Cos'è Apache Kafka?
Kafka è un sistema di messaggistica che raccoglie ed elabora grandi quantità di dati in tempo reale, rendendolo un componente di integrazione vitale per le applicazioni in esecuzione in un cluster Kubernetes. L'efficienza delle applicazioni distribuite in un cluster può essere ulteriormente aumentata con una piattaforma di streaming di eventi come Apache Kafka .
Questo tutorial approfondito mostra come configurare un server Kafka su un cluster Kubernetes.

Come funziona Apache Kafka?
Apache Kafka si basa su un modello di pubblicazione-abbonamento:
- Produttori produrre messaggi e pubblicarli su argomenti .
- Kafka classifica i messaggi in argomenti e li memorizza in modo che siano immutabili.
- I consumatori si iscrivono a un argomento specifico e assorbire i messaggi forniti dai produttori.
Produttori e consumatori in questo contesto rappresentano applicazioni che producono messaggi basati su eventi e applicazioni che consumano tali messaggi. I messaggi sono archiviati sui broker Kafka, ordinati per argomenti definiti dall'utente .
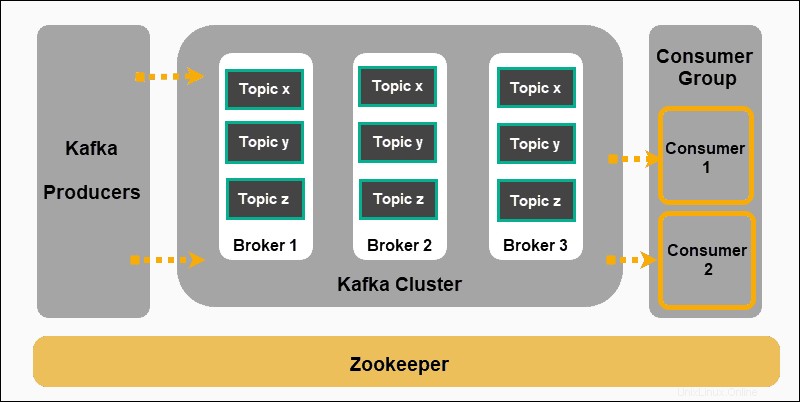
Zookeeper è un componente indispensabile di una configurazione Kafka. Coordina i produttori Kafka, i broker, i consumatori e le iscrizioni ai cluster.
Distribuisci Zookeeper
Kafka non può funzionare senza Zookeeper. Il servizio Kafka continua a riavviarsi finché non viene rilevata una distribuzione Zookeeper funzionante.
Distribuisci Zookeeper in anticipo, creando un file YAML zookeeper.yml . Questo file avvia un servizio e una distribuzione che pianificano i pod Zookeeper su un cluster Kubernetes.
Usa il tuo editor di testo preferito per aggiungere i seguenti campi a zookeeper.yml :
apiVersion: v1
kind: Service
metadata:
name: zk-s
labels:
app: zk-1
spec:
ports:
- name: client
port: 2181
protocol: TCP
- name: follower
port: 2888
protocol: TCP
- name: leader
port: 3888
protocol: TCP
selector:
app: zk-1
---
kind: Deployment
apiVersion: extensions/v1beta1
metadata:
name: zk-deployment-1
spec:
template:
metadata:
labels:
app: zk-1
spec:
containers:
- name: zk1
image: bitnami/zookeeper
ports:
- containerPort: 2181
env:
- name: ZOOKEEPER_ID
value: "1"
- name: ZOOKEEPER_SERVER_1
value: zk1
Esegui il comando seguente sul tuo cluster Kubernetes per creare il file di definizione:
kubectl create -f zookeeper.ymlCrea servizio Kafka
Ora dobbiamo creare un file di definizione del servizio Kafka. Questo file gestisce le distribuzioni di Kafka Broker bilanciando il carico dei nuovi pod Kafka. Un kafka-service.yml di base contiene i seguenti elementi:
apiVersion: v1
kind: Service
metadata:
labels:
app: kafkaApp
name: kafka
spec:
ports:
-
port: 9092
targetPort: 9092
protocol: TCP
-
port: 2181
targetPort: 2181
selector:
app: kafkaApp
type: LoadBalancer
Una volta salvato il file, crea il servizio inserendo il seguente comando:
kubectl create -f kafka-service.ymlDefinisci Kafka Replication Controller
Crea un ulteriore .yml file per fungere da controller di replica per Kafka. Un file del controller di replica, nel nostro esempio kafka-repcon.yml, contiene i seguenti campi:
---
apiVersion: v1
kind: ReplicationController
metadata:
labels:
app: kafkaApp
name: kafka-repcon
spec:
replicas: 1
selector:
app: kafkaApp
template:
metadata:
labels:
app: kafkaApp
spec:
containers:
-
command:
- zookeeper-server-start.sh
- /config/zookeeper.properties
image: "wurstmeister/kafka"
name: zk1
ports:
-
containerPort: 2181
Salvare il file di definizione del controller di replica e crearlo utilizzando il comando seguente:
kubectl create -f kafka-repcon.ymlAvvia Kafka Server
Le proprietà di configurazione per un server Kafka sono definite in config/server.properties file. Poiché abbiamo già configurato il server Zookeeper, avvia il server Kafka con:
kafka-server-start.sh config/server.propertiesCome creare un argomento Kafka
Kafka ha un'utilità da riga di comando chiamata kafka-topics.sh . Utilizzare questa utilità per creare argomenti sul server. Apri una nuova finestra di terminale e digita:
kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic Topic-NameAbbiamo creato un argomento chiamato Nome-argomento con una singola partizione e un'istanza di replica.
Come avviare un produttore Kafka
config/server.properties contiene l'ID della porta del broker. Il broker nell'esempio è in ascolto sulla porta 9092. È possibile specificare la porta in ascolto direttamente utilizzando la riga di comando:
kafka-console-producer.sh --topic kafka-on-kubernetes --broker-list localhost:9092 --topic Topic-Name Ora usa il terminale per aggiungere diverse righe di messaggi.
Come avviare un consumatore Kafka
Come per le proprietà Producer, le impostazioni Consumer predefinite sono specificate in config/consumer.properties file. Apri una nuova finestra di terminale e digita il comando per consumare i messaggi:
kafka-console-consumer.sh --topic Topic-Name --from-beginning --zookeeper localhost:2181
Il --from-beginning comando elenca i messaggi in ordine cronologico. Ora puoi inserire messaggi dal terminale del produttore e vederli apparire nel terminale del consumatore.
Come scalare un cluster Kafka
Usa il terminale di comando e amministra direttamente il Kafka Cluster usando kubectl . Immettere il comando seguente e ridimensionare rapidamente il cluster Kafka aumentando il numero di pod da uno (1) a sei (6):
kubectl scale rc kafka-rc --replicas=6