In realtà è piuttosto semplice, almeno se non hai bisogno dei dettagli di implementazione.
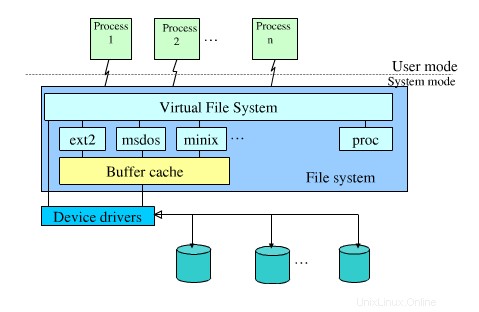
Prima di tutto, su Linux tutti i file system (ext2, ext3, btrfs, reiserfs, tmpfs, zfs, ...) sono implementati nel kernel. Alcuni possono scaricare il lavoro sul codice utente tramite FUSE, e alcuni si presentano solo sotto forma di un modulo del kernel (ZFS nativo è un esempio notevole di quest'ultimo a causa delle restrizioni di licenza), ma in entrambi i casi rimane un componente del kernel. Questa è una base importante.
Quando un programma vuole leggere da un file, emetterà varie chiamate alla libreria di sistema che alla fine finiscono nel kernel sotto forma di open() , read() , close() sequenza (possibilmente con seek() gettato per buona misura). Il kernel prende il percorso e il nome del file forniti e, attraverso il file system e il livello di I/O del dispositivo, li traduce in richieste di lettura fisiche (e in molti casi anche richieste di scrittura, ad esempio aggiornamenti atime) in un archivio sottostante.
Tuttavia, non è necessario tradurre tali richieste in modo specifico in fisico, persistente archiviazione . Il contratto del kernel prevede che l'emissione di quel particolare insieme di chiamate di sistema fornisca il contenuto del file in questione . Il punto esatto in cui esiste il "file" nel nostro regno fisico è secondario rispetto a questo.
Su /proc di solito viene montato ciò che è noto come procfs . Questo è un tipo di file system speciale, ma poiché è un file system, in realtà non è diverso da ad es. un ext3 file system montato da qualche parte. Quindi la richiesta viene passata al codice del driver del file system procfs, che conosce tutti questi file e directory e restituisce particolari informazioni dalle strutture dati del kernel .
Il "livello di archiviazione" in questo caso sono le strutture dati del kernel e procfs fornisce un'interfaccia pulita e comoda per accedervi. Tieni presente che montare procfs a /proc è semplicemente convenzione; potresti facilmente montarlo altrove. In effetti, a volte ciò viene fatto, ad esempio nelle chroot jail quando il processo in esecuzione ha bisogno di accedere a /proc per qualche motivo.
Funziona allo stesso modo se scrivi un valore in un file; a livello di kernel, che si traduce in una serie di open() , seek() , write() , close() chiamate che vengono nuovamente passate al driver del file system; di nuovo, in questo caso particolare, il codice procfs.
Il motivo particolare per cui vedi file restituendo empty è che molti dei file esposti da procfs sono esposti con una dimensione di 0 byte. La dimensione di 0 byte è probabilmente un'ottimizzazione sul lato del kernel (molti dei file in /proc sono dinamici e possono facilmente variare in lunghezza, possibilmente anche da una lettura all'altra, e il calcolo della lunghezza di ogni file su ogni directory letta sarebbe potenzialmente molto costoso). Seguendo i commenti a questa risposta, che puoi verificare sul tuo sistema eseguendo strace o uno strumento simile, file prima emette un stat() chiama per rilevare eventuali file speciali e quindi coglie l'opportunità, se la dimensione del file è riportata come 0, di interrompere e segnalare il file come vuoto.
Questo comportamento è effettivamente documentato e può essere override specificando -s o --special-files sul file invocazione, sebbene, come affermato nella pagina del manuale, ciò possa avere effetti collaterali. La citazione di seguito è tratta dalla pagina man del file BSD 5.11, datata 17 ottobre 2011.
Normalmente, file tenta solo di leggere e determinare il tipo di file di argomenti che stat(2) riporta come file ordinari. Questo previene problemi, perché la lettura di file speciali può avere conseguenze peculiari. Specificando il
-sL'opzione fa in modo che file legga anche i file degli argomenti che sono file speciali a blocchi o caratteri. Ciò è utile per determinare i tipi di filesystem dei dati nelle partizioni del disco non elaborato, che sono file speciali a blocchi. Questa opzione fa anche in modo che il file ignori la dimensione del file come riportato da stat(2) poiché su alcuni sistemi riporta una dimensione zero per le partizioni del disco grezzo.
In questa directory, puoi controllare come il kernel visualizza i dispositivi, regolare le impostazioni del kernel, aggiungere dispositivi al kernel e rimuoverli di nuovo. In questa directory è possibile visualizzare direttamente l'utilizzo della memoria e le statistiche di I/O.
Puoi vedere quali dischi sono montati e quali file system sono utilizzati. In breve, ogni singolo aspetto del tuo sistema Linux può essere esaminato da questa directory, se sai cosa cercare.
Il /proc directory non è una directory normale. Se dovessi eseguire l'avvio da un CD di avvio e guardare quella directory sul tuo disco rigido, la vedresti vuota. Quando lo guardi sotto il tuo normale sistema in esecuzione può essere abbastanza grande. Tuttavia, non sembra utilizzare spazio su disco rigido. Questo perché è un file system virtuale.
Dal momento che il /proc il file system è un file system virtuale e risiede in memoria, un nuovo /proc il file system viene creato ogni volta che la macchina Linux si riavvia.
In altre parole, è solo un mezzo per sbirciare e frugare facilmente nelle viscere del sistema Linux attraverso un'interfaccia di tipo file e directory. Quando guardi un file nel formato /proc directory, stai osservando direttamente un intervallo di memoria nel kernel di Linux e vedendo quello che può vedere.
I livelli nel file system
Esempi:
- Dentro
/proc, esiste una directory per ogni processo in esecuzione, denominata con il relativo ID processo. Queste directory contengono file che contengono informazioni utili sui processi, come:exe:che è un collegamento simbolico al file su disco da cui è stato avviato il processo.cwd:che è un collegamento simbolico alla directory di lavoro del processo.wchan:che, una volta letto, restituisce il canale in attesa su cui si trova il processo.maps:che, quando letta, restituisce le mappe di memoria del processo.
/proc/uptimerestituisce il tempo di attività come due valori decimali in secondi, separati da uno spazio:- la quantità di tempo dall'avvio del kernel.
- la quantità di tempo in cui il kernel è rimasto inattivo.
/proc/interrupts:Per informazioni relative agli interrupt./proc/modules:Per un elenco di moduli.
Per informazioni più dettagliate vedere man proc o kernel.org.
Hai ragione, non sono file reali.
In termini più semplici, è un modo per parlare con il kernel usando i normali metodi di lettura e scrittura di file, invece di chiamare direttamente il kernel. È in linea con la filosofia "tutto è un file" di Unix.
I file in /proc non esistono fisicamente da nessuna parte, ma il kernel reagisce ai file che leggi e scrivi al suo interno e, invece di scrivere nella memoria, riporta informazioni o fa qualcosa.
Allo stesso modo, i file in /dev non sono realmente file nel senso tradizionale (sebbene su alcuni sistemi i file in /dev possono effettivamente esistere su disco, non avranno molto altro oltre al dispositivo a cui si riferiscono) - ti consentono di parlare con un dispositivo utilizzando la normale API I/O di file Unix - o qualsiasi cosa che la utilizzi, come le shell