 Logstash è un'applicazione di gestione dei file di registro centralizzata open source.
Logstash è un'applicazione di gestione dei file di registro centralizzata open source.
Puoi raccogliere registri da più server, più applicazioni, analizzare quei registri e archiviarli in una posizione centrale. Una volta archiviato, puoi utilizzare una GUI Web per cercare i registri, eseguire il drill-down dei registri e generare vari rapporti.
Questo tutorial spiegherà i fondamenti di logstash e tutto ciò che devi sapere su come installare e configurare logstash sul tuo sistema.
1. Scarica Logstatsh Binary
Logstash fa parte della famiglia elasticsearch. Scaricalo dal sito Web di logstash qui. Tieni presente che dovresti avere java installato sul tuo computer affinché funzioni.
oppure usa curl per scaricarlo direttamente dal sito web.
wget https://download.elasticsearch.org/logstash/logstash/logstash-1.4.2.tar.gz tar zxvf logstash-1.4.2.tar.gz cd logstash-1.4.2
Nota:in seguito installeremo logstash utilizzando yum. Per ora, inizialmente scaricheremo manualmente il binario per verificare come funziona dalla riga di comando.
2. Logstash Specifica le opzioni nella riga di comando
Per comprendere le basi di logstash, a scopo di test, controlliamo rapidamente alcune cose dalla riga di comando.
Esegui il logstash dalla riga di comando come mostrato di seguito. Quando richiesto, digita semplicemente "hello world" come input.
# bin/logstash -e 'input { stdin { } } output { stdout {} }'
hello world
2014-07-06T17:27:25.955+0000 base hello world Nell'output sopra, la prima riga è il "hello world" che abbiamo inserito usando stdin.
La seconda riga è l'output che logstash visualizzato utilizzando lo stdout. Fondamentalmente, sputa fuori tutto ciò che abbiamo inserito nello stdin.
Si noti che la specifica del flag della riga di comando -e consente a Logstash di accettare una configurazione direttamente dalla riga di comando. Questo è molto utile per testare rapidamente le configurazioni senza dover modificare un file tra le iterazioni.
3. Modifica il formato di output usando il codec
Il codec rubydebug genererà i dati dell'evento Logstash utilizzando la libreria ruby-awesome-print.
Quindi, riconfigurando l'output "stdout" (aggiungendo un "codec"), possiamo modificare l'output di Logstash. Aggiungendo input, output e filtri alla tua configurazione, è possibile modificare i dati di registro in molti modi, al fine di massimizzare la flessibilità dei dati archiviati durante la query.
# bin/logstash -e 'input { stdin { } } output { stdout { codec => rubydebug } }'
hello world
{
"message" => "",
"@version" => "1",
"@timestamp" => "2014-07-06T17:40:48.775Z",
"host" => "base"
}
{
"message" => "hello world",
"@version" => "1",
"@timestamp" => "2014-07-06T17:40:48.776Z",
"host" => "base"
} 4. Scarica ElasticSearch
Ora che abbiamo visto come funziona Logstash, andiamo avanti di un altro passo. È ovvio che non possiamo passare manualmente l'input e l'output di everylog. Quindi superato questo problema dovremo installare un software chiamato Elasticsearch.
Scarica l'elasticsearch da qui.
Oppure, usa wget come mostrato di seguito.
curl -O https://download.elasticsearch.org/elasticsearch/elasticsearch/elasticsearch-1.4.0.tar.gz tar zxvf elasticsearch-1.4.0.tar.gz
Avvia il servizio elasticsearch come mostrato di seguito:
cd elasticsearch-1.4.0/ ./bin/elasticsearch
Nota:questo tutorial specifica l'esecuzione di Logstash 1.4.2 con Elasticsearch 1.4.0. Ogni versione di Logstash ha una versione consigliata di Elasticsearch da abbinare. Assicurati che le versioni corrispondano in base alla versione di Logstash in esecuzione.
5. Verifica ElasticSearch
Per impostazione predefinita elasticsearch viene eseguito sulla porta 9200.
A scopo di test, prenderemo comunque l'input dallo stdin (simile al nostro esempio precedente), ma l'output non verrà visualizzato sullo stdout. Invece, andrà su elasticsearch.
Per verificare elasticsearch, eseguiamo quanto segue. Quando richiede l'input, digita semplicemente "la roba da geek" come shoen di seguito.
# bin/logstash -e 'input { stdin { } } output { elasticsearch { host => localhost } }'
the geek stuff Dal momento che non vedremo l'output nello stdout, dovremmo guardare elasticsearch.
