulteriormente la trama usando il sns.relplot() funzione con il col=Type e col_wrap argomenti delle parole chiave.
Esegui il comando seguente in Jupyter per creare una trama per ciascun tipo di Pokemon in un formato di griglie a trama multipla.
sns.relplot(data=pokemon, x='HP', y='Attack', hue='Type', col='Type', col_wrap=3)Osservando il risultato di seguito, puoi dedurre che HP e Attack sono generalmente correlati in qualche modo positivamente. I Pokémon con più HP tendono ad essere più forti.
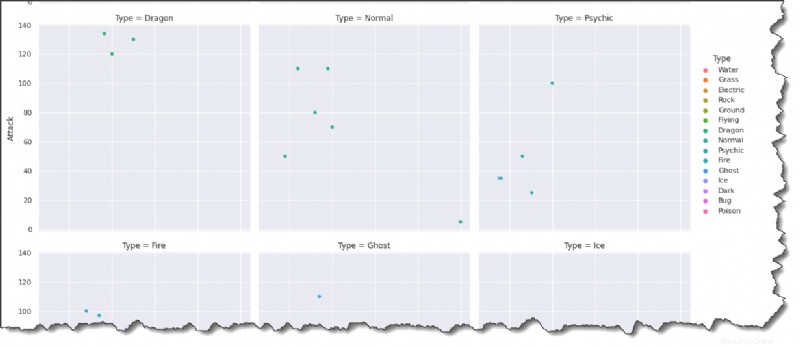
Sei d'accordo sul fatto che l'aggiunta di colori e legende renda la trama più interessante?
Creazione di grafici di distribuzione
Nella sezione precedente, hai creato un grafico a dispersione. Questa volta, utilizziamo un diagramma di distribuzione per ottenere informazioni dettagliate sulla distribuzione di Attacco e HP per ciascun tipo di Pokemon.
Tracciatura dell'istogramma
È possibile utilizzare l'istogramma per visualizzare la distribuzione di una variabile. Nel tuo set di dati di esempio, la variabile è l'Attacco del Pokemon.
Per creare un grafico dell'istogramma, esegui sns.histplot() funzione sottostante. Questa funzione accetta due parametri:data=pokemon e x='Attack' . Copia il comando seguente ed eseguilo in Jupyter.
sns.histplot(data=pokemon, x='Attack')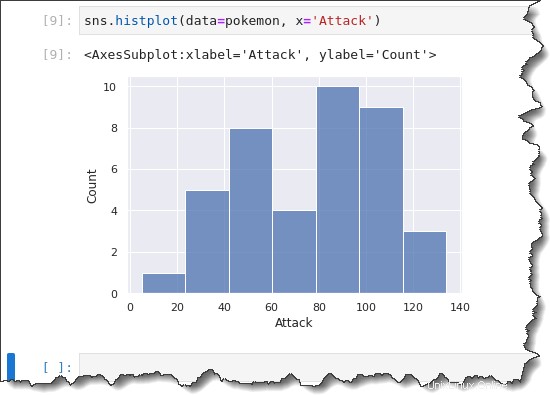
Durante la creazione di un istogramma, Seaborn seleziona automaticamente una dimensione ottimale del contenitore per te. Potresti voler cambiare la dimensione del contenitore per osservare la distribuzione dei dati in raggruppamenti di forma diversa.
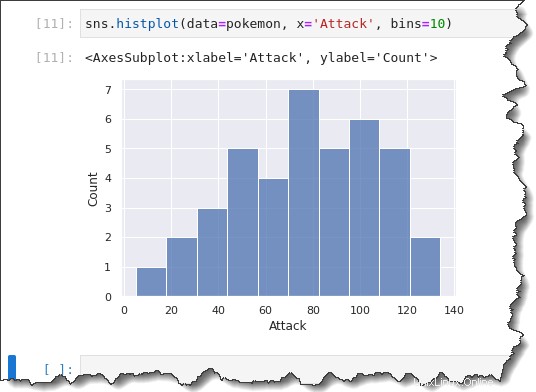
Per specificare una dimensione del raccoglitore fissa o personalizzata, aggiungi il bins=x argomento del comando dove x è la dimensione del contenitore personalizzato. Esegui il comando seguente per creare un istogramma con una dimensione bin di 10.
sns.histplot(data=pokemon, x='Attack', bins=10)Nell'istogramma precedente che hai generato, il Pokemon Attack sembra avere una distribuzione bimodale (due grandi gobbe.)
