Ricerca elastica è un motore di ricerca e analisi full-text open source altamente scalabile . In genere è il motore/la tecnologia sottostante che alimenta le applicazioni con caratteristiche e requisiti di ricerca complessi. Il software supporta operazioni RESTful che consentono di archiviare, cercare e analizzare volumi significativi di dati in modo rapido e quasi in tempo reale. Elasticsearch è apprezzato e popolare tra gli amministratori di sistema e gli sviluppatori in quanto è un potente motore di ricerca basato sulla libreria Lucene.
Nel seguente tutorial imparerai come installare Elastic Search su openSUSE Leap 15 .
Prerequisiti
- Sistema operativo consigliato: openSUSE Leap – 15.x
- Account utente: Un account utente con accesso sudo o root.
Aggiorna sistema operativo
Aggiorna il tuo openSUSE sistema operativo per assicurarsi che tutti i pacchetti esistenti siano aggiornati:
sudo zypper refreshIl tutorial utilizzerà il comando sudo e supponendo che tu abbia lo stato sudo .
Per verificare lo stato di sudo sul tuo account:
sudo whoamiEsempio di output che mostra lo stato di sudo:
[joshua@opensuse ~]$ sudo whoami
rootPer configurare un account sudo esistente o nuovo, visita il nostro tutorial su aggiungere un utente ai sudoer su openSUSE .
Per utilizzare l'account root , usa il comando seguente con la password di root per accedere.
suInstalla pacchetto CURL
Il CURL comando è necessario per alcune parti di questa guida. Per installare questo pacchetto, digita il seguente comando:
sudo zyper install curlInstalla pacchetto Java
Per installare correttamente e, soprattutto, utilizzare Elasticsearch , devi installare Java . Il processo è relativamente semplice.
Digita il seguente comando per installare OpenJDK pacchetto:
sudo zypper install java-11-openjdk-develInstalla Elasticsearch
Ricerca elastica non è disponibile nel repository standard di openSUSE , quindi devi installarlo dal repository Elasticsearch .
Prima di aggiungere il repository, importa la chiave GPG con il seguente comando:
sudo rpm --import https://artifacts.elastic.co/GPG-KEY-elasticsearchIl passaggio successivo consiste nel creare un file repo Elasticsearch come segue:
sudo zypper ar https://artifacts.elastic.co/packages/7.x/yum elasticsearchOra installa Elasticsearch usando il seguente comando:
sudo zypper install elasticsearchEsempio di output:
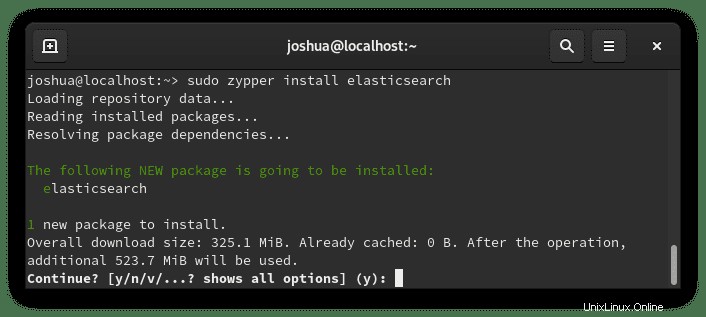
Digita "Y" quindi premere il "INVIO TASTO" per procedere con l'installazione
Per abilitare Elasticsearch per essere abilitato per impostazione predefinita, dovrai installare il pacchetto insserv .
sudo zypper install insservPer impostazione predefinita, il servizio Elasticsearch è disabilitato all'avvio e non attivo. Per avviare il servizio e abilitarlo all'avvio del sistema, digita il seguente (systemctl) comando:
sudo systemctl enable elasticsearch.service --nowEsempio di output:
Synchronizing state of elasticsearch.service with SysV service script with /usr/lib/systemd/systemd-sysv-install.
