Introduzione
Le funzioni di stringa MySQL consentono agli utenti di manipolare stringhe di dati o interrogare informazioni su una stringa restituita da SELECT interrogazione.
In questo articolo imparerai come utilizzare le funzioni di stringa MySQL.

Prerequisiti
- MySQL Server e MySQL Shell installati
- Un account utente MySQL con privilegi di root
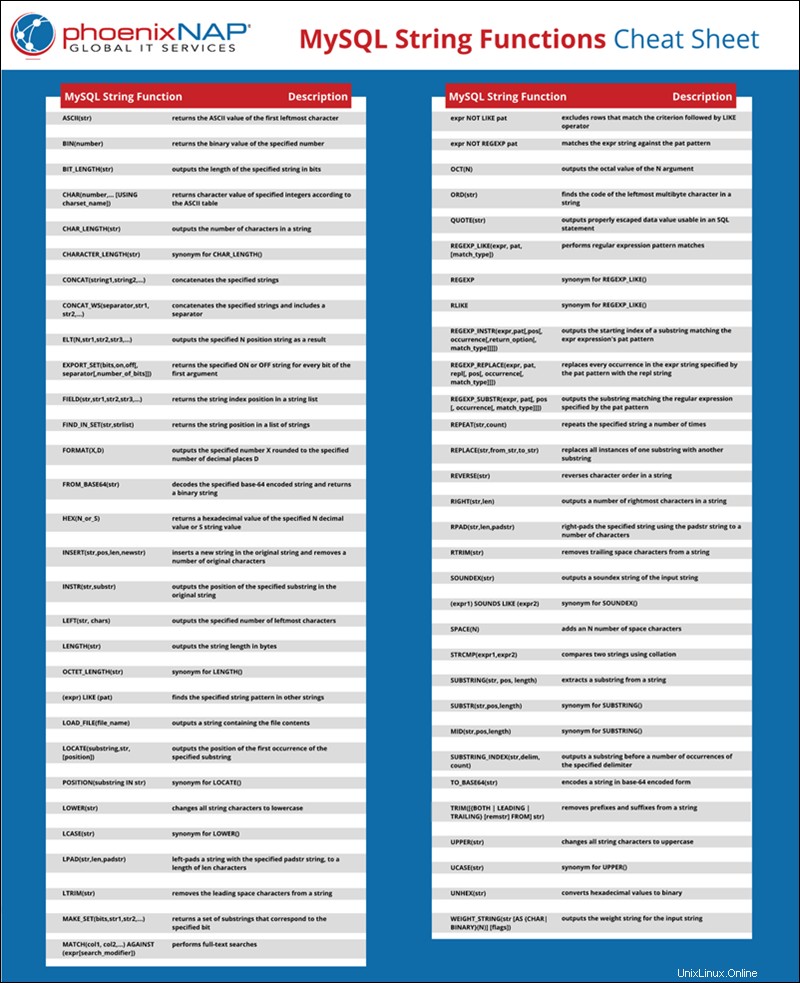
Foglio informativo sulle funzioni di stringa MySQL
Ogni funzione di stringa è spiegata ed esemplificata nell'articolo seguente. Se è più conveniente per te, puoi salvare il cheat sheet in PDF facendo clic su Scarica il cheat sheet di MySQL String Functions collegamento.
Scarica il cheat sheet di MySQL String Functions
ASCII()
La sintassi per ASCII() la funzione è:
ASCII('str')
Il ASCII() string restituisce il valore ASCII (numerico) del carattere più a sinistra del str specificato corda. La funzione restituisce 0 se non str è specificato. Restituisce NULL se str è NULL .
Usa ASCII() per caratteri con valori numerici da 0 a 255.
Ad esempio:

In questo esempio, il ASCII() la funzione restituisce il valore numerico di p , il carattere più a sinistra del str specificato stringa.
BIN()
La sintassi per BIN() la funzione è:
BIN(number)
Il BIN() la funzione restituisce un valore binario del number specificato argomento, dove il number è un BIGINTEGER numero. Restituisce NULL se il number l'argomento è NULL .
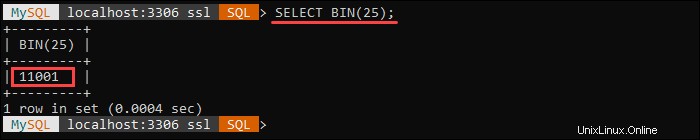
Ad esempio, la query seguente restituisce una rappresentazione binaria del numero 25:
BIT_LENGTH()
La sintassi per BIT_LENGTH() la funzione è:
BIT_LENGTH('str')
La funzione restituisce la lunghezza del str specificato stringa in bit.
Ad esempio, la query seguente restituisce la lunghezza in bit dell''esempio specificato ' stringa:

CHAR()
La sintassi per CHAR() la funzione è:
CHAR(number,... [USING charset_name])
CHAR() interpreta ogni number specificato argomento come un numero intero e restituisce una stringa binaria di caratteri dalla tabella ASCII. La funzione salta NULL valori.
Ad esempio:

Se vuoi produrre un output diverso da binario, usa il USING facoltativo clausola e specificare il set di caratteri desiderato. MySQL emette un avviso se la stringa del risultato è illegale per il set di caratteri specificato.
CHAR_LENGTH(), ovvero CHARACTER_LENGTH()
La sintassi per CHAR_LENGTH la funzione è:
CHAR_LENGTH(str)
La funzione restituisce la lunghezza del str specificato stringa, misurata in caratteri.
CHAR_LENGTH() tratta un carattere multibyte come un singolo carattere, il che significa che una stringa contenente quattro caratteri da 2 byte restituisce 4 come risultato, mentre LENGTH() restituisce 8.
Ad esempio:

CHARACTER_LENGTH() è sinonimo di CHAR_LENGTH() .
CONCAT()
Il CONCAT() funzione concatena due o più stringhe specificate. La sintassi è:
CONCAT(string1,string2,...)
Il CONCAT La funzione converte tutti gli argomenti nel tipo stringa prima della concatenazione. Se tutti gli argomenti sono stringhe non binarie, il risultato è una stringa non binaria. D'altra parte, la concatenazione di stringhe binarie risulta in una stringa binaria. Un argomento numerico viene convertito nella sua forma di stringa non binaria equivalente.
Se uno degli argomenti specificati è NULL , CONCAT() restituisce NULL di conseguenza.
Ad esempio:

La funzione mette insieme le stringhe specificate in una, in questo caso, 'phoenixNAP '.
CONCAT_WS()
La sintassi per CONCAT_WS() è:
CONCAT_WS(separator,str1,str2,...)
CONCAT_WS() è una forma speciale di CONCAT() che mette insieme due o più espressioni e include un separatore. Il separatore divide le stringhe che vuoi concatenare. Se il separatore è NULL , il risultato è NULL .
Ad esempio:

In questo esempio, il separatore è uno spazio vuoto che separa le stringhe specificate nell'output.
ELT()
La sintassi per ELT() la funzione è:
ELT(N,str1,str2,str3,...)
Il N argomento definisce quale delle stringhe specificate restituire come risultato. ELT() restituisce NULL se N è minore di 1 o maggiore del numero di stringhe specificate.
Ad esempio:

EXPORT_SET()
La sintassi per EXPORT_SET() è:
EXPORT_SET(bits,on,off[,separator[,number_of_bits]])
Il EXPORT_SET() la funzione restituisce un ON o OFF stringa per ogni bit del primo argomento, controllando da destra a sinistra. L'argomento è un numero intero, ma la funzione lo converte in bit.
Se il bit è 1, la funzione restituisce il ON corda. Se il bit è 0, la funzione restituisce OFF . EXPORT_SET() inserisce un separatore tra i valori restituiti. Il separatore predefinito è una virgola, ma puoi specificarne uno diverso come quarto argomento.
Le stringhe vengono aggiunte al risultato di output da sinistra a destra, separate dalla stringa di separazione. Il number_of_bits argomento specifica quanti bit esaminare.
Ad esempio:

Spiegazione:
1. Dopo la conversione, il primo argomento 5 sta per 00000101.
2. Controllando da destra a sinistra, il primo bit è 1, quindi la funzione restituisce 'Sì ' argomento (il ON corda). Il secondo bit è 0, quindi la funzione restituisce 'No ' (il OFF corda). Per il terzo bit, restituisce "Sì .' Per tutti i bit rimanenti (zeri), restituisce 'No .'
3. Il quarto argomento '- ' è specificato come separatore nel risultato restituito.
CAMPO()
La sintassi per FIELD() la sintassi è:
FIELD(str,str1,str2,str3,...)
La funzione restituisce la posizione dell'indice di una stringa in un elenco di stringhe. Se non esiste una stringa di questo tipo, l'output è 0. Se la stringa è NULL , la funzione restituisce 0. Il FIELD() la funzione non fa distinzione tra maiuscole e minuscole.
Ad esempio:

La funzione restituisce 6, che è la posizione della stringa 'f ' nell'elenco.
TROVA_IN_SET()
La sintassi per FIND_IN_SET() la funzione è:
FIND_IN_SET(str,strlist)La funzione restituisce la posizione di una stringa in un elenco di stringhe. Se sono presenti più istanze di stringa, l'output restituisce solo la prima posizione della stringa specificata.
Ad esempio:

FORMATO()
La sintassi per FORMAT() la funzione è:
FORMAT(X,D)
La funzione restituisce il numero specificato X in un formato come '#,###,###.##', arrotondato al numero di cifre decimali specificato D . Il risultato non ha punto decimale se D è 0.
Gli utenti possono anche specificare la lingua dopo la D argomento, che influisce sull'output.
Ad esempio:

L'output arrotonda il numero a 3 cifre decimali e la lingua tedesca genera un . simbolo per indicare le migliaia e il , carattere per indicare le frazioni.
DA_BASE64()
La sintassi per FROM_BASE64() la funzione è:
FROM_BASE64(str)
La funzione decodifica la stringa codificata in base 64 specificata e restituisce il risultato come stringa binaria. Se l'argomento è NULL o una stringa base-64 non valida, il risultato è NULL .
FROM_BASE64() è il contrario di TO_BASE64() come TO_BASE64() codifica una query in base64.
Ad esempio:
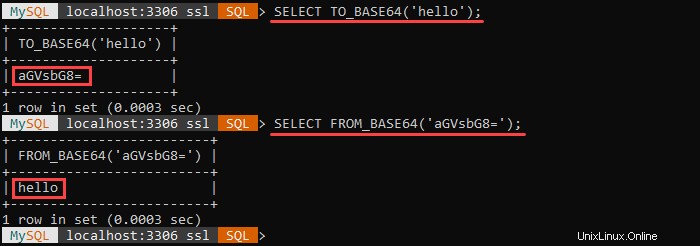
La prima query codifica la stringa specificata in base64. La seconda query decodifica la stringa codificata in base64 e restituisce il valore originale.
ESAG.()
La sintassi per HEX() la funzione è:
HEX(N_or_S)
La funzione restituisce una rappresentazione di stringa di un valore esadecimale del N specificato valore decimale o S valore della stringa.
Se l'argomento è una string , HEX converte ogni carattere in due cifre esadecimali. Se invece l'argomento è un decimal , l'output è una rappresentazione di stringa esadecimale dell'argomento e lo tratta come un BIGINTEGER numero.
Il HEX() la funzione stringa è equivalente alla funzione matematica CONV(N,10,16) .
Ad esempio:

L'output restituisce il valore esadecimale della stringa specificata.
INSERIRE()
La sintassi per INSERT() la funzione è:
INSERT(str,pos,len,newstr)
La funzione inserisce un newstr stringa all'interno di str stringa e rimuove il len numero di caratteri originali che iniziano con pos posizione.
Se il pos argomento non rientra nella lunghezza della stringa originale, INSERT() restituisce la stringa originale.
Se il len argomento non rientra nella lunghezza del resto della stringa, INSERT() sostituisce il resto della stringa da pos posizione.
Se un argomento è NULL , INSERT() restituisce NULL .
Ad esempio:

L'output è la stringa originale con la nuova stringa inserita in posizione 5, senza caratteri originali rimossi.
INSTR()
La sintassi per INSTR() la funzione è:
INSTR(str,substr)
La funzione restituisce la posizione della prima apparizione del substr sottostringa nella str originale stringa.
La funzione funziona allo stesso modo di LOCATE() , tranne per il fatto che l'ordine degli argomenti è invertito.
Ad esempio:

L'output indica la posizione della sottostringa - posizione 8.
SINISTRA()
La sintassi per LEFT() la funzione è:
LEFT('str', chars)
La funzione restituisce il numero di caratteri più a sinistra chars dal str specificato stringa.
Se un argomento è NULL , anche l'output è NULL .
Ad esempio:

LENGTH(), ovvero OCTET_LENGTH()
La sintassi per LENGTH() la funzione è:
LENGTH(str)
La funzione restituisce il str lunghezza della stringa in byte. I caratteri multibyte contano come più byte.
Ad esempio:

Il OCTET_LENGTH() funzione è sinonimo di LENGTH() .
MI PIACE
La sintassi per LIKE la funzione è:
expr LIKE patLa funzione esegue la corrispondenza del modello trovando il modello di stringa specificato all'interno di altre stringhe.
LIKE supporta i caratteri jolly:
%-Corrisponde a qualsiasi numero di caratteri, anche zero._- Corrisponde esattamente a un carattere.
LIKE restituisce 1 (vero) o 0 (falso). Se il expr espressione o pat il modello è NULL , anche l'output è NULL .
Ad esempio:
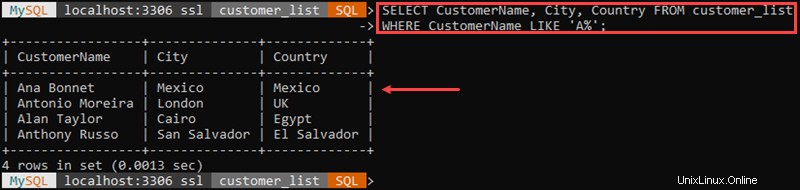
In questo esempio, abbiamo recuperato tutti i clienti il cui nome inizia con 'A '.
LOAD_FILE()
La sintassi per LOAD_FILE() la funzione è:
LOAD_FILE(file_name)La funzione legge il file e genera una stringa contenente il contenuto del file. I prerequisiti per questa funzione sono:
- Avere il file sull'host del server.
- Specificare il percorso completo del file al posto dell'argomento nome_file.
- Avere il privilegio FILE .
Il server deve essere in grado di leggere il file e la sua dimensione deve essere inferiore a max_allowed_packet byte. Se il secure_file_priv la variabile di sistema è un nome di directory non vuoto, posiziona il file in quella directory.
Se il file non esiste o la funzione non può leggerlo per uno dei motivi precedenti, l'output è NULL .
Ad esempio:

LOCATE(), ovvero POSITION()
La sintassi per LOCATE() la funzione è:
LOCATE(substring,str,[position])
La funzione restituisce la posizione della prima occorrenza della substring specificata argomento all'interno di str corda. La position argomento è facoltativo e utilizzato per specificare da quale str posizione della stringa per avviare la ricerca. Omissione della position l'argomento inizia la ricerca dall'inizio.
Se la substring non è nel str stringa, LOCATE() restituisce 0. Se un argomento è NULL , la funzione restituisce NULL .
Ad esempio:

Il POSITION(substring IN str) funzione è sinonimo di LOCATE(substr,str) .
LOWER(), ovvero LCASE()
La sintassi per LOWER() la funzione è:
LOWER(str)
La funzione cambia tutti i caratteri del str specificato string in minuscolo e restituisce il risultato. La mappatura predefinita del set di caratteri che utilizza è utf8mb4. LOWER() è multibyte sicuro.
Ad esempio:

Il LCASE() funzione è sinonimo di LOWER() .
LPAD()
La sintassi per LPAD() la funzione è:
LPAD(str,len,padstr)
La funzione restituisce il str specificato stringa, riempita a sinistra con il padstr stringa, per una lunghezza di len caratteri. La funzione riduce l'output a len caratteri se il str argomento è più lungo di len .
LPAD() è multibyte sicuro.
Ad esempio:

In questo esempio, il LPAD() la funzione riempie a sinistra l'argomento specificato con il padstr specificato , fino a 10 caratteri.
LTRIM()
La sintassi per LTRIM() la funzione è:
LTRIM(str)
La funzione restituisce il str specificato stringa senza spazi iniziali.
Ad esempio:

MAKE_SET()
La sintassi per MAKE_SET() la funzione è:
MAKE_SET(bits,str1,str2,...)
La funzione restituisce un valore impostato, ovvero una stringa contenente le sottostringhe specificate con il bit corrispondente specificato nei bits argomento.
Il str1 argomento corrisponde al bit 0, str2 corrisponde al bit 1, ecc. Se uno qualsiasi degli argomenti è NULL , non vengono visualizzati nel risultato.
Ad esempio:

In questo esempio, il primo bit è 1, ovvero 001. La cifra più a destra è 1, quindi la funzione restituisce 'phoenix .' Il secondo bit è 2, ovvero 010, il numero centrale è 1, quindi la funzione restituisce 'NAP ,' completando così l'output.
PARTITA()
La sintassi per MATCH() la funzione è:
MATCH(col1, col2,…) AGAINST(expr[search_modifier])
La funzione consente agli utenti di eseguire ricerche full-text specificando un elenco di colonne separate da virgole. Inserisci una stringa che desideri cercare al posto di expr argomento.
Il search_modifier argomento è facoltativo e indica il tipo di ricerca. I valori accettati sono:
IN NATURAL LANGUAGE MODE(predefinito)IN NATURAL LANGUAGE MODE WITH QUERY EXPANSIONIN BOOLEAN MODEWITH QUERY EXPANSION
Ad esempio:
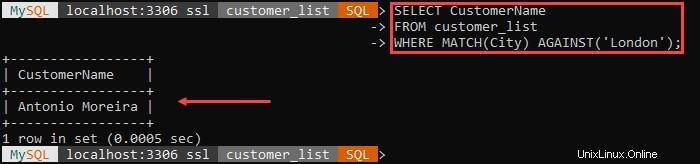
NON MI PIACE
La sintassi per NOT LIKE la funzione è:
expr NOT LIKE pat [ESCAPE 'escape_char']
NOT LIKE è una negazione di LIKE , il che significa che opera alle stesse condizioni di LIKE e utilizza gli stessi caratteri jolly.
Ad esempio:
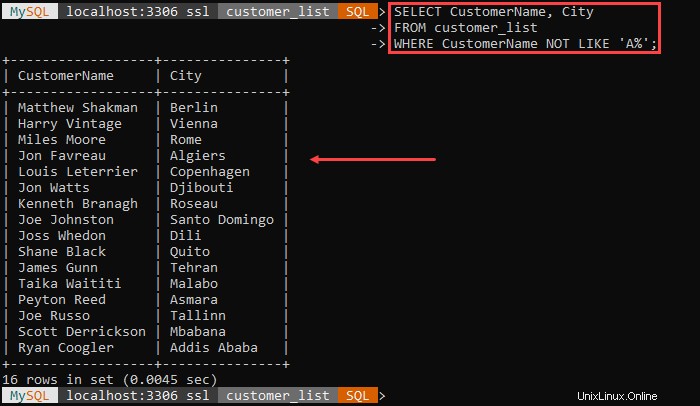
L'output elenca tutti i clienti e la loro città ad eccezione dei clienti il cui nome inizia con 'A .'
NON REGEXP
La sintassi per NOT REGEXP la funzione è:
expr NOT REGEXP pat
La funzione esegue una corrispondenza del modello di expr stringa contro il pat modello. Il modello può essere un'espressione regolare estesa.
NOT REGEXP è una negazione di REGEXP .
Se il expr l'argomento corrisponde a pat argomento, l'output è 1. Altrimenti, l'output è 0. Se uno degli argomenti è NULL , l'output è NULL .
Ad esempio:
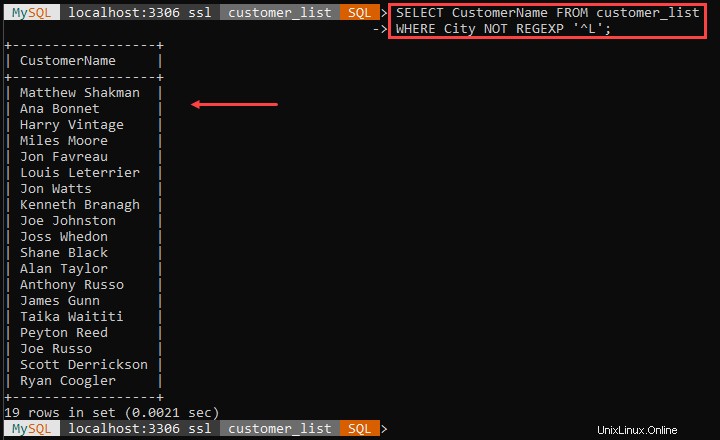
L'esempio sopra mostra tutti i clienti che non risiedono in città che iniziano con L. Il '^ Il carattere ' segna l'inizio del nome della città.
OTT()
La sintassi per OCT() la funzione è:
OCT(N)
La funzione restituisce il valore ottale del N specificato argomento, dove N è un BIGINTEGER numero. Se N è NULL , la funzione restituisce NULL .
Ad esempio:

ORD()
La sintassi per ORD() la funzione è:
ORD(str)
La funzione trova il codice del carattere multibyte più a sinistra in una stringa. Se il carattere più a sinistra non è multibyte, ORD() restituisce il valore ASCII del carattere.
La funzione calcola il codice del carattere dai valori numerici dei suoi byte costituenti. La formula utilizzata per questa operazione è:
(codice 1° byte) + (codice 2° byte * 256) + (codice 3° byte * 256^2) ...
Ad esempio:

CITAZIONE()
La sintassi per QUOTE() la funzione è:
QUOTE(str)La funzione restituisce una stringa che rappresenta il valore di dati correttamente sottoposto a escape utilizzabile in un'istruzione SQL. Le virgolette singole racchiudono la stringa e contiene una barra rovesciata (\ ) prima di ogni istanza di barra rovesciata (\ ), virgolette singole (' ), ASCII NUL e Control+Z .
Se il str l'argomento è NULL , l'output è NULL .
Ad esempio:
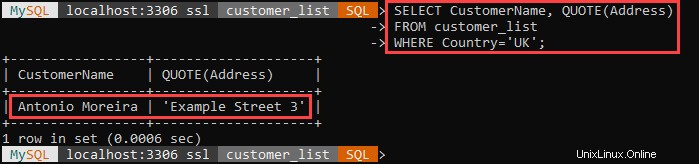
L'esempio sopra seleziona tutti i clienti che risiedono nel Regno Unito e racchiude i loro indirizzi tra virgolette singole.
REGEXP_LIKE(), REGEXP, RLIKE
La sintassi per REGEXP_LIKE() la funzione è:
REGEXP_LIKE(expr, pat, [match_type])
La funzione restituisce 1 se expr string corrisponde all'espressione specificata al posto di pat discussione. In caso contrario, l'output è 0. Se expr o pat l'argomento è NULL , il valore di output è NULL .
Il match_type argomento è facoltativo e rappresenta una stringa che può contenere uno o tutti i seguenti flag che specificano il tipo di corrispondenza:
- Corrispondenza con distinzione tra maiuscole e minuscole (
c). Gestisci gli argomenti come stringhe binarie con distinzione tra maiuscole e minuscole se uno degli argomenti è una stringa binaria. Ilcflag significa che viene adottata la distinzione tra maiuscole e minuscole anche se iliviene anche specificato il flag. - Corrispondenza senza distinzione tra maiuscole e minuscole (
i). Gestisci gli argomenti senza distinzione tra maiuscole e minuscole. - Modalità a più righe (
m). Riconosci i terminatori di riga all'interno della stringa. L'impostazione predefinita prevede la corrispondenza dei terminatori di riga solo all'inizio e alla fine dell'espressione stringa. - Il . il carattere corrisponde ai terminatori di riga (
n). Utilizzato per modificare il . (punto) carattere per abbinare i terminatori di riga. Per impostazione predefinita, . la corrispondenza si ferma alla fine di una riga. - Termini di riga solo Unix (
u). Terminazioni di riga solo Unix che riconoscono solo il carattere di nuova riga dagli operatori di corrispondenza ., ^ e $.
Se vengono specificati flag contraddittori all'interno di match_type , quello più a destra ha la precedenza.
REGEXP e RLIKE sono sinonimi di REGEXP_LIKE() .
Ad esempio:

In questo esempio, l'espressione regolare può specificare qualsiasi carattere al posto del punto, quindi la funzione restituisce un 1 per indicare una corrispondenza.
REGEXP_INSTR()
La sintassi per REGEXP_INSTR() la funzione è:
REGEXP_INSTR(expr, pat[, pos[, occurrence[, return_option[, match_type]]]])
La funzione restituisce l'indice iniziale di una sottostringa che corrisponde a expr patto dell'espressione modello. Se non c'è corrispondenza, l'output è 0. Se uno degli argomenti è NULL , l'output è NULL . Gli indici dei caratteri iniziano da 1.
Gli argomenti facoltativi sono:
pos- Specifica la posizione inexprdove iniziare la ricerca. Se omesso, il valore predefinito è 1.occurrence- Specifica quale occorrenza di una corrispondenza cercare. Se omesso, il valore predefinito è 1.return_option- Quale tipo di posizione restituire. Se impostato su 0,REGEXP_INSTR()restituisce la posizione del primo carattere della sottostringa corrispondente. Se impostato su 1,REGEXP_INSTR()restituisce la posizione dopo la sottostringa corrispondente. Se omesso, il valore predefinito è 0.match_type- Specifica come abbinare. L'argomento è lo stesso diREGEXP_LIKE()e prende le stesse bandiere.
Ad esempio:

In questo esempio, c'è una corrispondenza e la sottostringa inizia alla posizione 1.
REGEXP_REPLACE()
La sintassi per REGEXP_REPLACE() la funzione è:
REGEXP_REPLACE(expr, pat, repl[, pos[, occurrence[, match_type]]])
La funzione sostituisce ogni occorrenza in expr stringa specificata da pat modello con il repl string e restituisce la stringa risultante. Se c'è una corrispondenza, l'output è l'intera stringa con le sostituzioni. Se non c'è corrispondenza, l'output è l'originale expr corda. Se un argomento è NULL , l'output è NULL .
Il REGEXP_REPLACE() facoltativo gli argomenti sono:
pos- La posizione inexprdove iniziare la ricerca. Se omesso, il valore predefinito è 1.occurrence- Quale occorrenza di corrispondenza sostituire. Se omesso, il valore predefinito è 0 e sostituisce tutte le occorrenze.match_type- Specifica come abbinare. L'argomento è lo stesso diREGEXP_LIKE()e prende le stesse bandiere.
Ad esempio:

REGEXP_SUBSTR()
La sintassi per REGEXP_SUBSTR() la funzione è:
REGEXP_SUBSTR(expr, pat[, pos[, occurrence[, match_type]]])
La funzione restituisce la sottostringa di expr stringa che corrisponde all'espressione regolare specificata da pat modello. Se non c'è corrispondenza, il risultato è NULL . Se un argomento è NULL , l'output è NULL .
Gli argomenti facoltativi sono:
pos- La posizione inexprdove iniziare la ricerca. Se omesso, il valore predefinito è 1.occurrence- Quale occorrenza di corrispondenza sostituire. Se omesso, il valore predefinito è 1.match_type- Specifica come abbinare. L'argomento è lo stesso diREGEXP_LIKE()e prende le stesse bandiere.
Ad esempio:

In questo esempio, il risultato restituisce la sottostringa corrispondente dalla expr specificata stringa.
RIPETI()
La sintassi per REPEAT() la funzione è:
REPEAT(str,count)
La funzione restituisce una stringa che ripete il str stringa count volte. Se il count argomento è minore di 1, la funzione restituisce una stringa vuota. Se uno dei due argomenti è NULL , il risultato è NULL .
Ad esempio:

Nell'esempio sopra, la funzione restituisce una stringa composta da 'Lavoro ' stringa ripetuta sei volte.
SOSTITUIRE()
La sintassi per REPLACE() la funzione è:
REPLACE(str,from_str,to_str)
La funzione sostituisce tutte le istanze di from_str all'interno del str stringa con il to_str specificato corda. La funzione fa distinzione tra maiuscole e minuscole e multibyte sicura.
Ad esempio:

REVERSE()
La sintassi per REVERSE() la funzione è:
REVERSE(str)
La funzione restituisce il str stringa con un ordine dei caratteri invertito. REVERSE() è una funzione multibyte sicura.
Ad esempio:

DESTRA()
La sintassi per RIGHT() la funzione è:
RIGHT(str,len)
La funzione restituisce il len più a destra numero di caratteri da str corda. Se un argomento è NULL , il risultato è NULL . RIGHT() è una funzione multibyte sicura.
Ad esempio:

RPAD()
La sintassi per RPAD() la funzione è:
RPAD(str,len,padstr)
La funzione restituisce il str specificato stringa, riempita a destra con il padstr stringa, per una lunghezza di len caratteri. Il str argomento più lungo di len accorcia l'output a len caratteri.
RPAD() è multibyte sicuro.
Ad esempio:

RTRIM()
La sintassi per RTRIM() la funzione è:
RTRIM(str)
La funzione restituisce il str stringa senza gli spazi finali. Il RTRIM() la funzione è multibyte sicura.
Ad esempio:

SOUNDEX(), ovvero SUONA COME
La sintassi per SOUNDEX() la funzione è:
SOUNDEX(str)
La funzione emette una stringa soundex, ovvero una rappresentazione fonetica dell'input str corda. Il SOUNDEX() la funzione consente agli utenti di confrontare le parole inglesi che sono scritte in modo diverso ma suonano allo stesso modo.
SOUNDEX() ignores all non-alphabetic characters in the input string and treats all characters outside the A-Z range as vowels.
Importante: The SOUNDEX() function works well only with strings in English. Results are unreliable for strings in other languages and for strings that use multibyte character sets, including utf-8.
Ad esempio:

The (expr1) SOUNDS LIKE (expr2) function is the same as SOUNDEX(expr1) = SOUNDEX(expr2) .
SPACE()
The syntax for the SPACE() function is:
SPACE(N)
The function outputs a string consisting of N number of space characters.
Ad esempio:

STRCMP()
The syntax for the STRCMP() function is:
STRCMP(expr1,expr2)The function compares the two expressions and outputs:
0- If the two expressions are the same.-1- If the first expression is smaller than the second depending on the current sort order.1- If the second expression is smaller than the first one.
Ad esempio:

In this example, the output is 1 because the second argument is smaller than the first one.
SUBSTRING(), i.e., SUBSTR(), MID()
The syntax for the SUBSTRING() function is:
SUBSTRING(str, pos, length)oppure:
SUBSTRING(str FROM pos FOR length)The function extracts a substring from a string, starting at a specified position.
The length argument is optional and used to return a substring length characters long from the str string, starting at pos position.
The pos argument specifies from which position to extract the substring. If pos is a positive number, the function extracts a substring from the beginning of the string. If pos is a negative number, the function extracts a substring from the end of the string.
Ad esempio:

MID(str,pos,length) and SUBSTR() are synonyms for SUBSTRING(str,pos,length) .
SUBSTRING_INDEX()
The syntax for the SUBSTRING_INDEX() function is:
SUBSTRING_INDEX(str,delim,count)
The function outputs a substring from the str string before a specified count number of delim delimiter occurs.
If the count argument is positive, the function outputs everything left of the final delimiter, counting from the left side.
If the count argument is negative, the function outputs everything right of the final delimiter, counting from the right side.
SUBSTRING_INDEX() searches for the delimiter in a case-sensitive fashion, and it is multibyte safe.
Ad esempio:
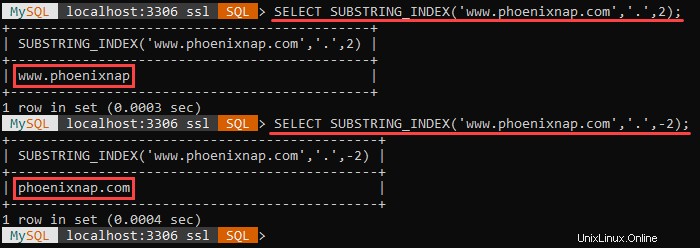
The example above shows the different outputs when the count argument is positive and negative.
TO_BASE64()
The syntax for the TO_BASE64() function is:
TO_BASE64(str)The function encodes a string argument to a base-64 encoded form and returns the result. If the argument isn't a string, the function converts it to a string before base-64 encoding.
If the argument is NULL , the result is NULL .
TO_BASE64() is the reverse of FROM_BASE64() .
Ad esempio:

The output is a base-64 encoded string.
TRIM()
The syntax for the TRIM() function is:
TRIM([{BOTH | LEADING | TRAILING} [remstr] FROM] str)
The function removes all remstr prefixes and suffixes from the specified str string and outputs the result.
Unless specifying the BOTH, LEADING ,or TRAILING specifiers, the function assumes BOTH .
The remstr argument is optional, and omitting it removes the space characters from the string.
TRIM() is multibyte safe.
Ad esempio:

In this example, the function removes the specified leading prefix from the string.
UPPER(), i.e., UCASE()
The syntax for the UPPER() function is:
UPPER(str)
The function changes all characters of the specified str string to uppercase and outputs the result. The default character set mapping it uses is utf8mb4. UPPER() is multibyte safe.
Ad esempio:

The UCASE() function is a synonym for UPPER() .
UNHEX()
The syntax for the UNHEX() function is:
UNHEX(str)The function interprets each pair of characters in a string argument as a hexadecimal number and converts it to the byte represented by the number. The output is a binary result.
If the str argument contains non-hexadecimal digits, the output is NULL . A NULL output can also occur if the argument is a BINARY colonna.
UNHEX() is the opposite of HEX() . However, you shouldn't use UNHEX() to inverse the HEX() result of numeric arguments. Instead, use the mathematical function CONV(HEX(N),16,10) .
Ad esempio:

WEIGHT_STRING()
The syntax for the WEIGHT_STRING() function is:
WEIGHT_STRING(str [AS {CHAR|BINARY}(N)] [flags])str- The input string argument.AS- Optional clause, permits casting the input string to a binary or non-binary string, and to a specific length.flags- Optional argument, currently unused.
The function outputs the weight string for the input str corda. The output value represents the string's sorting and comparison value.
If used, the AS BINARY(N) argument measures the length in bytes rather than characters, and right-pads with 0x00 bytes to the specified length.
On the other hand, the AS CHAR(N) argument measures the characters' length and right-pads with spaces to the specified length.
N has a minimum value of 1. If N is less than the input string length, the string is truncated without issuing a warning.
If the input string is a non-binary value (CHAR , VARCHAR , or TEXT ) , the output contains the collation weights for the string. If the input string is a binary value (BINARY , VARBINARY , or BLOB ), the output is the same as the input string because the weight for each byte in a binary string is the byte value.
If the input string is NULL , the output is NULL .
Important:WEIGHT_STRING() is a debugging function intended for internal use and collation testing and debugging. Its behavior is subject to change between different MySQL versions.
Ad esempio:

In this example, we used HEX() to display the output because HEX() can display binary results containing nonprinting values in a printable form.