Ma quando guardi la dimensione del tuo cestino di 10, i raggruppamenti vengono suddivisi in modo più segmentato. Puoi vedere che c'è più di una distribuzione unimodale, con un'inclinazione verso destra.
Tracciamento della stima della densità del kernel (KDE)
Un altro modo per visualizzare la distribuzione è con il tracciamento della stima della densità del kernel. KDE è essenzialmente come un istogramma ma con curve invece di colonne.
Il vantaggio dell'utilizzo di un grafico di KDE è che puoi fare inferenze più rapide su come i dati sono distribuiti grazie alla curva di probabilità, mostrando caratteristiche come tendenza centrale, modalità e inclinazione.
Per creare una trama di KDE, chiama il sns.kdeplot() funzione e passare lo stesso data=pokemon , x='Attack' come argomenti. Esegui il codice qui sotto in Jupyter per vedere la trama di KDE in azione.
sns.kdeplot(data=pokemon, x='Attack')Come puoi vedere di seguito, la trama di KDE è simile nell'inclinazione all'istogramma con una dimensione del contenitore di 10.
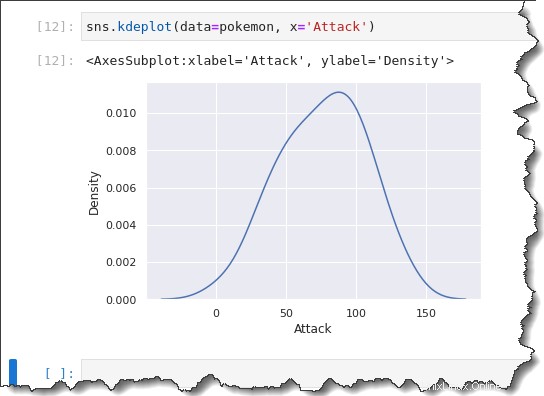
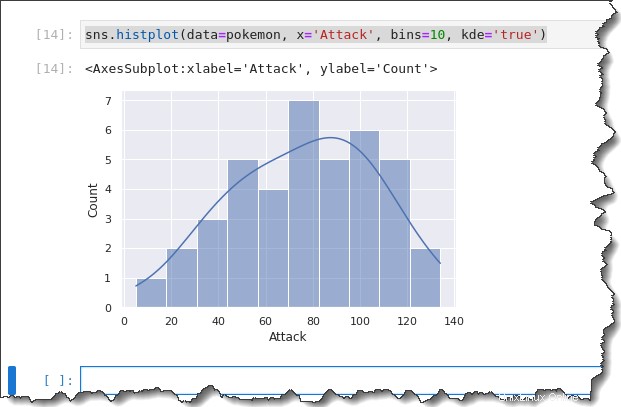
Poiché l'istogramma e KDE sono simili, perché non usarli insieme? Seaborn ti consente di sovrapporre KDE a un istogramma aggiungendo la parola chiave kde='true' argomento al comando precedente, come puoi vedere di seguito.
sns.histplot(data=pokemon, x='Attack', bins=10, kde='true')Otterrai il seguente output. Secondo l'istogramma sottostante, la maggior parte dei Pokemon ha un punto di attacco distribuito tra 50 e 120. Non è una bella diffusione!
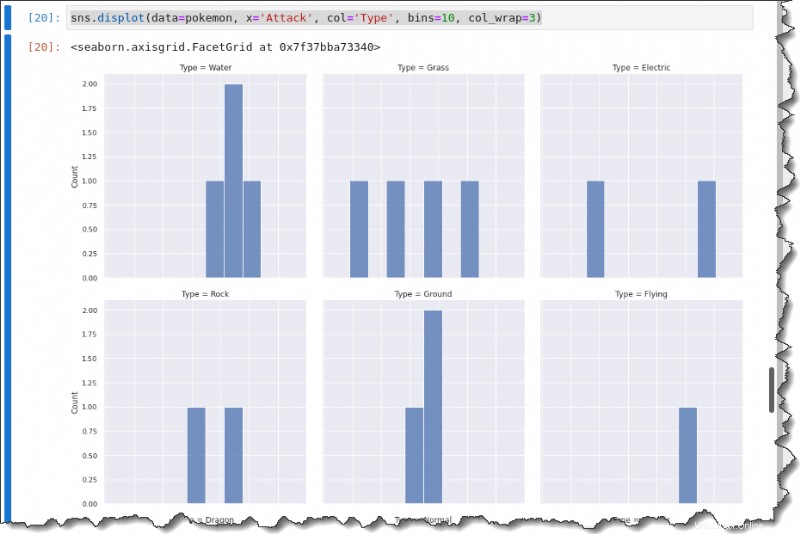
Per suddividere ogni distribuzione di attacco per Tipo, chiama il displot() funzione con il col parola chiave di seguito per creare un grafico multi-griglia che mostri ciascun tipo.
sns.displot(data=pokemon, x='Attack', col='Type', bins=10, col_wrap=3)Otterrai il seguente output.
