Elasticsearch è un potente motore di ricerca pronto per la produzione scritto in Java. Può essere utilizzato come motore di ricerca autonomo per il web o come motore di ricerca per applicazioni web di e-commerce.
eBay, Facebook e Netflix sono alcune delle aziende che utilizzano questa piattaforma. Elasticsearch è così popolare perché è più di un semplice motore di ricerca. È anche un potente motore di analisi e un sistema di gestione e recupero dei registri. La parte migliore è che è Open Source e gratuito. Kibana è lo strumento di visualizzazione fornito da elastic.
In questo tutorial, esamineremo i passaggi di installazione di Elasticsearch seguiti dall'installazione di Kibana. Quindi utilizzeremo Kibana per archiviare e recuperare i dati.
1 Installazione di Java
Poiché Elasticsearch è scritto in Java, deve essere prima installato. Utilizzare i comandi seguenti per installare le versioni open source di JRE e JDK:
sudo apt-get install default-jre
sudo apt-get install default-jdk
Questi due comandi installeranno l'ultimo open-jre e open-jdk sul tuo sistema. Userò JAVA 8 qui. Le immagini seguenti mostrano l'output che otterrai quando non hai installato Java ed esegui i comandi precedenti.
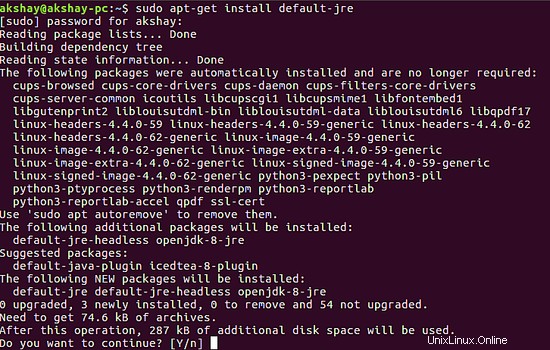
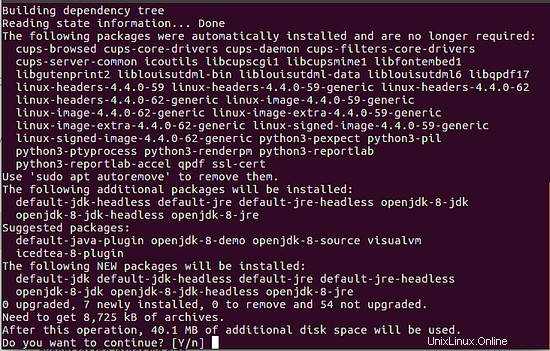
2 Installa Elasticsearch
Elasticsearch 5 è stato rilasciato di recente. Ha alcuni enormi cambiamenti rispetto alle sue versioni precedenti di 2.x. Al momento della stesura di questo articolo, la versione 5.2.2 è l'ultima versione e la installeremo. Quindi segui i passaggi seguenti per l'installazione.
mkdir elasticsearch; cd elasticsearch
wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-5.2.2.deb
Con questo, il file .deb dovrebbe iniziare il download. Sarà simile all'immagine qui sotto:
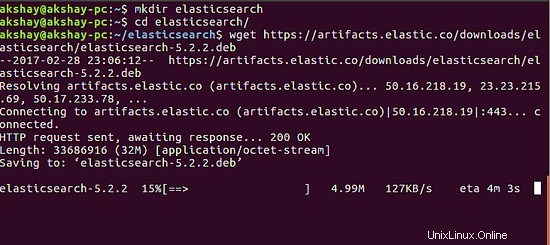
Una volta completato con successo il download, possiamo installarlo eseguendo il seguente comando. L'output dell'installazione riuscita è di seguito.
