Sharding è un processo MongoDB per memorizzare set di dati su macchine diverse. Ti consente di eseguire una scala orizzontale di dati, partizionare i dati su istanze indipendenti e può essere "Set di repliche". Il partizionamento del set di dati su "Sharding" utilizza la chiave shard. Lo sharding ti consente di aggiungere più macchine in base alla crescita dei dati nel tuo stack.
Sharding e replica
Rendiamolo semplice. Quando hai raccolte di musica, "Sharding" salverà e manterrà le tue raccolte musicali in una cartella diversa. La "replica", d'altra parte, sta semplicemente sincronizzando le tue raccolte musicali con altre istanze.
Tre componenti di sharding
Shard - Utilizzato per archiviare tutti i dati e, in un ambiente di produzione, ogni shard è set di repliche. Fornisce alta disponibilità e coerenza dei dati.
Configura server - Utilizzato per archiviare i metadati del cluster, contiene una mappatura del set di dati del cluster e degli shard. Questi dati vengono utilizzati da mongos/query server per fornire le operazioni. Si consiglia di utilizzare più di 3 istanze in produzione.
Router Mongos/Query - Si tratta solo di istanze mongo in esecuzione come interfacce dell'applicazione. L'applicazione invierà richieste alle istanze mongos, quindi mongos consegnerà le richieste utilizzando la chiave shard ai set di repliche degli shard.
Prerequisiti
- 2 server centOS 7 come set di repliche di configurazione
- 15.00.31 configsvr1
- 10.0.15.32 configsvr2
- 4 server CentOS 7 come set di repliche di frammenti
- 15.00.21 shardsvr1
- 15.10.22 shardsvr2
- 15.00.23 shardsvr3
- 15.00.24 shardsvr4
- 1 server CentOS 7 come mongos/Query Router
- 15.00.11 mongos
- Privilegi di root
- Ogni server connesso a un altro server
Passaggio 1 - Disattiva SELinux e configura gli host
Per questo tutorial, disabiliteremo SELinux. Modifica la configurazione di SELinux da 'enforcing' a 'disabled'.
Connettiti a tutti i nodi tramite OpenSSH.
ssh [email protected]
Disabilita SELinux modificando il file di configurazione.
vim /etc/sysconfig/selinux
Cambia il valore di SELinux in 'disabilitato'.
SELINUX=disabled
Salva ed esci.
Quindi, modifica il file hosts su ciascun server.
vim /etc/hosts
Incolla la seguente configurazione degli host:
10.0.15.31 configsvr1
10.0.15.32 configsvr2
10.0.15.11 mongos
10.0.15.21 shardsvr1
10.0.15.22 shardsvr2
10.0.15.23 shardsvr3
10.0.15.24 shardsvr4
Salva ed esci.
Ora riavvia tutti i server:
reboot
Passaggio 2 - Installa MongoDB su tutte le istanze
Useremo l'ultimo MongoDB (MongoDB 3.4) per tutte le istanze. Aggiungi un nuovo repository MongoDB eseguendo i seguenti comandi:
cat <<'EOF' >> /etc/yum.repos.d/mongodb.repo
[mongodb-org-3.4]
name=MongoDB Repository
baseurl=https://repo.mongodb.org/yum/redhat/$releasever/mongodb-org/3.4/x86_64/
gpgcheck=1
enabled=1
gpgkey=https://www.mongodb.org/static/pgp/server-3.4.asc
EOF
Ora installa mongodb 3.4 dal repository mongodb usando il comando yum di seguito.
sudo yum -y install mongodb-org
Dopo aver installato mongodb, usa 'mongo ' o 'mongo ' nel modo seguente per controllare i dettagli della versione.
mongod --version
Passaggio 3:crea un set di repliche del server di configurazione
Nella sezione dei prerequisiti, abbiamo già definito il server di configurazione con 2 macchine 'configsvr1' e 'configsvr2'. E in questo passaggio, lo configureremo come un set di repliche.