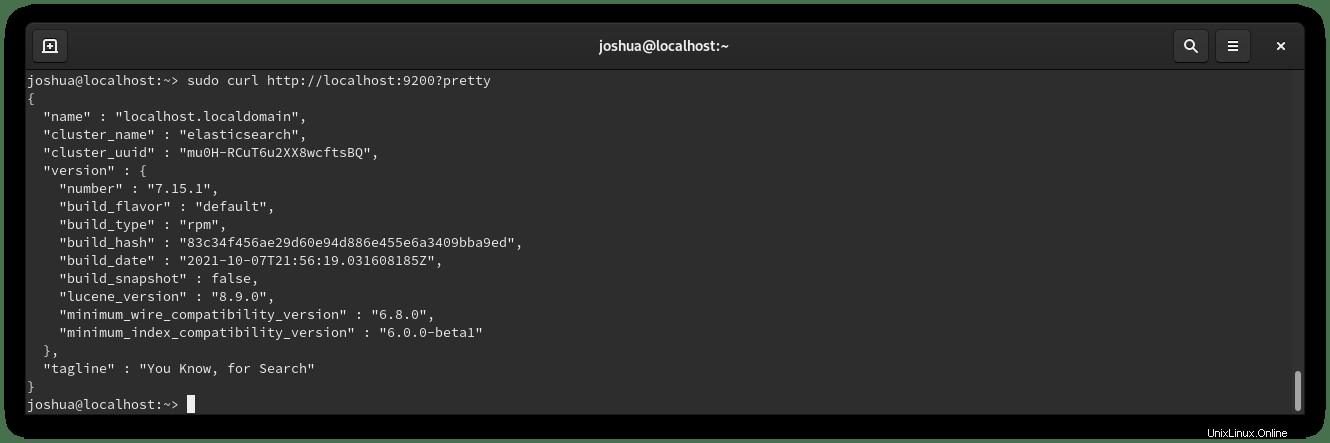
Executing: /usr/lib/systemd/systemd-sysv-install enable elasticsearchVerifica che Elasticsearch funzioni correttamente utilizzando il comando curl per inviare una richiesta HTTP alla porta 9200 su localhost come segue:
sudo curl http://localhost:9200?prettyEsempio di output:
Come configurare Elasticsearch
I dati di Elasticsearch vengono archiviati nella posizione della directory predefinita (/var/lib/elasticsearch) . Per visualizzare o modificare i file di configurazione, puoi trovarli nella posizione della directory (/etc/elasticsearch) e le opzioni di avvio di java possono essere configurate in (/etc/default/elasticsearch) file di configurazione.
Le impostazioni predefinite vanno bene principalmente per i singoli server operativi poiché Elasticsearch viene eseguito su localhost solo. Tuttavia, se intendi configurare un cluster, dovrai modificare il file di configurazione per consentire le connessioni remote.
Imposta l'accesso remoto (opzionale)
Per impostazione predefinita, Elasticsearch ascolta solo localhost. Per cambiarlo, apri il file di configurazione come segue:
sudo nano /etc/elasticsearch/elasticsearch.ymlScorri verso il basso fino alla riga 56 e trova la sezione Rete e decommenta (#) la riga seguente e sostituirlo con l'indirizzo IP privato interno o l'indirizzo IP esterno come segue:
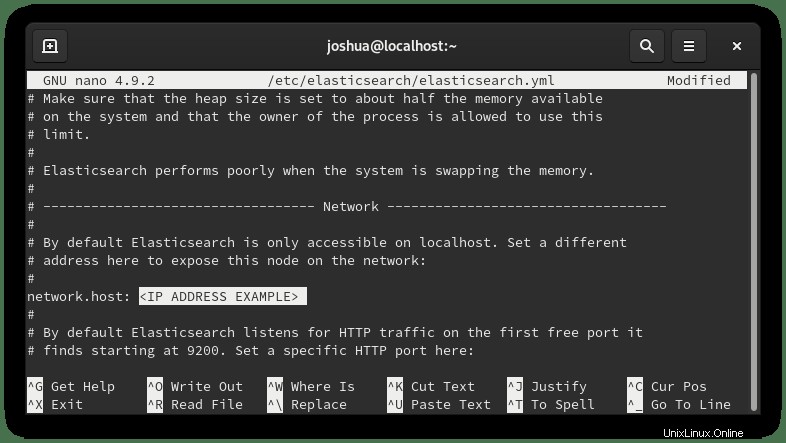
Nell'esempio, abbiamo decommentato (#) il (network.host) e l'ho cambiato in un indirizzo IP privato interno come sopra.