Vai al seguente URL:
http://localhost:9200/_search?pretty
Quanto sopra visualizzerà tutti i messaggi disponibili in elasticsearch. Dovresti vedere il messaggio che abbiamo inserito nel comando logstash sopra qui nell'output.
{
"took" : 4,
"timed_out" : false,
"_shards" : {
"total" : 5,
"successful" : 5,
"failed" : 0
},
"hits" : {
"total" : 9,
"max_score" : 1.0,
"hits" : [ {
"_index" : "logstash-2014.07.06",
"_type" : "logs",
"_id" : "G3uZPQCMQ6ed4joNCuseew",
"_score" : 1.0, "_source" : {"message":"the geek stuff","@version":"1","@timestamp":"2014-07-06T18:09:46.612Z","host":"base"}
} ]
} 6. Logstash Input, Output e Codec
Input, Output, Codec e Filtri sono al centro della configurazione di Logstash. Creando una pipeline di elaborazione degli eventi, Logstash è in grado di estrarre i dati rilevanti dai tuoi log e renderli disponibili a elasticsearch, al fine di interrogare i tuoi dati in modo efficiente.
Di seguito sono riportati alcuni degli input disponibili. Gli input sono il meccanismo per passare i dati di registro a Logstash
- file:legge da un file sul filesystem, proprio come il comando UNIX "tail -0a"
- syslog:ascolta sulla nota porta 514 i messaggi syslog e analizza secondo il formato RFC3164
- redis:legge da un server redis, utilizzando sia i canali redis che le liste redis. Redis viene spesso utilizzato come "broker" in un'installazione Logstash centralizzata, che accoda gli eventi Logstash da "mittenti" Logstash remoti.
- lumberjack:elabora gli eventi inviati nel protocollo lumberjack. Ora chiamato logstash-forwarder.
Di seguito sono riportati alcuni dei filtri. I filtri vengono utilizzati come dispositivi di elaborazione intermedi nella catena Logstash. Sono spesso combinati con condizionali per eseguire una determinata azione su un evento, se soddisfa criteri particolari.
- grok:analizza il testo arbitrario e lo struttura. Grok è attualmente il modo migliore in Logstash per analizzare i dati di registro non strutturati in qualcosa di strutturato e interrogabile. Con 120 modelli spediti incorporati in Logstash, è molto probabile che ne troverai uno che soddisfi le tue esigenze!
- mutate:il filtro di mutazione consente di apportare mutazioni generali ai campi. Puoi rinominare, rimuovere, sostituire e modificare i campi dei tuoi eventi.
- rilascia:elimina completamente un evento, ad esempio eventi di debug.
- clone:crea una copia di un evento, eventualmente aggiungendo o rimuovendo dei campi.
- geoip:aggiunge informazioni sulla posizione geografica degli indirizzi IP (e mostra incredibili grafici in kibana)
I seguenti sono alcuni dei codec. Gli output sono la fase finale della pipeline Logstash. Un evento può passare attraverso più output durante l'elaborazione, ma una volta che tutti gli output sono stati completati, l'evento ha terminato la sua esecuzione.
- ricerca elastica:se hai intenzione di salvare i tuoi dati in un formato efficiente, conveniente e facilmente interrogabile
- file:scrive i dati dell'evento su un file su disco.
- Grafite:invia i dati degli eventi alla grafite, un popolare strumento open source per archiviare e rappresentare graficamente le metriche
- statsd:un servizio che "ascolta le statistiche, come contatori e timer, inviate tramite UDP e invia aggregati a uno o più servizi di backend collegabili".
7. Usa il file di configurazione di Logstash
Ora è il momento di passare dalle opzioni della riga di comando al file di configurazione. Invece di specificare le opzioni nella riga di comando, puoi specificarle in un file .conf come mostrato di seguito:
# vi logstash-simple.conf
input { stdin { } }
output {
elasticsearch { host => localhost }
stdout { codec => rubydebug }
} Ora chiediamo al logstast di leggere il file di configurazione che abbiamo appena creato usando l'opzione -f come shoen di seguito. A scopo di test, questo utilizza ancora stdin e stdout. Quindi, digita un messaggio dopo aver inserito questo comando.
