Dal nome implica, il comando head mostra per impostazione predefinita le 10 righe superiori di un file. Questo comando può essere inviato tramite pipe con altri comandi per produrre output standard. Il comando head è un'utilità della riga di comando attraverso la quale puoi facilmente recuperare i dati principali da un file specificato e mostrare il risultato allo standard output.
Spiegheremo in questo tutorial come utilizzare il comando head, un'utilità della riga di comando su un sistema Linux. Spiegheremo le opzioni dei comandi principali con brevi esempi.
Sintassi del comando principale
Il comando head ha la seguente sintassi:
head <options> <filename>
Opzioni: Le opzioni Head vengono utilizzate per specificare l'azione che l'azione esegue su un file. Ad esempio, usa l'opzione -n per specificare il numero di riga.
Nome file: puoi specificare uno o più nomi di file come input usando questo argomento. Se non menzioni il nome di un file, legge l'input grezzo standard.
Uso del comando principale con esempi
Discuteremo i seguenti diversi usi del comando head in questo articolo:
Utilizzo del comando Head senza opzione
Quando il comando head viene utilizzato con il nome del file senza alcuna opzione, in tal caso restituisce le prime 10 righe di un determinato file come segue:
$ head filename.txt
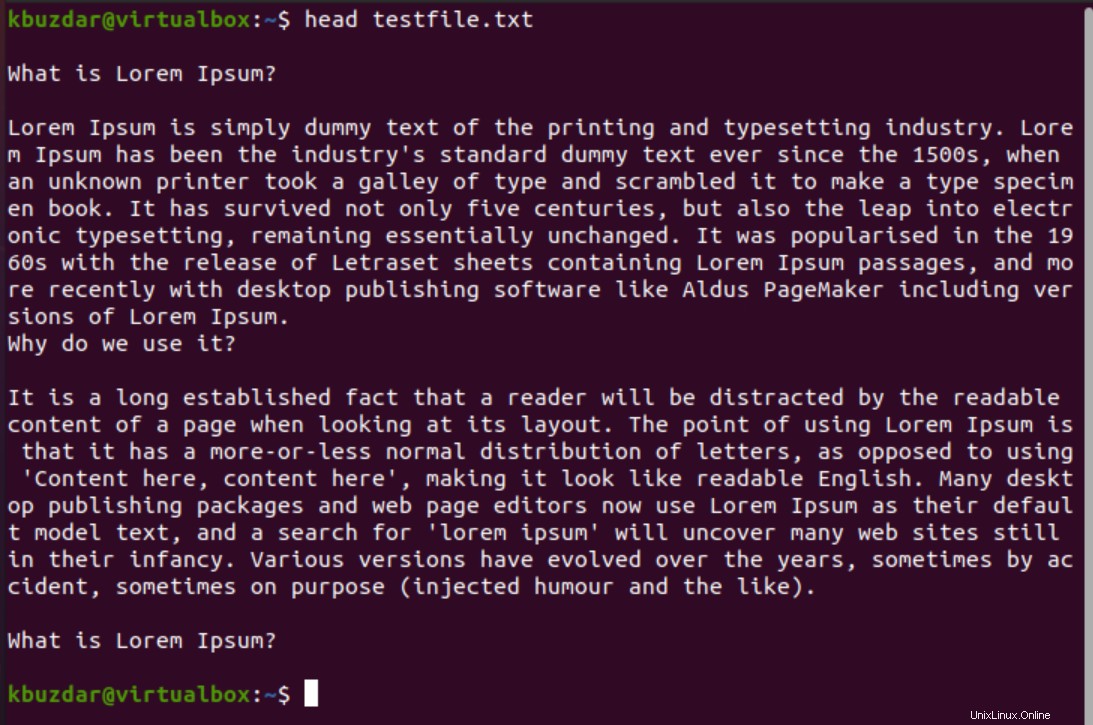
Ad esempio, usando il comando head vogliamo recuperare le prime 10 righe dal nostro file di prova.