Se è presente un servizio mongod in esecuzione sul server, arrestarlo con il seguente comando systemctl.
systemctl stop mongod
Modifica la configurazione predefinita di mongodb 'mongod.conf '.
vim /etc/mongod.conf
Cambia il percorso di archiviazione del DB nella tua directory. Useremo '/data/db1' per il primo server e la directory '/data/db2' per il secondo server di configurazione.
storage:
dbPath: /data/db1
Modifica il valore della riga 'bindIP' con il tuo indirizzo di rete interno. 'configsvr1' con indirizzo IP 10.0.15.31 e il secondo server con 10.0.15.32.
bindIP: 10.0.15.31
Nella sezione di replica, imposta un nome di replica.
replication:
replSetName: "replconfig01"
E nella sezione di partizionamento orizzontale, definisci un ruolo delle istanze. Useremo queste due istanze come 'configsvr'.
sharding:
clusterRole: configsvr
Salva ed esci.
Successivamente, dobbiamo creare una nuova directory per i dati MongoDB, quindi modificare i permessi di proprietà di quella directory nell'utente 'mongod'.
mkdir -p /data/db1
chown -R mongod:mongod /data/db1
Quindi, avvia il servizio mongod con il seguente comando.
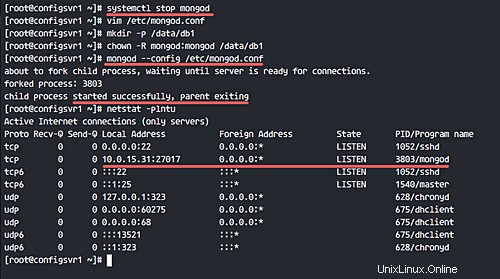
mongod --config /etc/mongod.conf
Puoi controllare che il servizio mongod sia in esecuzione sulla porta 27017 con il comando netstat.
netstat -plntu
Configsvr1 e Configsvr2 sono pronti per il set di repliche. Collegati al server 'configsvr1' e accedi alla shell mongo.
ssh [email protected]
mongo --host configsvr1 --port 27017
Avvia il nome del set di repliche con tutti i membri di configsvr utilizzando la query seguente.
rs.initiate(
{
_id: "replconfig01",
configsvr: true,
members: [
{ _id : 0, host : "configsvr1:27017" },
{ _id : 1, host : "configsvr2:27017" }
]
}
)
Se ottieni un risultato "{ "ok" :1 } ', significa che configsvr è già configurato con il set di repliche.
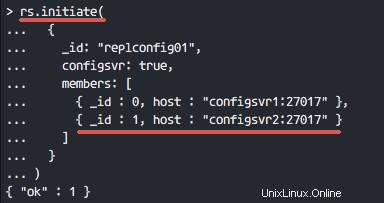
e sarai in grado di vedere quale nodo è master e quale nodo è secondario.
rs.isMaster()
rs.status()
La configurazione di Config Server Replica Set è completata.
Passaggio 4:creazione di set di repliche shard
In questo passaggio, configureremo 4 server centos 7 come server "Shard" con 2 "Set di repliche".
- 2 server - 'shardsvr1 ' e 'shardsvr2 ' con il nome del set di repliche:'shardreplica01 '
- 2 server - 'shardsvr3 ' e 'shardsvr4 ' con il nome del set di repliche:'shardreplica02 '
Connettiti a ciascun server e arresta il servizio mongod (se il servizio è in esecuzione) e modifica il file di configurazione di MongoDB.
systemctl stop mongod
vim /etc/mongod.conf
Cambia lo spazio di archiviazione predefinito nella tua directory specifica.
storage:
dbPath: /data/db1
Nella riga 'bindIP', cambia il valore nel tuo indirizzo di rete interno.
bindIP: 10.0.15.21
Nella sezione di replica, puoi utilizzare 'shardreplica01 ' per la prima e la seconda istanza. E usa 'shardreplica02 ' per il terzo e il quarto server shard.
replication:
replSetName: "shardreplica01"
Quindi, definisci il ruolo del server. Useremo tutto questo come istanze shardsvr.
sharding:
clusterRole: shardsvr
Salva ed esci.
Ora crea una nuova directory per i dati MongoDB.
mkdir -p /data/db1
chown -R mongod:mongod /data/db1
Avvia il servizio mongod.
mongod --config /etc/mongod.conf
Controlla se MongoDB è in esecuzione con il comando seguente:
netstat -plntu
Vedrai che MongoDB è in esecuzione sull'indirizzo di rete locale.