Generazione di grafici categoriali
È bello creare istogrammi separati in base alla categoria del tipo. Tuttavia, gli istogrammi potrebbero non fornire un'immagine chiara per te. Usiamo quindi alcune delle trame categoriche di Seaborn per aiutarti ad approfondire l'analisi dei dati degli attacchi in base ai tipi di Pokemon.
Strip plotting
Nei precedenti grafici a dispersione e istogrammi, hai provato a visualizzare i dati dell'Attacco secondo una variabile categoriale (Type ). Questa volta creerai una trama a strisce, una serie di grafici a dispersione raggruppati per categoria.
Per creare il tuo tracciato a strisce categoriali, chiama il sns.stripplot() funzione e passare tre argomenti:data=pokemon , x='Type' e y='Attack' . Esegui il codice seguente in Jupyter per generare il grafico a strisce categoriale.
sns.stripplot(data=pokemon, x='Type', y='Attack')Ora hai un grafico a strisce con tutte le osservazioni raggruppate per Tipo. Ma hai notato come le etichette dell'asse x sono tutte schiacciate insieme? Non è così utile, vero?
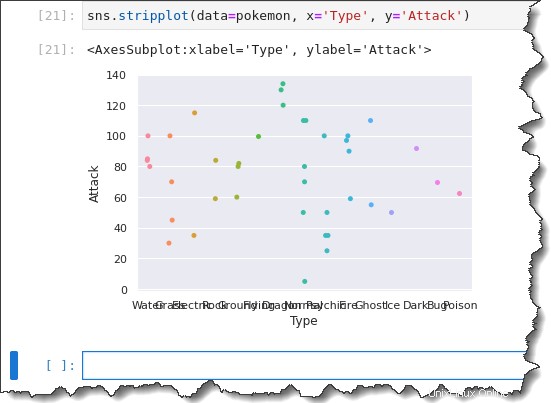
Per correggere le etichette dell'asse x, devi utilizzare una funzione diversa chiamata catplot() .
Nella cella di comando del tuo notebook Jupyter, esegui sns.catplot() funzione e passare cinque argomentikind='strip' , data=pokemon , x='Type' , y='Attack' e aspect=2 , come mostrato di seguito.
sns.catplot(kind='strip', data=pokemon, x='Type', y='Attack', aspect=2)Questa volta, il pot risultante mostra le etichette dell'asse x a tutta larghezza, rendendo la tua analisi più comoda.
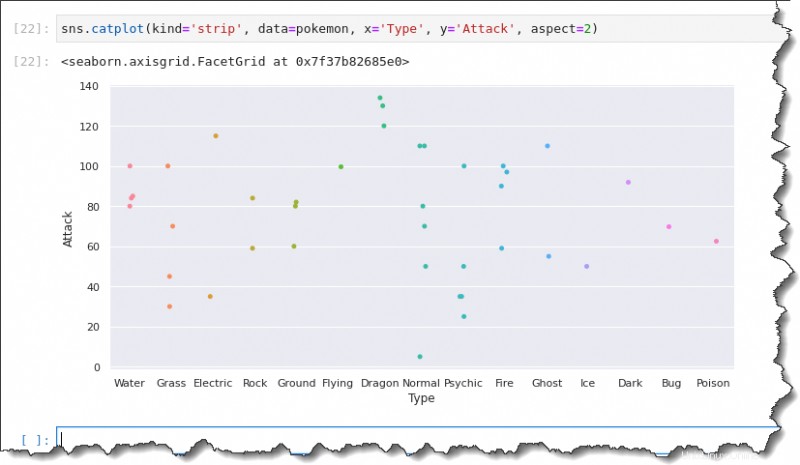
Box plotting
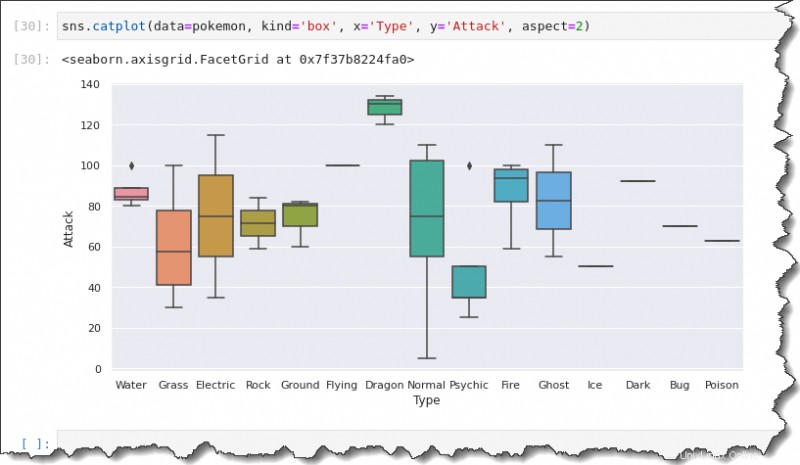
Il catplot() La funzione ha un'altra sottofamiglia di grafici che ti aiuterà a visualizzare la distribuzione dei dati con una variabile categoriale. Uno di questi è il box plot.
