Risposta breve
99 sarà il vincitore per la priorità in tempo reale.
PR è il livello di priorità (intervallo da -100 a 39). Più basso è il PR, maggiore sarà la priorità del processo.
PR è calcolato come segue:
- per processi normali:PR =20 + NI (NI è bello e va da -20 a 19)
- per i processi in tempo reale:PR =- 1 - real_time_priority(real_time_priority varia da 1 a 99)
Risposta lunga
Ci sono 2 tipi di processi, il normale quelli e il tempo reale Per quelli normali (e solo per quelli), nice si applica come segue:
Bello
La scala della "gentilezza" va da -20 a 19, mentre -20 è la priorità più alta e 19 la priorità più bassa. Il livello di priorità è calcolato come segue:
PR =20 + NI
Dove NI è il bel livello e PR è il livello di priorità. Quindi, come possiamo vedere, il -20 è effettivamente mappato su 0, mentre il 19 è mappato su 39.
Per impostazione predefinita, un valore nice del programma è 0 bit, è possibile per un utente root avviare programmi con un valore nice specificato utilizzando il seguente comando:
nice -n <nice_value> ./myProgram
Tempo reale
Potremmo andare ancora oltre. La bella priorità viene effettivamente utilizzata per i programmi utente. Mentre la priorità generale UNIX/LINUX ha un intervallo di 140 valori, nice value consente al processo di mappare l'ultima parte dell'intervallo (da 100 a 139). Questa equazione lascia i valori da 0 a 99 irraggiungibili che corrisponderanno a un livello PR negativo (da -100 a -1). Per poter accedere a tali valori, il processo dovrebbe essere dichiarato "tempo reale".
Esistono 5 criteri di pianificazione in un ambiente LINUX che possono essere visualizzati con il seguente comando:
chrt -m
Che mostrerà il seguente elenco:
1. SCHED_OTHER the standard round-robin time-sharing policy
2. SCHED_BATCH for "batch" style execution of processes
3. SCHED_IDLE for running very low priority background jobs.
4. SCHED_FIFO a first-in, first-out policy
5. SCHED_RR a round-robin policy
I processi di schedulazione possono essere divisi in 2 gruppi, le normali politiche di schedulazione (da 1 a 3) e le politiche di schedulazione in tempo reale (4 e 5). I processi in tempo reale avranno sempre la priorità sui processi normali. È possibile chiamare un processo in tempo reale utilizzando il seguente comando (l'esempio è come dichiarare una policy SCHED_RR):
chrt --rr <priority between 1-99> ./myProgram
Per ottenere il valore PR per un processo in tempo reale viene applicata la seguente equazione:
PR =-1 - rt_prior
Dove rt_prior corrisponde alla priorità tra 1 e 99. Per questo motivo il processo che avrà la priorità maggiore rispetto agli altri processi sarà quello chiamato con il numero 99.
È importante notare che per i processi in tempo reale, il valore nice non viene utilizzato.
Per vedere l'attuale "gentilezza" e il valore PR di un processo può essere eseguito il seguente comando:
top
Che mostra il seguente output:
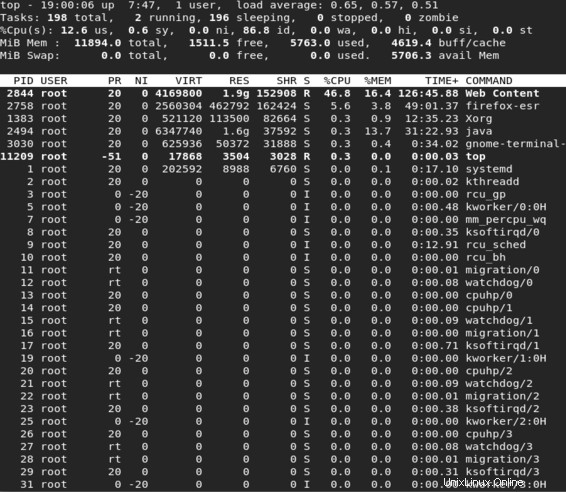
Nella figura sono visualizzati i valori PR e NI. È bene notare il processo con valore PR -51 che corrisponde ad un valore in tempo reale. Ci sono anche alcuni processi il cui valore PR è indicato come "rt". Questo valore corrisponde effettivamente a un valore PR di -100.
Questo commento in sched.h è abbastanza definitivo:
/*
* Priority of a process goes from 0..MAX_PRIO-1, valid RT
* priority is 0..MAX_RT_PRIO-1, and SCHED_NORMAL/SCHED_BATCH
* tasks are in the range MAX_RT_PRIO..MAX_PRIO-1. Priority
* values are inverted: lower p->prio value means higher priority.
*
* The MAX_USER_RT_PRIO value allows the actual maximum
* RT priority to be separate from the value exported to
* user-space. This allows kernel threads to set their
* priority to a value higher than any user task. Note:
* MAX_RT_PRIO must not be smaller than MAX_USER_RT_PRIO.
*/
Nota questa parte:
I valori di priorità sono invertiti:inferiore p->prio valore significa priorità più alta .
Ho fatto un esperimento per risolvere questo problema, come segue:
-
processo1:priorità RT =40, affinità CPU =CPU 0. Questo processo "gira" per 10 secondi in modo da non consentire l'esecuzione di alcun processo con priorità inferiore sulla CPU 0.
-
process2:priorità RT =39, affinità CPU =CPU 0. Questo processo stampa un messaggio su stdout ogni 0,5 secondi, dormendo nel mezzo. Stampa il tempo trascorso con ogni messaggio.
Sto eseguendo un kernel 2.6.33 con la patch PREEMPT_RT.
Per eseguire l'esperimento, eseguo process2 in una finestra (come root) e quindi avvio process1 (come root) in un'altra finestra. Il risultato è che process1 sembra anticipare process2, non permettendogli di essere eseguito per 10 secondi interi.
In un secondo esperimento, cambio la priorità RT di process2 a 41. In questo caso, process2 not anticipato da process1.
Questo esperimento mostra che un più grande Valore priorità RT in sched_setscheduler() ha una priorità più alta. Questo sembra contraddire ciò che Michael Foukarakis ha sottolineato da sched.h, ma in realtà non è così. In sched.c nel sorgente del kernel, abbiamo:
static void
__setscheduler(struct rq *rq, struct task_struct *p, int policy, int prio)
{
BUG_ON(p->se.on_rq);
p->policy = policy;
p->rt_priority = prio;
p->normal_prio = normal_prio(p);
/* we are holding p->pi_lock already */
p->prio = rt_mutex_getprio(p);
if (rt_prio(p->prio))
p->sched_class = &rt_sched_class;
else
p->sched_class = &fair_sched_class;
set_load_weight(p);
}
rt_mutex_getprio(p) fa quanto segue:
return task->normal_prio;
Mentre normal_prio() capita di fare quanto segue:
prio = MAX_RT_PRIO-1 - p->rt_priority; /* <===== notice! */
...
return prio;
In altre parole, abbiamo (la mia interpretazione):
p->prio = p->normal_prio = MAX_RT_PRIO - 1 - p->rt_priority
Oh! Questo è fonte di confusione! Per riassumere:
-
Con p->prio, un valore minore prevale su un valore maggiore.
-
Con p->rt_priority, un valore maggiore prevale su un valore minore. Questa è la priorità in tempo reale impostata utilizzando
sched_setscheduler().