Se stai cercando una piattaforma di analisi dei dati in tempo reale, Jack Wallen pensa che Apache Druid sia difficile da battere. Scopri come rendere operativo questo strumento e quindi come caricare i dati di esempio.
Apache Druid è un database di analisi in tempo reale progettato per l'illuminazione di analisi rapide slice-and-dice su enormi set di dati. Puoi eseguire facilmente Apache Druid da una versione desktop di Linux o da un server Linux con una GUI e quindi caricare i dati per iniziare l'analisi.
Apache Druid include funzionalità come:
- Archiviazione orientata alla colonna
- Indici di ricerca nativi
- Streaming e importazione batch
- Schemi flessibili
- Partizionamento ottimizzato per il tempo
- Supporto SQL
- Scalabilità orizzontale
- Funzionamento semplice
Apache Druid è un'ottima opzione per i casi d'uso che richiedono l'importazione in tempo reale, query veloci e tempi di attività elevati.
Ti guiderò attraverso il processo di esecuzione di Apache Druid su Pop!_OS Linux (sebbene possa essere eseguito su qualsiasi distribuzione Linux) e poi ti mostrerò come caricare dati di esempio.
Di cosa avrai bisogno
Le uniche cose di cui avrai bisogno per farlo funzionare sono un'istanza in esecuzione di Linux completa di un ambiente desktop e un utente con privilegi sudo.
Questo è tutto. Facciamo un po' di magia nel database.
Come installare Java 8
Al momento, Apache Druid supporta solo Java 8, quindi dobbiamo assicurarci che sia installato e impostato come predefinito. Per installare Java 8 su una distribuzione desktop basata su Ubuntu, accedi alla macchina, apri una finestra del terminale ed esegui il comando:
sudo apt install openjdk-8-jdk -y
Al termine dell'installazione, è necessario impostare Java 8 come predefinito. Fallo con il comando:
sudo update-alternatives --config java
Dovresti vedere un elenco di tutte le versioni Java attualmente installate sulla macchina. Assicurati di selezionare il numero che corrisponde a Java 8.
Una parola sui servizi Apache Druid
Quello che lanceremo è una micro istanza di Apache Druid, che richiede 4 CPU e 16 GB di RAM. Esistono 6 diverse configurazioni di servizio per Apache Druid, che sono:
- Nano-Quickstart:1 CPU, 4GB RAM
- Micro-Quickstart:4 CPU, 16GB RAM
- Piccolo:8 CPU, 64 GB di RAM
- Medio:16 CPU, 128 GB RAM
- Grande:32 CPU, 256 GB di RAM
- X-Large:64 CPU, 512 GB RAM
A seconda della dimensione dei tuoi dati e delle tue esigenze. Quando si entra in enormi quantità di dati, si consiglia di distribuire Apache Druid come cluster. Tuttavia, dal momento che ci stiamo appena avvicinando ad Apache Druid, l'istanza micro andrà bene.
Copertura per sviluppatori da leggere
Come scaricare e decomprimere Apache Druid
Con Java installato, è ora di scaricare e decomprimere Apache Druid. Tornando alla finestra del terminale, scarica l'ultima versione (assicurati di controllare la pagina di download di Apache Druid per verificare che questa sia l'ultima versione) con il comando:
wget https://dlcdn.apache.org/druid/0.22.1/apache-druid-0.22.1-bin.tar.gz
Decomprimi il file scaricato con:
tar xvfz apache-druid-0.22.1-bin.tar.gz
Passa alla directory appena creata con:
cd apache-druid-0.22.1
Avvia il servizio con:
./bin/start-micro-quickstart
Il servizio Apache Druid dovrebbe avviarsi senza problemi. Tieni presente che non riavrai il tuo terminale mentre il servizio è in esecuzione finché non lo annulli con CTRL + C.
Come accedere alla console di Apache Druid
Sulla stessa macchina che esegue Apache Druid, apri un browser web e puntalo a http://localhost:8888 . Sfortunatamente, Apache Druid è configurato in modo tale da non poterlo raggiungere da una macchina remota, motivo per cui lo installiamo su una macchina desktop.
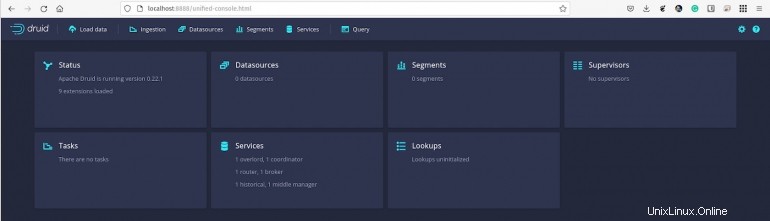
La console Apache Druid ti accoglierà (Figura A ).