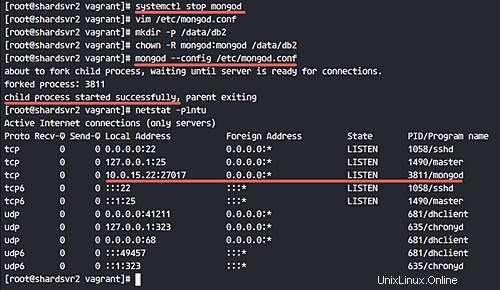
Quindi, crea un nuovo set di repliche per queste 2 istanze di shard. Collegati a 'shardsvr1' e accedi alla shell mongo.
ssh [email protected]
mongo --host shardsvr1 --port 27017
Avvia il set di repliche con il nome 'shardreplica01 ' e i membri sono 'shardsvr1 ' e 'shardsvr2 '.
rs.initiate(
{
_id : "shardreplica01",
members: [
{ _id : 0, host : "shardsvr1:27017" },
{ _id : 1, host : "shardsvr2:27017" }
]
}
)
Se non ci sono errori, vedrai i risultati come mostrato di seguito.
Risultati da shardsvr3 e shardsvr4 con il nome del set di repliche 'shardreplica02 '.
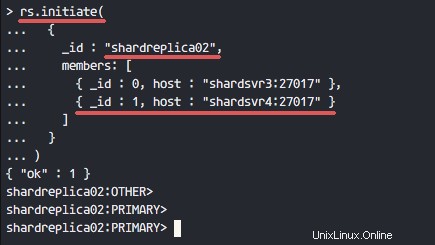
Ripeti questo passaggio su shardsvr3 e shardsvr4 server con nome del set di repliche diverso 'shardreplica02 '.
Ora abbiamo creato 2 set di repliche come shard:'shardreplica01 ' e 'shardreplica02 '.
Passaggio 5 - Configura mongos/Query Router
Il "Query Router" o mongos sono solo istanze che eseguono "mongos". Puoi eseguire mongos con il file di configurazione o eseguirlo solo con una riga di comando.
Accedi al server mongos e interrompi il servizio MongoDB.
ssh [email protected]
systemctl stop mongod
Esegui mongos con il comando seguente.
mongos --configdb "replconfig01/configsvr1:27017,configsvr2:27017"
utilizzare l'opzione '--configdb' per definire il server di configurazione. Se sei in produzione, usa almeno 3 server di configurazione.
Vedrai i risultati di seguito.
Successfully connected to configsvr1:27017
Successfully connected to configsvr2:27017
le istanze mongos sono in esecuzione.
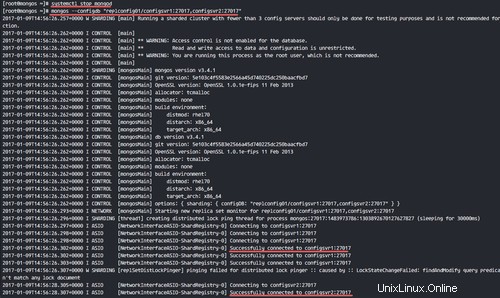
Passaggio 6:aggiungi shard a mongos/Query Router
Apri un'altra shell dal passaggio 5, connetti di nuovo al server mongos e accedi alla shell mongo.
ssh [email protected]
mongo --host mongos --port 27017
Aggiungi shard server con query sh mongodb.
Per 'shardreplica01 ' istanze.
sh.addShard( "shardreplica01/shardsvr1:27017")
sh.addShard( "shardreplica01/shardsvr2:27017")
Per 'shardreplica02 ' istanze.
sh.addShard( "shardreplica02/shardsvr3:27017")
sh.addShard( "shardreplica02/shardsvr4:27017")
Assicurati che non ci siano errori e controlla lo stato dello shard.
sh.status()
Farai lo sharding dello stato come mostrato nello screenshot qui sotto.