Per creare un box plot, esegui sns.catplot() funzione con i seguenti argomenti:data=pokemon , kind='box' , x='Type' , y='Attack' e aspect=2 .
Il aspect argomento controlla la spaziatura tra le etichette dell'asse x. Un valore più alto significa uno spread più ampio.
sns.catplot(data=pokemon, kind='box', x='Type', y='Attack', aspect=2)
Questo output fornisce un riepilogo della diffusione dei dati. Usando il catplot() funzione, puoi ottenere la diffusione dei dati per ogni tipo di Pokemon su una trama.
Si noti che gli indicatori di diamante nero rappresentano valori anomali. Invece di un box plot, una linea nel mezzo significa che c'è solo un'osservazione per quel tipo di Pokemon.
Hai un riepilogo di cinque numeri per ciascuno di questi grafici a scatola e baffi. La linea al centro del riquadro rappresenta il valore mediano o la loro tendenza centrale dei punti Attacco.
Hai anche il primo e il terzo quartile e i baffi, che rappresentano i valori massimo e minimo.
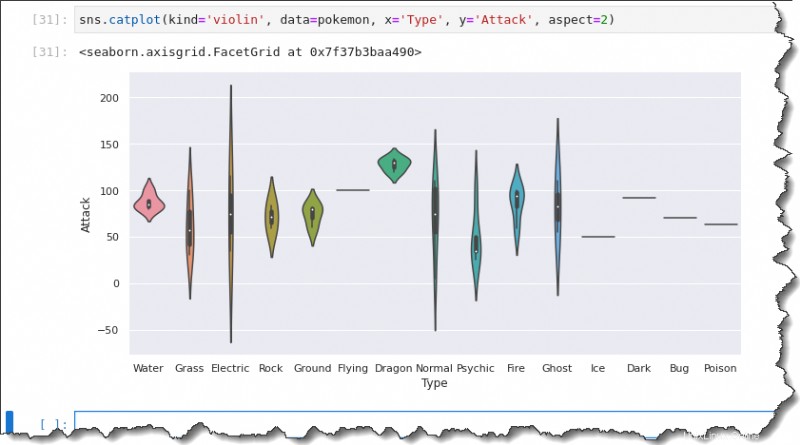
Tracciatura del violino
Un altro modo per visualizzare la distribuzione è utilizzare la trama del violino. La trama del violino è come un box plot e un mix di KDE. Le trame del violino sono analoghe alle trame a scatola.
Per creare una trama per violino, sostituisci kind valore a violin , mentre il resto è lo stesso di quando hai eseguito il comando box plotting. Esegui il codice seguente per creare una trama di violino.
sns.catplot(kind='violin', data=pokemon, x='Type', y='Attack', aspect=2)Di conseguenza, puoi vedere che la trama del violino include la mediana, il primo e il terzo quartile. Il grafico del violino fornisce un riepilogo simile dei dati diffusi nel box plot.
Rivisitazione della domanda:qual è la distribuzione degli attacchi per ogni tipo di Pokemon?
Il box plot mostra i punti di attacco minimi sono compresi tra 0 e 10, mentre il massimo sale a 110.
I punti di attacco mediani per i Pokemon di tipo normale sembrano essere circa 75. Il primo e il terzo quartile sembrano essere circa 55 e 105.