Figura A
Come caricare i dati
Caricheremo un campione predefinito di dati, che si trova nella guida rapida/tutorial/directory. L'esempio si chiama wikiticker-2015-09-12-sampled.json.gz.
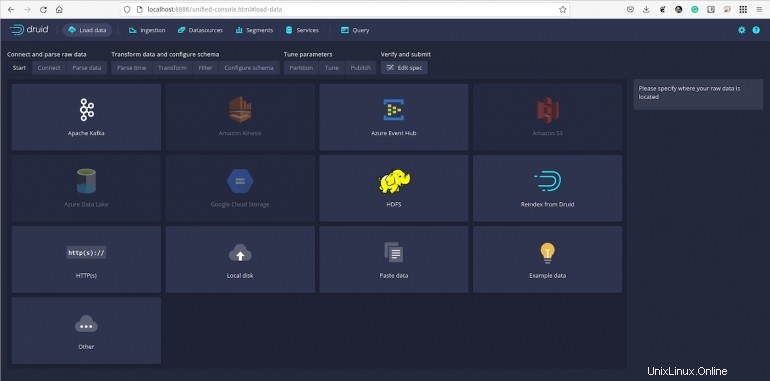
Figura B
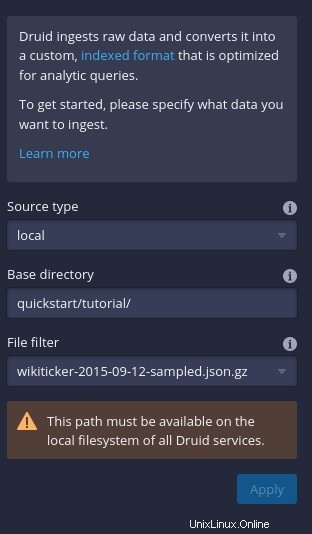
Fai clic su Connetti dati (sul lato destro della finestra) e poi, nella barra laterale risultante (Figura C ), digita quickstart/tutorial come directory di base e wikiticker-2015-09-12-sampled.json.gz nella sezione Filtro file.
Figura C
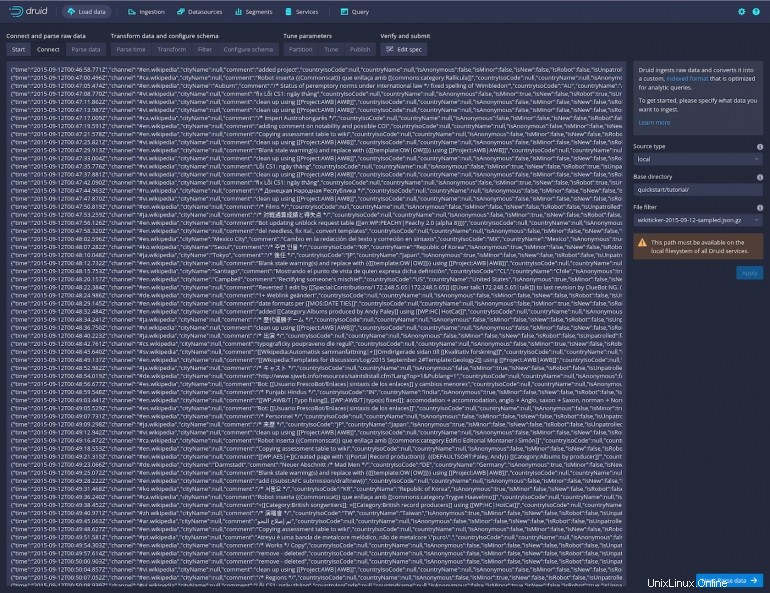
Fai clic su Applica e dovresti vedere una quantità abbastanza grande di dati apparire nella finestra principale (Figura D ).
Figura D
Fai clic su Avanti:analizza i dati in basso a destra e ti verrà presentato un elenco dei dati in un formato più leggibile (Figura E ).