sudo dpkg -i elasticsearch-5.2.2.deb
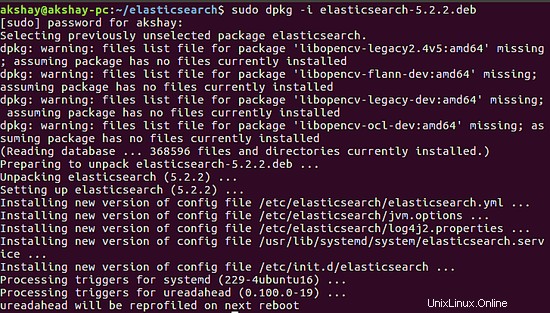
3 Configura ed esegui Elasticsearch
Elasticsearch viene eseguito come processo in background. Ma prima di avviarlo dobbiamo modificare il file di configurazione per aggiungere il sistema corrente come host che esegue il motore. usa il seguente comando per aprire il file di configurazione:
sudo gedit /etc/elasticsearch/elasticsearch.yml
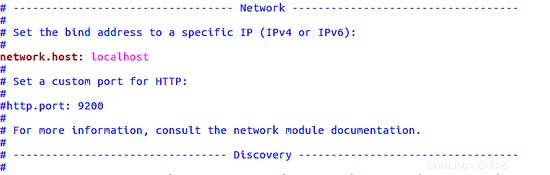
Una volta aperto l'editor, devi decommentare la riga:
#network.host: 192.168.0.1
e quindi cambia l'IP in localhost come mostrato nell'immagine seguente:
Ora siamo pronti per eseguire il processo. Utilizza i seguenti comandi:
sudo systemctl daemon-reload
sudo systemctl enable elasticsearch
sudo systemctl restart elasticsearch
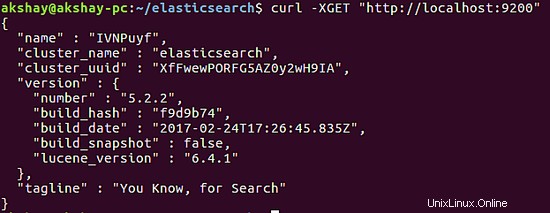
Questi tre comandi aggiungono il processo Elasticsearch al demone di sistema in modo che si avvii automaticamente all'avvio del sistema e quindi riavvii il processo stesso. Per verificare se il sistema è attivo e funzionante, utilizzare il comando seguente. L'output dovrebbe essere simile all'immagine mostrata di seguito.
curl -XGET "http://localhost:9200"
4 Installa Kibana
Scarica e installa il file deb utilizzando i seguenti comandi:
wget https://artifacts.elastic.co/downloads/kibana/kibana-5.2.2-amd64.deb
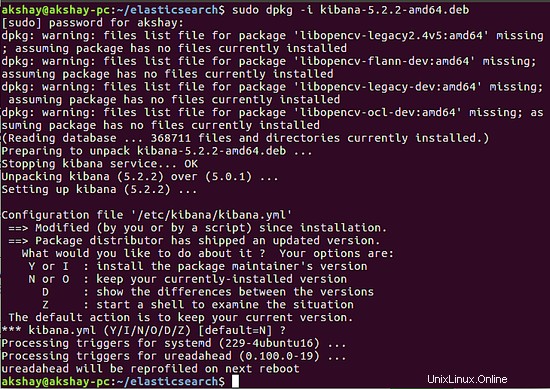
sudo dpkg -i kibana-5.2.2-amd64.deb
durante l'esecuzione del secondo comando, se ti chiede di modificare il file di configurazione di Kibana esistente, puoi premere invio per mantenere le impostazioni predefinite e terminare la competizione. Una volta installato, sarà simile all'immagine qui sotto.
5 Configura ed esegui Kibana
nel file di configurazione di Kibana, decommenta le seguenti righe:
server.port:
server.host:
server.name:
elasticsearch.name:
kibana.index:
Utilizzare il comando seguente per aprire il file di configurazione. Il file dopo aver apportato le modifiche dovrebbe essere simile all'immagine seguente:
sudo gedit /etc/kibana/kibana.yml
"server.name" può essere qualsiasi cosa, quindi sentiti libero di cambiarlo. Una volta apportate queste modifiche, salva e chiudi il file. L'ultima cosa da fare è aggiungere il processo Kibana all'elenco dei processi di sistema in modo che si avvii automaticamente ogni volta che il sistema si avvia. Esegui i seguenti comandi:
sudo systemctl daemon-reload
sudo systemctl enable kibana
sudo systemctl start kibana
Una volta eseguiti questi comandi, puoi aprire il browser web e utilizzare il seguente URL per verificare se è stato installato correttamente. L'immagine qui sotto mostra come dovrebbe apparire:
http://localhost:5601
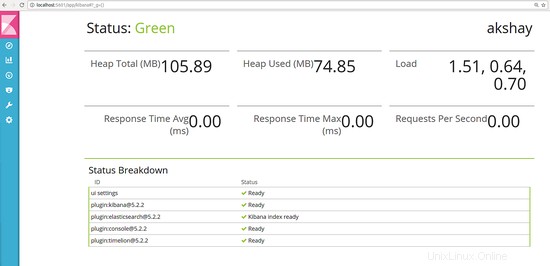
Questo è tutto. Ora hai installato con successo Kibana ed Elasticsearch.
6 Utilizzo di base
Possiamo usare l'utilità "Dev Tools" fornita da Kibana per parlare con Elasticsearch. Fornisce un'interfaccia pulita e semplice per eseguire i comandi come oggetti JSON. Interagiremo con il motore principale tramite un'interfaccia REST.