# bin/logstash -f logstash-simple.conf
This is Vadiraj
{
"message" => "This is Vadiraj",
"@version" => "1",
"@timestamp" => "2014-11-07T04:59:20.959Z",
"host" => "base.thegeekstuff.com"
} 8. Analizza il messaggio di input Apache Log
Ora, eseguiamo configurazioni un po' più avanzate. Elimina tutte le voci dal file logstash-simple.conf e aggiungi le seguenti righe:
# vi logstash-simple.conf
input { stdin { } }
filter {
grok {
match => { "message" => "%{COMBINEDAPACHELOG}" }
}
date {
match => [ "timestamp" , "dd/MMM/yyyy:HH:mm:ss Z" ]
}
}
output {
elasticsearch { host => localhost }
stdout { codec => rubydebug }
} Ora, esegui il comando logstash come mostrato di seguito:
# bin/logstash -f logstash-filter.conf
Ma, questa volta, incolla la seguente voce di file di log di apache di esempio come input.
# bin/logstash -f logstash-filter.conf "127.0.0.1 - - [11/Dec/2013:00:01:45 -0800] "GET /xampp/status.php HTTP/1.1" 200 3891 "http://cadenza/xampp/navi.php" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10.9; rv:25.0) Gecko/20100101 Firefox/25.0""
L'output di logstatsh sarà qualcosa di simile al seguente:
{
"message" => "127.0.0.1 - - [11/Dec/2013:00:01:45 -0800] \"GET /xampp/status.php HTTP/1.1\" 200 3891 \"http://cadenza/xampp/navi.php\" \"Mozilla/5.0 (Macintosh; Intel Mac OS X 10.9; rv:25.0) Gecko/20100101 Firefox/25.0\"",
"@version" => "1",
"@timestamp" => "2013-12-11T08:01:45.000Z",
"host" => "base.tgs.com",
"clientip" => "127.0.0.1",
"ident" => "-",
"auth" => "-",
"timestamp" => "11/Dec/2013:00:01:45 -0800",
"verb" => "GET",
"request" => "/xampp/status.php",
"httpversion" => "1.1",
"response" => "200",
"bytes" => "3891",
"referrer" => "\"http://cadenza/xampp/navi.php\"",
"agent" => "\"Mozilla/5.0 (Macintosh; Intel Mac OS X 10.9; rv:25.0) Gecko/20100101 Firefox/25.0\""
} Come puoi vedere dall'output sopra, il nostro input viene analizzato di conseguenza e tutti i valori vengono divisi e archiviati nei campi corrispondenti.
Il filtro grok ha estratto il log di Apache e si è suddiviso in bit utili in modo che in un secondo momento possiamo interrogare.
9. File di configurazione di Logstash per il registro degli errori di Apache
Crea il seguente file di configurazione logstash per il file error_log di Apache.
# vi logstash-apache.conf
input {
file {
path => "/var/log/httpd/error_log"
start_position => beginning
}
}
filter {
if [path] =~ "error" {
mutate { replace => { "type" => "apache_error" } }
grok {
match => { "message" => "%{COMBINEDAPACHELOG}" }
}
}
date {
match => [ "timestamp" , "dd/MMM/yyyy:HH:mm:ss Z" ]
}
}
output {
elasticsearch {
host => localhost
}
stdout { codec => rubydebug }
} Nel file di configurazione sopra:
- Il file di input è /var/log/httpd/error_log e la posizione iniziale sarà l'inizio del file.
- Filtra il file di input e rinomina (muta) qualsiasi cosa con errore come apache_error. grok creerà un apachelog combinato nella colonna del messaggio e i dati mostreranno il timestamp con il formato specificato.
- L'output verrà archiviato in elasticsearch in localhost e ripreso tramite stdout in formato ruby print con il codec => rubydebug
10. File di configurazione di Logstash sia per il registro degli errori di Apache che per il registro di accesso
Possiamo specificare la carta jolly per leggere tutti i file di registro con *_log come mostrato di seguito.
Ma dobbiamo anche modificare le condizioni di conseguenza per analizzare sia l'accesso che il registro degli errori come mostrato di seguito.
# vi logstash-apache.conf
input {
file {
path => "/var/log/httpd/*_log"
}
}
filter {
if [path] =~ "access" {
mutate { replace => { type => "apache_access" } }
grok {
match => { "message" => "%{COMBINEDAPACHELOG}" }
}
date {
match => [ "timestamp" , "dd/MMM/yyyy:HH:mm:ss Z" ]
}
} else if [path] =~ "error" {
mutate { replace => { type => "apache_error" } }
} else {
mutate { replace => { type => "random_logs" } }
}
}
output {
elasticsearch { host => localhost }
stdout { codec => rubydebug }
} 11. Imposta repository Yum aggiuntivi
Il test è finito. Ora sappiamo come funziona Logstash con elasticseach.
