Per organizzare i dati come lista collegata usando struct list_head devi dichiarare list root e dichiarare la voce dell'elenco per il collegamento. Entrambe le voci radice e figlio sono dello stesso tipo (struct list_head ). children voce di struct task_struct la voce è un root . sibling voce di struct task_struct è un list entry . Per vedere le differenze, devi leggere il codice, dove children e sibling sono usati. Utilizzo di list_for_each per children significa cosa children è un root . Utilizzo di list_entry per sibling significa cosa sibling è un list entry .
Puoi leggere di più sugli elenchi dei kernel Linux qui.
Domanda :Qual è il motivo per cui stiamo passando "sibling" qui che alla fine un elenco diverso con offset diverso?
Risposta:
Se l'elenco è stato creato in questo modo:
list_add(&subtask->sibling, ¤t->children);
Di
list_for_each(list, ¤t->children)
Inizializzerà i puntatori di elenco a sibling , quindi devi usare subling come parametro per list_entry. Ecco come il kernel Linux elenca le API progettate.
Ma, se l'elenco è stato creato in un altro (errato ) modo:
list_add(&subtask->children, ¤t->sibling);
Quindi devi iterare l'elenco in questo modo (sbagliato ) modo:
list_for_each(list, ¤t->sibling)
E ora devi usare children come parametro per list_entry .
Spero, questo aiuta.
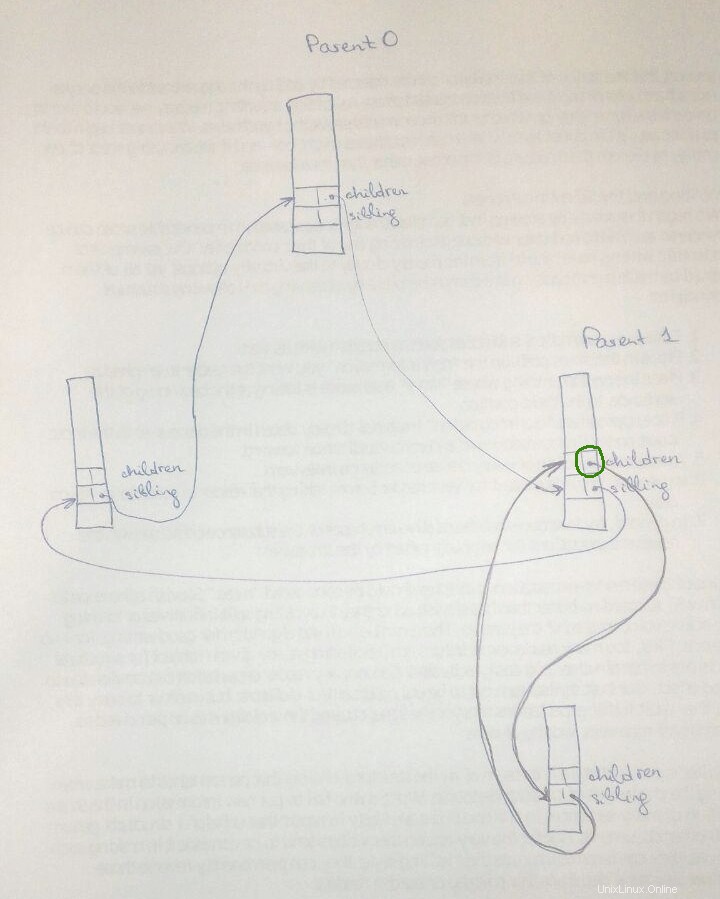
Di seguito la rappresentazione pittorica che potrebbe aiutare qualcuno in futuro. La casella in alto rappresenta un genitore, e le due caselle in basso sono i suoi figli

Ecco un'immagine in aggiunta alle risposte precedenti. Lo stesso processo può essere sia genitore che figlio (come Genitore1 nell'immagine) e dobbiamo distinguere tra questi due ruoli.
Intuitivamente, se children di Parent0 punterebbe a children di Parent1, quindi Parent0.children.next->next (cerchio verde sull'immagine), che è lo stesso di Parent1.children.next , indicherebbe un figlio di Parent1 invece di un figlio successivo di Parent0.