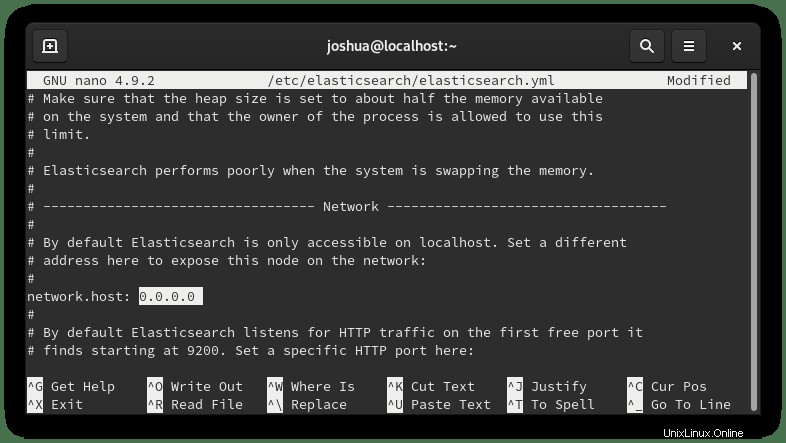
Per motivi di sicurezza, è ideale per specificare gli indirizzi; tuttavia, se hai più indirizzi IP interni o esterni che colpiscono il server, cambia l'interfaccia di rete per ascoltarli tutti inserendo (0.0.0.0) come segue:
Salva il file di configurazione (CTRL+O), quindi esci da (CLTR+X) .
Affinché le modifiche abbiano effetto, dovrai riavviare il servizio Elasticsearch con il seguente comando:
sudo systemctl restart elasticsearchConfigura Firewalld per Elasticsearch
Per impostazione predefinita, non sono impostate regole per Elasticsearch, il che può causare problemi in futuro.
Innanzitutto, aggiungi una nuova zona dedicata per la policy firewalld di Elasticsearch:
sudo firewall-cmd --permanent --new-zone=elasticsearchQuindi, specifica gli indirizzi IP consentiti a cui è consentito accedere a Memcached.
sudo firewall-cmd --permanent --zone=elasticsearch --add-source=1.2.3.4Sostituisci 1.2.3.4 con l'IP indirizzo che verrà aggiunto all'elenco di autorizzazioni.
Una volta terminata l'aggiunta degli indirizzi IP, apri la porta del Memcached.
Ad esempio, porta TCP 11211 .
sudo firewall-cmd --permanent --zone=elasticsearch --add-port=9200/tcpNota, puoi modificare la porta predefinita nel file di configurazione se modifichi la regola di apertura della porta del firewall sopra al nuovo valore.
Dopo aver eseguito questi comandi, ricarica il firewall per implementare le nuove regole:
sudo firewall-cmd --reloadEsempio di output in caso di successo:
successCome utilizzare Elasticsearch
Per utilizzare Elasticsearch utilizzando il comando curl è un processo semplice. Di seguito sono riportati alcuni dei più comunemente utilizzati:
Elimina indice
Sotto l'indice è denominato campioni .
curl -X DELETE 'http://localhost:9200/samples'Elenca tutti gli indici
curl -X GET 'http://localhost:9200/_cat/indices?v'Elenca tutti i documenti nell'indice
curl -X GET 'http://localhost:9200/sample/_search'Query utilizzando i parametri URL
Qui utilizziamo il formato di query Lucene per scrivere q=school:Harvard.
curl -X GET http://localhost:9200/samples/_search?q=school:HarvardQuery con JSON alias Elasticsearch Query DSL
È possibile eseguire query utilizzando i parametri nell'URL. Ma puoi anche usare JSON, come mostrato nell'esempio seguente. JSON sarebbe più facile da leggere ed eseguire il debug quando si dispone di una query complessa rispetto a una stringa gigante di parametri URL.