Tracciatura a barre
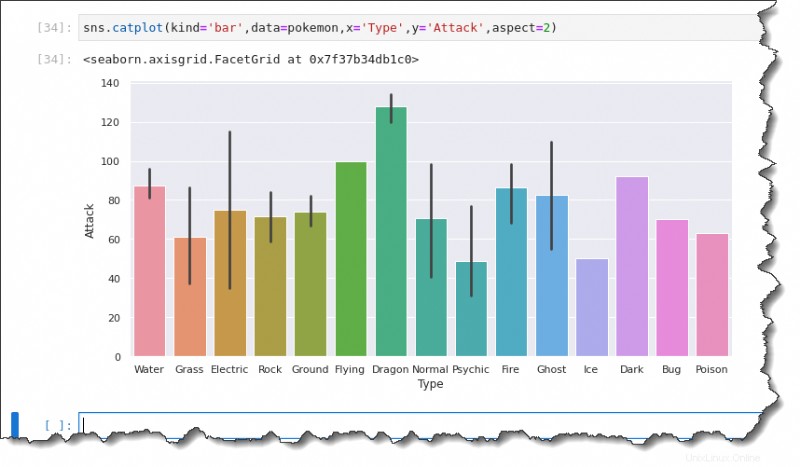
Il grafico a barre è un membro della famiglia di stima categoriale di Seaborn che mostra i valori medi o medi di ciascuna categoria di dati.
Per creare un grafico a barre, esegui sns.catplot() funzione in Jupyter e specificare sei argomenti:kind='bar' , data=pokemon , x='Type' , y='Attack' e aspect=2 , come mostrato di seguito.
sns.catplot(kind='bar',data=pokemon,x='Type',y='Attack',aspect=2)Le linee nere su ciascuna barra sono barre di errore che rappresentano l'incertezza, come i valori anomali nelle osservazioni. Come puoi vedere di seguito, i valori medi sono:
- Circa 90 per i Pokémon di tipo Acqua.
- Circa 60 per Erba .
- Elettrico è approssimativamente a 75.
- Roccia forse 70.
- Il terreno entro 75.
- E così via.
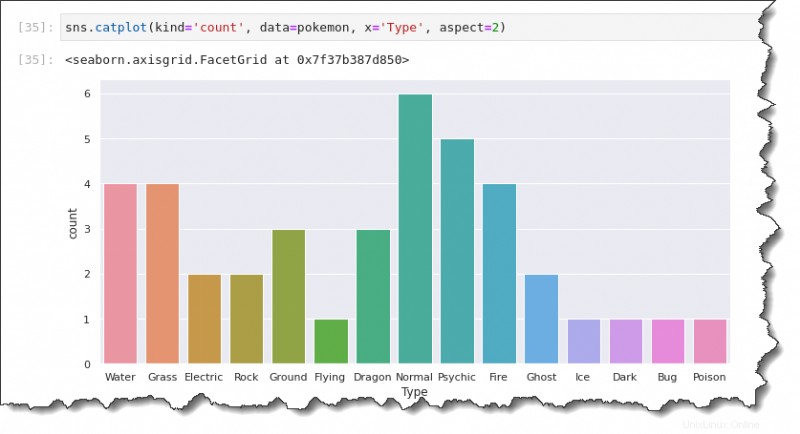
Tracciamento del conteggio
E se volessi tracciare il conteggio dei Pokemon invece dei dati medi/medi? Il diagramma di conteggio ti consentirà di farlo con la libreria Python di Seaborn.
Per generare un grafico di conteggio, sostituisci kind valore con count , come mostrato nel codice sottostante. A differenza del grafico a barre, il grafico del conteggio necessita solo di un asse dati. A seconda dell'orientamento del grafico che desideri creare, specifica solo l'asse x o solo l'asse y.
Il comando seguente crea il grafico del conteggio che mostra la variabile di tipo sull'asse x.
sns.catplot(kind='count', data=pokemon, x='Type', aspect=2)Avrai un diagramma di conteggio simile a quello qui sotto. Come puoi vedere, i tipi più comuni di Pokemon sono:
- Normale (6).
- Psichico (5).
- Acqua (4).
- Erba (4).
- E così via.
Conclusione
In questo tutorial, hai imparato come creare grafici statistici a livello di codice con la libreria Seaborn Python. Quale metodo di stampa ritieni più appropriato per il tuo set di dati?
Ora che hai lavorato sugli esempi e fatto pratica nella creazione di trame con Seaborn, perché non iniziare a lavorare su nuove trame da solo. Forse puoi iniziare con il set di dati Iris o raccogliere i tuoi dati di esempio?
E già che ci sei, prova anche alcuni degli altri modelli e tavolozze di colori integrati di Seaborn! Grazie per la lettura e buon divertimento!