$ head testfile.txt
Sul terminale ritorna il seguente output:
Stampa le righe specificate usando il comando head
Usando l'opzione -n (–linee) insieme al numero intero specificato, puoi visualizzare il numero desiderato di righe da un file come segue:
$ head -n <integer> filename.txt
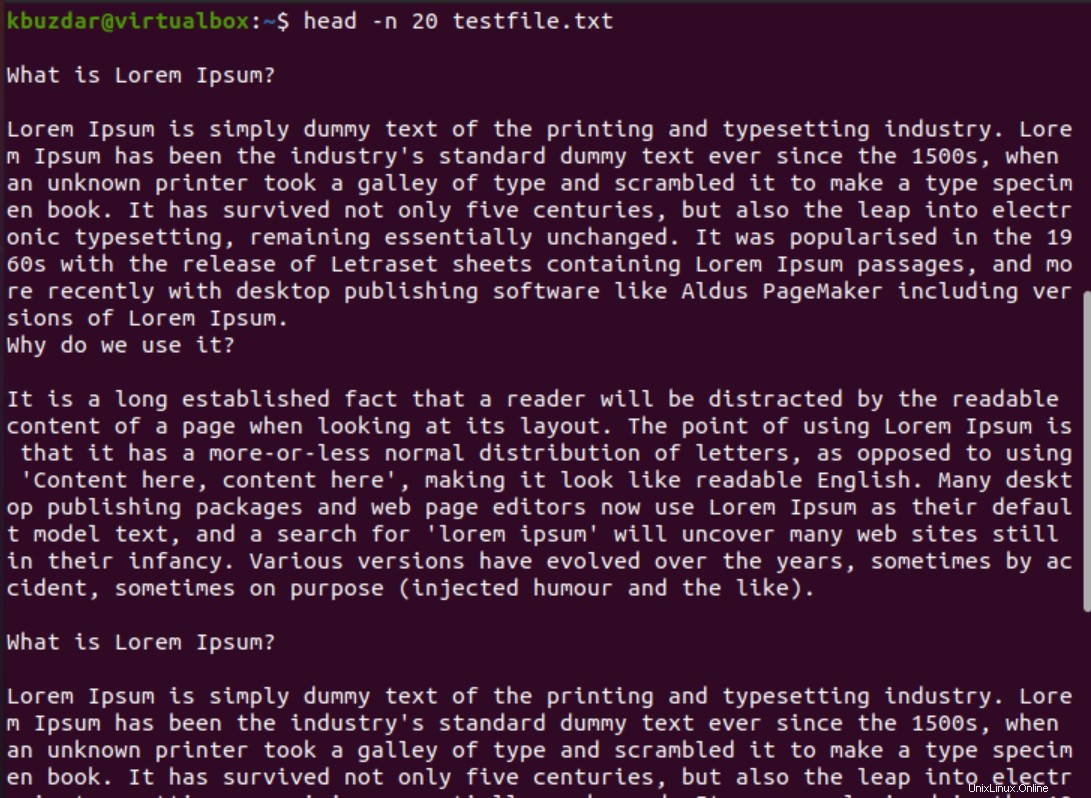
Ad esempio, si desidera stampare le prime 20 righe di un file. In questo caso, menzioneresti 20 con l'opzione n come segue:
$ head -n 20 testfile.txt
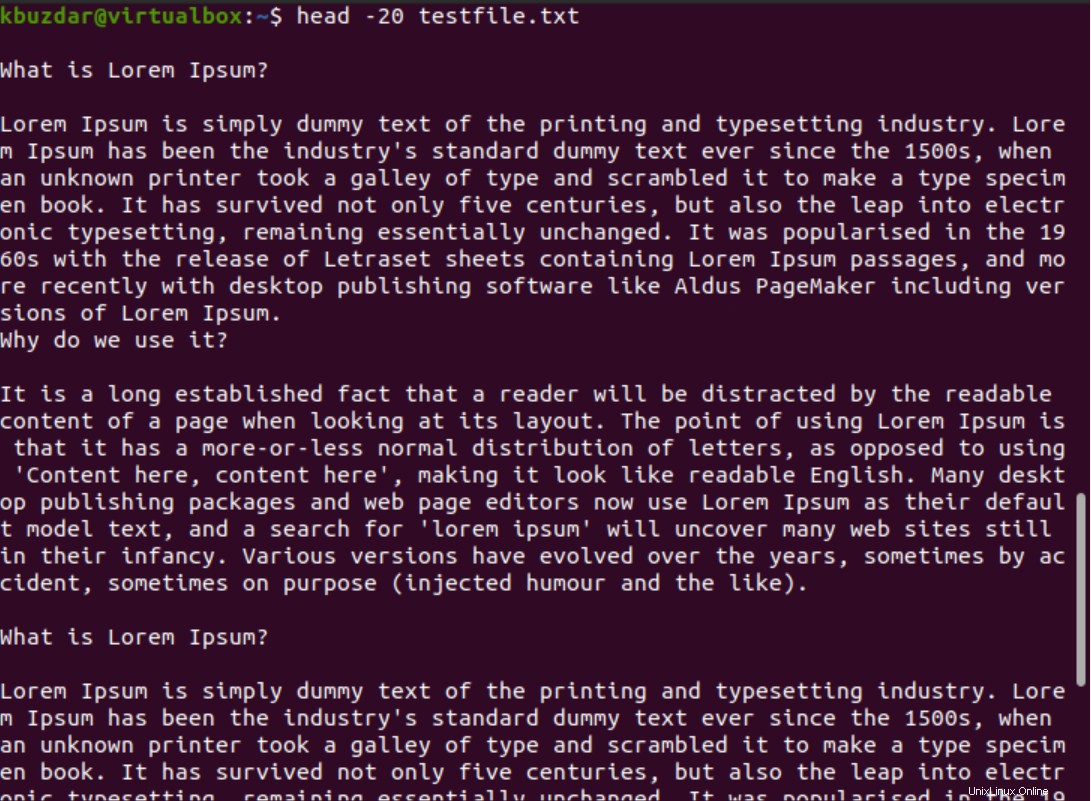
Puoi anche omettere l'opzione n dal comando precedente e menzionare semplicemente il numero intero con un trattino come segue:
$ head -20 testfile.txt
Stampa i byte specificati usando il comando head
Puoi anche stampare il numero specificato di byte di un file usando l'opzione '-c' insieme al comando head come segue:
$ head -c <integer> filename.txt
