Scrapy è un framework open source sviluppato in Python che permette di creare web spider o crawler per estrarre informazioni dai siti web in modo semplice e veloce.
Questa guida mostra come creare ed eseguire uno spider web con Scrapy sul tuo server per estrarre informazioni dalle pagine web attraverso l'uso di diverse tecniche.
Per prima cosa, connettiti al tuo server tramite una connessione SSH. Se non l'hai ancora fatto, ti consigliamo di seguire la nostra guida per connetterti in modo sicuro con SSH. Nel caso di un server locale, vai al passaggio successivo e apri il terminale del tuo server.
Creazione dell'ambiente virtuale
Prima di avviare l'installazione vera e propria, procedere con l'aggiornamento dei pacchetti di sistema:
$ sudo apt-get updateContinua installando alcune dipendenze necessarie per il funzionamento:
$ sudo apt-get install python-dev python-pip libxml2-dev zlib1g-dev libxslt1-dev libffi-dev libssl-devUna volta completata l'installazione, puoi iniziare a configurare virtualenv, un pacchetto Python che permette di installare i pacchetti Python in modo isolato, senza compromettere altri software. Sebbene sia facoltativo, questo passaggio è altamente raccomandato dagli sviluppatori di Scrapy:
$ sudo pip install virtualenvQuindi, prepara una directory per installare l'ambiente Scrapy:
$ sudo mkdir /var/scrapy
$ cd /var/scrapyE inizializzare un ambiente virtuale:
$ sudo virtualenv /var/scrapy
New python executable in /var/scrapy/bin/python
Installing setuptools, pip, wheel...
done.Per attivare l'ambiente virtuale, basta eseguire il seguente comando:
$ sudo source /var/scrapy/bin/activatePuoi uscire in qualsiasi momento tramite il comando "disattiva".
Installazione di Scrapy
Ora installa Scrapy e crea un nuovo progetto:
$ sudo pip install Scrapy
$ sudo scrapy startproject example
$ cd exampleNella directory del progetto appena creata, il file avrà la seguente struttura:
example/
scrapy.cfg # configuration file
example/ # module of python project
__init__.py
items.py
middlewares.py
pipelines.py
settings.py # project settings
spiders/
__init__.pyUtilizzo della shell a scopo di test
Scrapy permette di scaricare il contenuto HTML delle pagine web ed estrapolare informazioni da esse attraverso l'uso di diverse tecniche, come i selettori css. Per facilitare questo processo, Scrapy fornisce una "shell" per testare l'estrazione delle informazioni in tempo reale.
In questo tutorial, vedrai come catturare il primo post sulla pagina principale del famoso social Reddit:
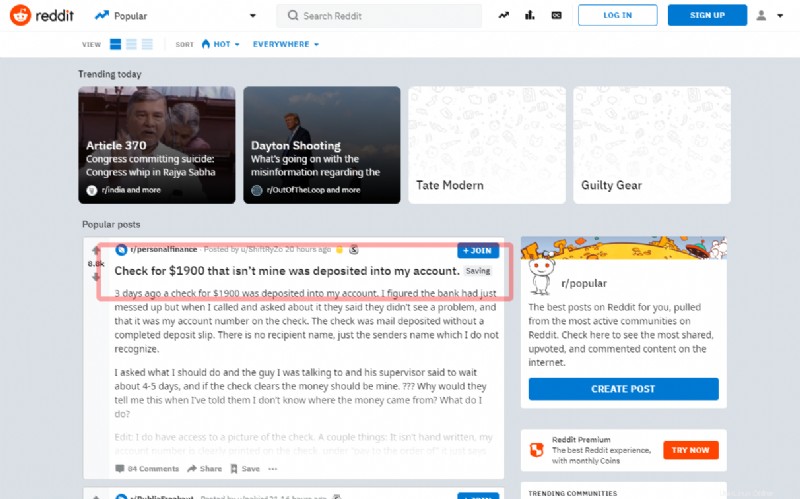
Prima di passare alla scrittura del sorgente, prova ad estrarre il titolo tramite la shell:
$ sudo scrapy shell "reddit.com"Entro pochi secondi, Scrapy avrà scaricato la pagina principale. Quindi, inserisci i comandi usando l'oggetto "risposta". Come, nell'esempio seguente, usa il selettore "articolo h3 ::testo":, per ottenere il titolo del primo post
>>> response.css('article h3::text')[0].get()Se il selettore funziona correttamente, verrà visualizzato il titolo. Quindi, esci dalla shell:
>>> exit()Per creare un nuovo spider, crea un nuovo file Python nella directory del progetto example / spiders / reddit.py:
import scrapy
class RedditSpider(scrapy.Spider):
name = "reddit"
def start_requests(self):
yield scrapy.Request(url="https://www.reddit.com/", callback=self.parseHome)
def parseHome(self, response):
headline = response.css('article h3::text')[0].get()
with open( 'popular.list', 'ab' ) as popular_file:
popular_file.write( headline + "\n" )Tutti gli spider ereditano la classe Spider del modulo Scrapy e avviano le richieste utilizzando il metodo start_requests:
yield scrapy.Request(url="https://www.reddit.com/", callback=self.parseHome)Quando Scrapy ha completato il caricamento della pagina, chiamerà la funzione di callback (self.parseHome).
Avendo l'oggetto risposta, il contenuto di tuo interesse può essere preso :
headline = response.css('article h3::text')[0].get()E, a scopo dimostrativo, salvalo in un file "popular.list".
Avvia lo spider appena creato usando il comando:
$ sudo scrapy crawl redditUna volta completato, l'ultimo titolo estratto si troverà nel file popular.list:
$ cat popular.listPianificazione di Scrapyd
Per programmare l'esecuzione dei tuoi spider, utilizza il servizio offerto da Scrapy "Scrapy Cloud" (vedi https://scrapinghub.com/scrapy-cloud ) oppure installa il demone open source direttamente sul tuo server .
Assicurati di essere nell'ambiente virtuale creato in precedenza e installa il pacchetto scrapyd tramite pip:
$ cd /var/scrapy/
$ sudo source /var/scrapy/bin/activate
$ sudo pip install scrapydUna volta completata l'installazione, prepara un servizio creando il file /etc/systemd/system/scrapyd.service con il seguente contenuto:
[Unit]
Description=Scrapy Daemon
[Service]
ExecStart=/var/scrapy/bin/scrapydSalva il file appena creato e avvia il servizio tramite:
$ sudo systemctl start scrapydOra il demone è configurato e pronto per accettare nuovi spider.
Per distribuire il tuo spider di esempio, devi utilizzare uno strumento, chiamato "scrapyd-client", fornito da Scrapy. Procedi con la sua installazione tramite pip:
$ sudo pip install scrapyd-clientContinua modificando il file scrapy.cfg e impostando i dati di distribuzione:
[settings]
default = example.settings
[deploy]
url = http://localhost:6800/
project = exampleOra, distribuisci semplicemente eseguendo il comando:
$ sudo scrapyd-deployPer programmare l'esecuzione dello spider, chiama l'API scrapyd:
$ sudo curl http://localhost:6800/schedule.json -d project=example -d spider=reddit