Figura E
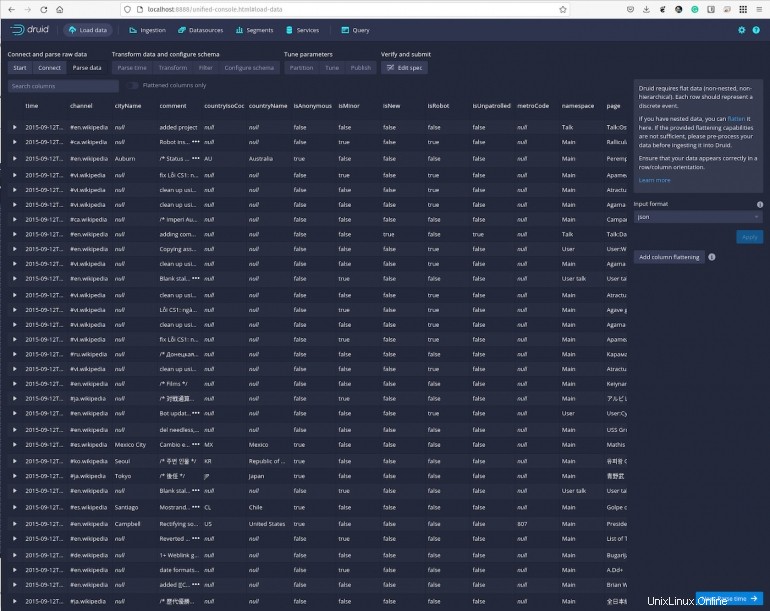
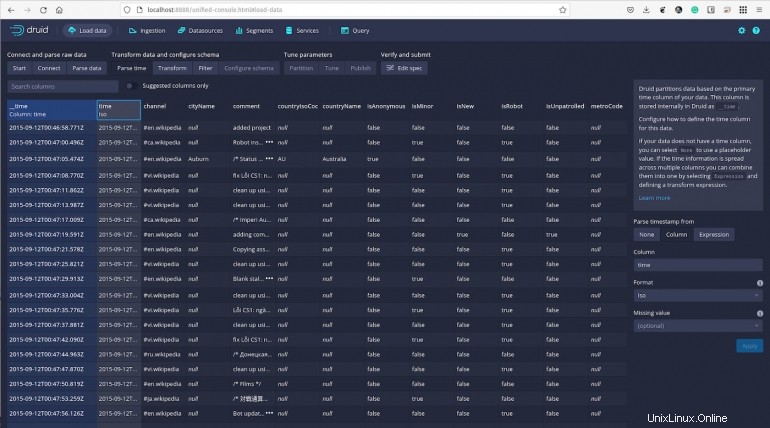
Fare clic su Avanti:analisi dell'ora e visualizzare i dati rispetto a determinati timestamp (Figura F ).
Figura F
Fai clic su Avanti:Trasforma e puoi quindi eseguire trasformazioni per riga dei valori delle colonne per creare nuove colonne o modificare quelle già esistenti.
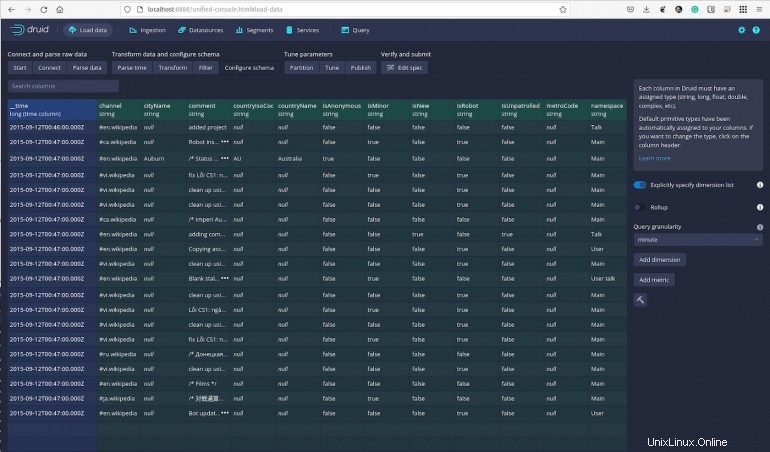
Continua a fare clic sui dati e, in qualsiasi momento, puoi eseguire query e filtrare i dati secondo necessità. Nella sezione Configura schema (Figura G ), puoi persino specificare la granularità delle tue query e aggiungere dimensioni e metriche.
Figura G
E queste sono praticamente le basi di Apache Druid. Sebbene abbiamo solo sfiorato la superficie di ciò che questa potente piattaforma di analisi dei dati può fare, dovresti essere in grado di avere un'idea abbastanza buona di come funziona giocando con i dati di esempio.
Quando hai finito di lavorare, assicurati di tornare alla finestra del terminale e di interrompere il servizio Apache Druid con CTRL + C.