curl -XGET --header 'Content-Type: application/json' http://localhost:9200/samples/_search -d '{
"query" : {
"match" : { "school": "Harvard" }
}
}'Mappatura dell'indice dell'elenco
Tutti i campi Elasticsearch sono indici. Quindi questo elenca tutti i campi e i loro tipi in un indice.
curl -X GET http://localhost:9200/samplesAggiungi dati
curl -XPUT --header 'Content-Type: application/json' http://localhost:9200/samples/_doc/1 -d '{
"school" : "Harvard"
}'Aggiorna documento
Ecco come aggiungere campi a un documento esistente. Per prima cosa, ne creiamo uno nuovo. Quindi lo aggiorniamo.
curl -XPUT --header 'Content-Type: application/json' http://localhost:9200/samples/_doc/2 -d '
{
"school": "Clemson"
}'
curl -XPOST --header 'Content-Type: application/json' http://localhost:9200/samples/_doc/2/_update -d '{
"doc" : {
"students": 50000}
}'Indice di backup
curl -XPOST --header 'Content-Type: application/json' http://localhost:9200/_reindex -d '{
"source": {
"index": "samples"
},
"dest": {
"index": "samples_backup"
}
}'
Carica in blocco i dati in formato JSON
export pwd="elastic:"
curl --user $pwd -H 'Content-Type: application/x-ndjson' -XPOST 'https://58571402f5464923883e7be42a037917.eu-central-1.aws.cloud.es.io:9243/0/_bulk?pretty' --data-binary @<file>Mostra stato del cluster
curl --user $pwd -H 'Content-Type: application/json' -XGET https://58571402f5464923883e7be42a037917.eu-central-1.aws.cloud.es.io:9243/_cluster/health?prettyAggregazione e aggregazione bucket
Per un server web Nginx, questo produce un numero di visite web per città dell'utente:
curl -XGET --user $pwd --header 'Content-Type: application/json' https://58571402f5464923883e7be42a037917.eu-central-1.aws.cloud.es.io:9243/logstash/_search?pretty -d '{
"aggs": {
"cityName": {
"terms": {
"field": "geoip.city_name.keyword",
"size": 50
}
}
}
}
'Questo lo espande al conteggio del codice di risposta del prodotto della città in un registro del server Web Nginx
curl -XGET --user $pwd --header 'Content-Type: application/json' https://58571402f5464923883e7be42a037917.eu-central-1.aws.cloud.es.io:9243/logstash/_search?pretty -d '{
"aggs": {
"city": {
"terms": {
"field": "geoip.city_name.keyword"
},
"aggs": {
"responses": {
"terms": {
"field": "response"
}
}
}
},
"responses": {
"terms": {
"field": "response"
}
}
}
}'Utilizzo di ElasticSearch con l'autenticazione di base
Se hai attivato la sicurezza con ElasticSearch, devi fornire l'utente e la password come mostrato di seguito per ogni comando curl:
curl -X GET 'http://localhost:9200/_cat/indices?v' -u elastic:(password)Bella stampa
Aggiungi ?pretty=true a qualsiasi ricerca per stampare in modo grazioso il JSON. In questo modo:
curl -X GET 'http://localhost:9200/(index)/_search'?pretty=truePer interrogare e restituire solo determinati campi
Per restituire solo determinati campi, inseriscili nell'array _source:
GET filebeat-7.6.2-2020.05.05-000001/_search
{
"_source": ["suricata.eve.timestamp","source.geo.region_name","event.created"],
"query": {
"match" : { "source.geo.country_iso_code": "GR" }
}
}Per interrogare per data
Quando il campo è di tipo data, puoi utilizzare la matematica della data, in questo modo:
GET filebeat-7.6.2-2020.05.05-000001/_search
{
"query": {
"range" : {
"event.created": {
"gte" : "now-7d/d"
}
}
}
}Come rimuovere (disinstallare) Elasticsearch
Se non hai più bisogno di Elasticsearch, puoi rimuovere il software con il seguente comando:
sudo zypper remove elasticsearchEsempio di output:
Digita "Y" quindi premere il "INVIO TASTO" per procedere con la rimozione di Elasticsearch.