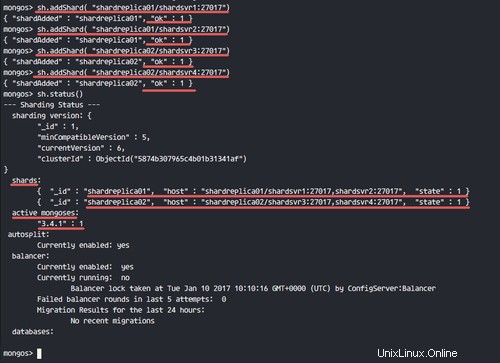
Abbiamo 2 set di repliche di frammenti e 1 istanza mongos in esecuzione nel nostro stack.
Fase 7 - Test
Ora testeremo il server MongoDB abilitando lo sharding e quindi aggiungeremo documenti.
Accedi alla shell mongo del server mongos.
ssh [email protected]
mongo --host mongos --port 27017
Abilita lo sharding per un database
Crea un nuovo database e abilita il partizionamento orizzontale per il nuovo database.
use lemp
sh.enableSharding("lemp")
sh.status()
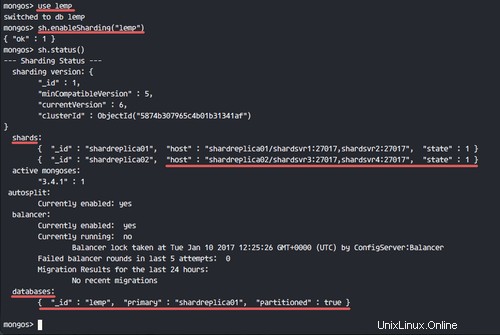
Ora guarda lo stato del database:è stato partizionato nel set di repliche 'shardreplica01'.
Abilita partizionamento orizzontale per le raccolte
Successivamente, aggiungi nuove raccolte al database con il supporto del partizionamento orizzontale. Aggiungeremo una nuova raccolta denominata "stack" con la raccolta di shard "nome", quindi vedremo lo stato del database e delle raccolte.
sh.shardCollection("lemp.stack", {"name":1})
sh.status() 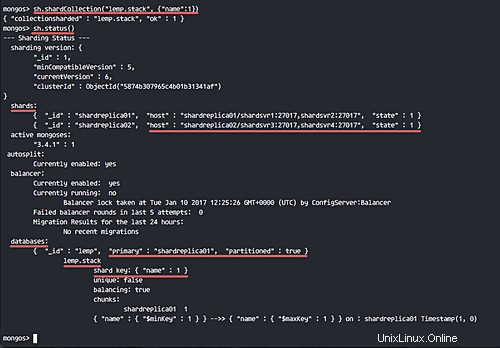
Sono state aggiunte nuove raccolte 'stack' con shard collection 'name'.
Aggiungi documenti alla "pila" delle raccolte.
Ora inserisci i documenti nelle raccolte. Quando aggiungiamo documenti alla raccolta su un cluster partizionato, dobbiamo includere la "chiave shard".
Puoi usare un esempio qui sotto. Stiamo utilizzando la chiave shard 'nome ', come abbiamo aggiunto quando si abilita il partizionamento orizzontale per le raccolte.
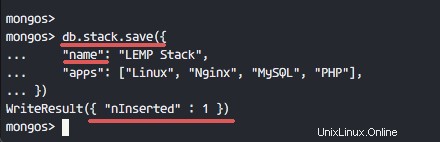
db.stack.save({
"name": "LEMP Stack",
"apps": ["Linux", "Nginx", "MySQL", "PHP"],
}) I documenti sono stati aggiunti correttamente alla raccolta, come mostrato nella schermata seguente.
Se desideri testare il database, puoi connetterti al set di repliche 'shardreplica01 ' PRIMARY server e apri la shell mongo. Sto accedendo al server PRIMARIO 'shardsvr2'.
ssh [email protected]
mongo --host shardsvr2 --port 27017
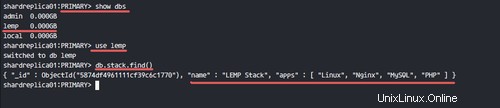
Verifica il database disponibile sul set di repliche.
show dbs
use lemp
db.stack.find()
Vedrai che il database, le raccolte e i documenti sono disponibili nel set di repliche.
Cluster partizionato MongoDB su CentOS 7 installato e distribuito correttamente.