Spieghiamo con un esempio, per stampare i primi 200 byte di dati da un file tramite il comando head. Dovresti eseguire il seguente comando:
$ head -c 200 testfile.txt

Il suffisso del moltiplicatore può anche specificare di visualizzare i byte. Ad esempio,
Puoi utilizzare i seguenti moltiplicatori con un numero intero di byte specificato:
- b moltiplica per 512.
- kB moltiplicato per 1000
- K moltiplicato per 1024
- MB moltiplicati per 1000000
- M moltiplica per 1048576
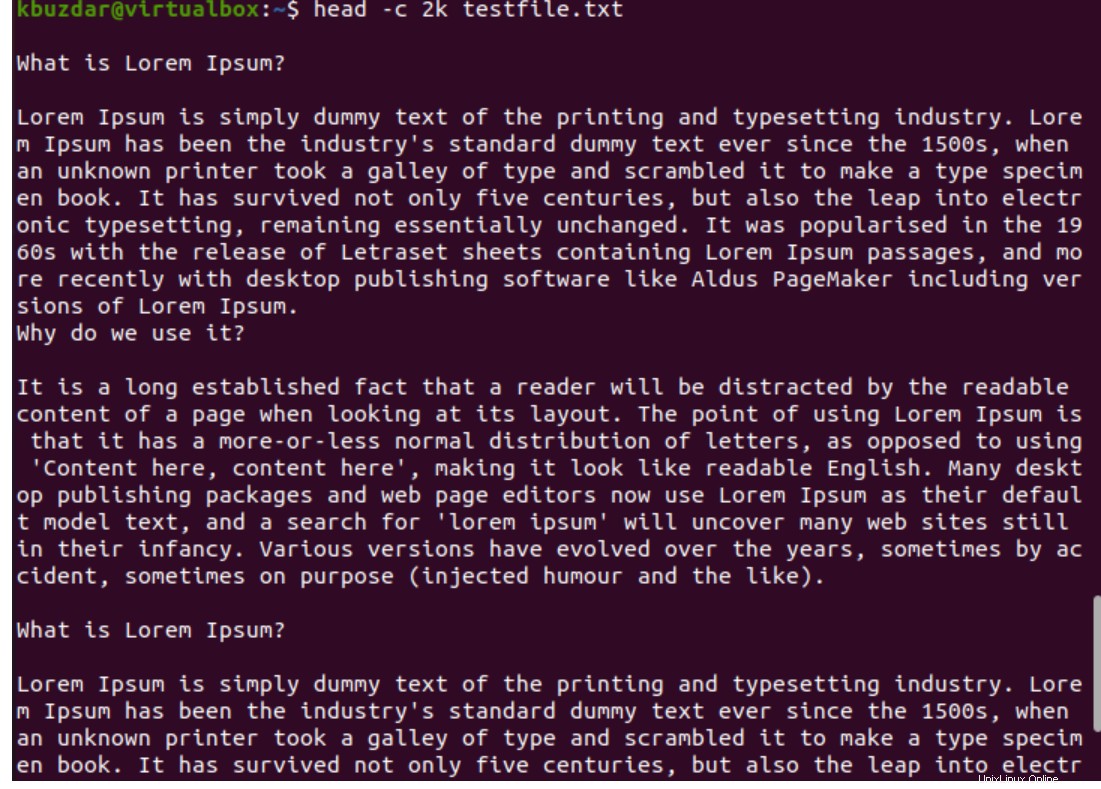
Per stampare i primi 2 kilobyte, eseguire il comando seguente:
$ head -c 2k testfile.txt
Specifica più file come input con il comando head
I file multipli, puoi anche prendere come input con il comando head come segue:
$ head testfile.txt testfile2.txt
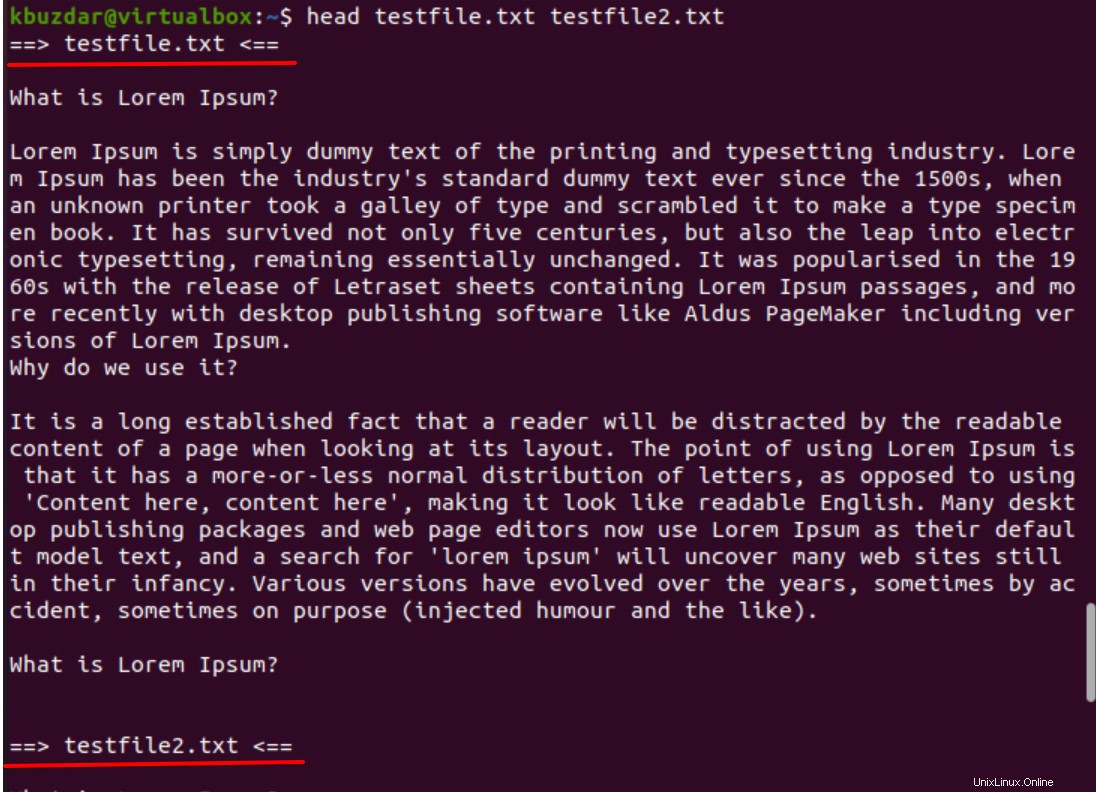
Il comando sopra menzionato ti mostrerà le prime dieci righe di ciascun nome di file.
Le stesse opzioni vengono utilizzate con il comando head in caso di più file.
Uso del comando di testa con il comando di coda
Il comando head può essere utilizzato anche con altri comandi. Ad esempio, per stampare le righe comprese tra 10 e 20 righe, puoi utilizzare il comando tail come segue:
$ head -n 20 testfile.txt | tail -10
Dirigere la pipeline di comandi con altri comandi
Il comando head può essere utilizzato anche come pipe con altri comandi. Ad esempio, per visualizzare i 2 file modificati più recenti utilizzare il comando seguente:
$ ls -t /etc | head -n 2

Conclusione
In questo articolo abbiamo fornito una buona comprensione dell'uso del comando head con tutte le opzioni richieste. Abbiamo visto come utilizzare efficacemente altri comandi con i comandi head. Usando il comando tail con un comando head, puoi anche visualizzare le ultime righe di un file sul terminale.