Vai a "Strumenti di sviluppo" facendo clic su  sul pannello di sinistra. Puoi anche utilizzare il seguente URL:
sul pannello di sinistra. Puoi anche utilizzare il seguente URL:
http://localhost:5601/app/kibana#/dev_tools/
Una volta caricato, riceverai un'introduzione "Benvenuto nella console" all'interfaccia utente. Puoi leggerlo o semplicemente fare clic su "Vai al lavoro " Pulsante nella parte inferiore dell'introduzione. Dopo aver fatto clic su quel pulsante, l'interfaccia utente sarà simile all'immagine seguente:
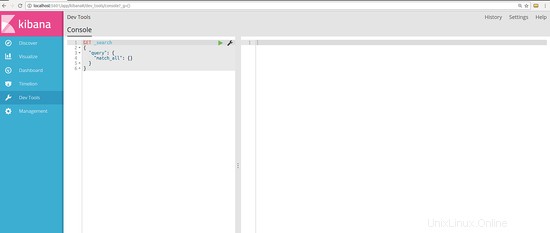
Sul lato sinistro digiteremo i comandi e sul pannello di destra otterremo l'output. Proviamo a inviare e memorizzare alcuni dati al motore di ricerca.
6.1 Crea un indice
I dati vengono archiviati in un indice. Per creare un indice, utilizziamo il comando PUT. Il JSON della richiesta conterrà il nome dell'indice e alcune impostazioni facoltative che possiamo fornire. Il comando seguente è un esempio per creare un indice chiamato "studente".
PUT student
{
"settings": {
"number_of_shards": 3
}
}
Puoi digitarlo su "Strumenti di sviluppo" e premere il pulsante di riproduzione verde accanto ad esso per eseguirlo. L'output sarà simile all'immagine seguente:
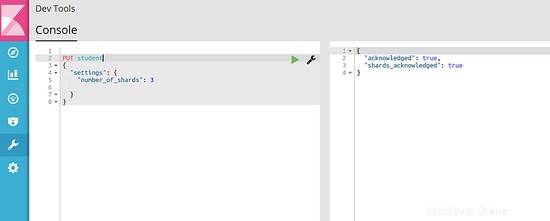
6.2 Inserisci alcuni dati da indicizzare
Useremo le chiamate POST per inserire i dati da indicizzare. I dati da inserire sono in formato JSON e quindi andiamo avanti aggiungendo gli studenti all'indice. Il comando è:
POST student/course
{
"name":"james",
"course": "mathematics"
}
Nel comando precedente, "corso" indica il tipo di dati che viene indicizzato. Dalla risposta, puoi vedere che anche questa voce ha un ID univoco. Nel comando seguente, puoi vedere che c'è un altro parametro dopo "corso", è così che puoi specificare qual è l'id per questa voce dello studente. In questo modo, elasticsearch non si preoccuperà di creare un ID, ma lo utilizzerà come ID di questo record.
POST student/course/2
{
"name":"tina",
"course": "physics"
}
Di seguito sono riportate le immagini che mostrano la risposta del motore di ricerca quando vengono eseguiti entrambi i comandi:
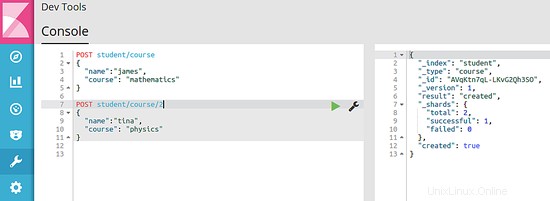
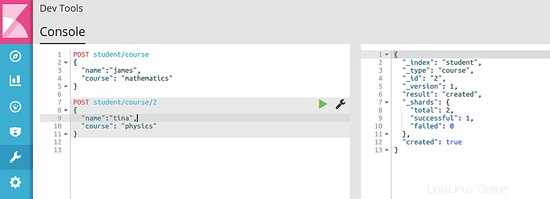
6.3 Recupera dati dall'indice
Puoi anche recuperare i dati in vari campi dal record o dalla voce memorizzati. Ogni voce che abbiamo salvato nel passaggio precedente è chiamata documento in Elasticsearch. Useremo la chiamata GET per recuperare i documenti dall'indice. Ecco come recuperare un documento utilizzando il campo "nome":
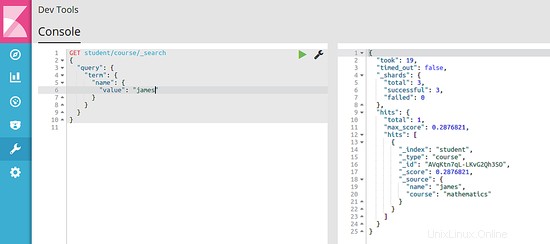
GET student/course/_search
{
"query": {
"term": {
"name": {
"value": "james"
}
}
}
}
Questo comando cerca lo "studente " indice per documenti di tipo "corso " e cerca di abbinare un termine con il nome del campo "nome " che ha il valore "James ". Poiché nell'indice è presente uno studente di nome James, otteniamo una risposta come mostrato nell'immagine seguente:
Queste erano solo le basi, ci sono un sacco di cose che possono essere fatte con Elasticsearch ed è necessaria molta esplorazione per padroneggiare questo framework e usarlo al meglio delle sue capacità.