Installeremo quanto segue:
- logstash – Il nostro server di log centrale
- Elasticsearch – Per memorizzare i log
- Redis – Per il filtro
- Nginx – Per eseguire Kibana
- Kibana:è una bellissima dashboard della GUI e mette tutto insieme
Prima dell'installazione, configura i seguenti repository:
# cd /etc/yum.repos.d/ # vi /etc/yum.repos.d/logstash.repo [logstash] name=Logstash baseurl=http://packages.elasticsearch.org/logstash/1.4/centos gpgcheck=1 gpgkey=http://packages.elasticsearch.org/GPG-KEY-elasticsearch enabled=1 # vi /etc/yum.repos.d/elasticsearch.repo [elasticsearch] name=Elasticsearch baseurl=http://packages.elasticsearch.org/elasticsearch/1.4/centos gpgcheck=1 gpgkey=http://packages.elasticsearch.org/GPG-KEY-elasticsearch enabled=1
Inoltre, imposta il repository EPEL come discusso in precedenza.
12. Installa Elasticsearch, Nginx e Redis e Logstash
Innanzitutto aggiorna il sistema e quindi installa logstash insieme a elasticsearch, redis e nginx come mostrato di seguito:
yum clean all yum update -y yum install -y install elasticsearch redis nginx logstash
13. Installa Kibana
Installa Kibana per la dashboard come mostrato di seguito:
cd /opt/ wget https://download.elasticsearch.org/kibana/kibana/kibana-3.1.2.tar.gz tar -xvzf kibana-3.1.2.tar.gz mv kibana-3.1.2 /usr/share/kibana3
14. Configura Kibana
Dobbiamo dire a kibana di elasticsearch. Per questo, modifica il seguente config.js.
# vi /usr/share/kibana3/config.js elasticsearch: "http://log.thegeekstuff.com:9200"
All'interno del file sopra, cerca elasticsearch e cambia "dev.kanbier.lan" in quella riga nel tuo dominio (ad esempio:log.thegeekstuff.com)
15. Imposta Kibana per l'esecuzione da Nginx
Dobbiamo anche fare in modo che kibana venga eseguito dal server web nginx.
Aggiungi quanto segue a nginx.conf
server {
listen *:80 ;
server_name log.thegeekstuff.com;
access_log /var/log/nginx/kibana.myhost.org.access.log;
location / {
root /usr/share/kibana3;
index index.html index.htm;
} Inoltre, non dimenticare di impostare l'indirizzo IP appropriato del tuo server nel file redis.conf.
16. Configura il file di configurazione di Logstash
Ora dobbiamo creare un file di configurazione logstash simile al file di configurazione di esempio che abbiamo usato in precedenza.
Definiremo il percorso dei file di registro, quale porta ricevere i registri remoti e comunicheremo a logstash lo strumento elasticsearch.
# vi /etc/logstash/conf.d/logstash.conf
input {
file {
type => "syslogpath => [ "/var/log/*.log", "/var/log/messages", "/var/log/syslog" ]
sincedb_path => "/opt/logstash/sincedb-access"
}
redis {
host => "10.37.129.8"
type => "redis-input"
data_type => "list"
key => "logstash"
}
syslog {
type => "syslog"
port => "5544"
}
}
filter {
grok {
type => "syslog"
match => [ "message", "%{SYSLOGBASE2}" ]
add_tag => [ "syslog", "grokked" ]
}
}
output {
elasticsearch { host => "log.thegeekstuff.com" }
}" 17. Verifica e avvia Logstash, Elasticsearch, Redis e Nginx
Avvia tutti questi servizi come mostrato di seguito:
service elasticsearch start service logstash start service nginx start service redis start
18. Verifica la GUI web di Logstash
Apri un browser e vai al nome del server (host) utilizzato nel file di configurazione sopra. Ad esempio:log.thegeekstuff.com
Vedrai un grafico simile al seguente, da cui puoi manipolare, sfogliare, visualizzare in dettaglio tutti i file di registro raccolti dal logstash.
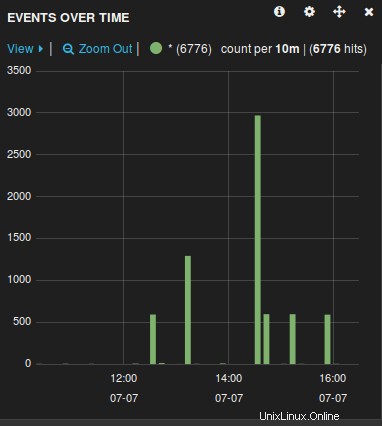
Ora che il server di log è pronto, devi solo inoltrare i file di log del server remoto gestiti da rsyslog a questo server centrale modificando il file rsyslog.conf.