Questo tutorial fornisce dettagli su cosa sono i processi, come vengono utilizzati e come possono essere gestiti su Linux.
In qualità di amministratore di sistema, probabilmente hai interagito con processi in molti modi diversi.
A volte, potresti voler eseguire comandi per identificare i processi che stanno consumando molte risorse sul tuo host.
Potresti aver ricevuto una chiamata da un utente che affermava che uno dei suoi processi si è bloccato e che potrebbe essere necessario interromperlo per continuare a funzionare.
I processi sono davvero al centro del sistema operativo Linux:creati dal kernel stesso, rappresentano le operazioni in esecuzione attualmente in corso sul tuo host Linux.
I processi sono ovunque, possono essere eseguiti in background oppure puoi scegliere di inizializzarli da solo per operazioni personalizzate.
Puoi scegliere di iniziare loro, per interrompere loro, per riprendere loro o per fermare loro.
Nel tutorial di oggi, esamineremo molto da vicino i processi, cosa sono e come vengono utilizzati sul nostro sistema operativo.
Scopriremo tutti i comandi associati ai processi, quali sono i segnali e come possiamo assegnare più risorse computazionali ai nostri processi esistenti.
Pronto?
Cosa imparerai
Leggendo questo tutorial fino alla fine, imparerai i seguenti concetti
- Cosa elabora sono e come vengono creati su un sistema Linux
- Come i processi possono essere identificati su un sistema Linux
- Quale background e in primo piano i processi sono
- Cosa segnala sono e come possono essere utilizzati per interagire con i processi
- Come utilizzare il pgrep così come il pkill comandare in modo efficace
- Come regolare la priorità del processo utilizzando nice e renice
- Come vedere l'attività di elaborazione in tempo reale su Linux
È un programma piuttosto lungo, quindi, senza ulteriori indugi, iniziamo con una breve descrizione di cosa sono i processi.
Nozioni di base sui processi Linux
In breve, i processi eseguono programmi sul tuo host Linux che eseguono operazioni come la scrittura su un disco, la scrittura su un file o l'esecuzione di un server Web, ad esempio.
Il processo ha un proprietario e sono identificati da un ID processo (chiamato anche PID )

D'altra parte, programmi sono righe o codice o righe di istruzioni macchina memorizzate su una memoria dati persistente.
Possono semplicemente risiedere nel tuo archivio dati o possono essere in esecuzione, ovvero in esecuzione come processi.
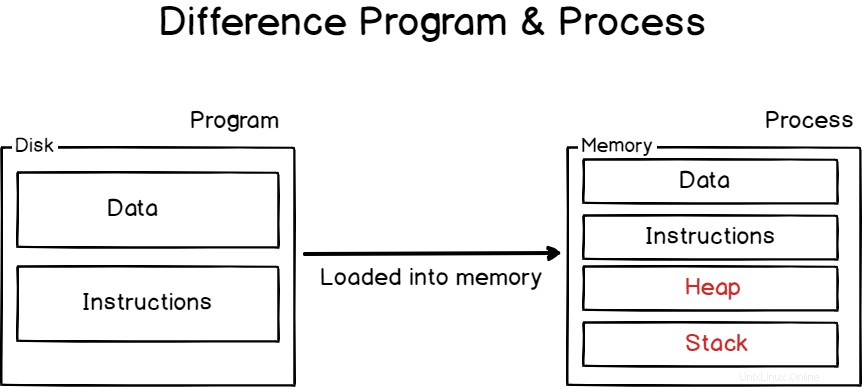
Per eseguire le operazioni a cui sono assegnati, i processi necessitano di risorse :Tempo CPU , memoria (come RAM o spazio su disco ), ma anche memoria virtuale come spazio di scambio nel caso in cui il tuo processo diventi troppo avido.
Ovviamente, i processi possono essere avviati , interrotto , interrotto e persino ucciso .
Prima di impartire qualsiasi comando, vediamo come i processi vengono creati e gestiti dal kernel stesso.
Inizializzazione del processo su Linux
Come abbiamo già affermato, i processi sono gestiti dal Kernel su Linux.
Tuttavia, c'è un concetto fondamentale che devi comprendere per sapere come Linux crea i processi.
Per impostazione predefinita, quando avvii un sistema Linux, il tuo kernel Linux viene caricato in memoria, gli viene assegnato un filesystem virtuale nella RAM (chiamato anche initramfs ) e vengono eseguiti i comandi iniziali.
Uno di questi comandi avvia il primissimo processo su Linux.
Storicamente, questo processo è stato chiamato processo init, ma è stato sostituito dal processo di inizializzazione systemd su molte recenti distribuzioni Linux.
Per dimostrarlo, esegui il seguente comando sul tuo host
$ ps -aux | head -n 2
Come puoi vedere, il processo systemd ha un PID di 1.
Se dovessi stampare tutti i processi sul tuo sistema, usando una visualizzazione ad albero, scopriresti che tutti i processi sono figli di quello systemd.
$ pstree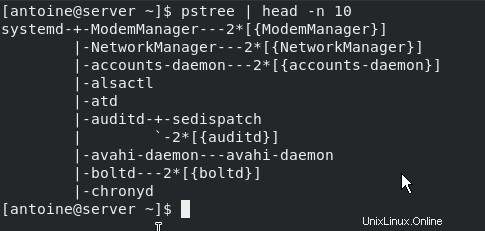
È degno di nota sottolineare il fatto che tutti quei passaggi di inizializzazione (tranne l'avvio del processo iniziale) vengono eseguiti in uno spazio riservato chiamato spazio del kernel.
Lo spazio del kernel è uno spazio riservato al kernel in modo che esegua correttamente gli strumenti di sistema essenziali e per assicurarsi che l'intero host funzioni in modo coerente.
D'altra parte, lo spazio utente è riservato ai processi lanciato dall'utente e gestito dal kernel stesso.
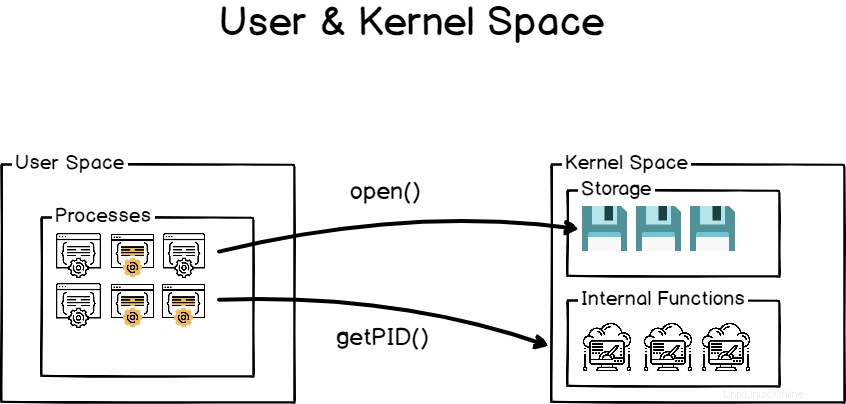
Di conseguenza, il processo systemd è il primo vero processo lanciato nello spazio utente.
Creazione del processo utilizzando Fork ed Exec
Quando crei ed esegui un programma su Linux, generalmente si tratta di due passaggi principali :fork ed esegui .
Funzionamento della forcella
Il fork è un'operazione di clonazione, prende il processo corrente, chiamato anche processo padre, e lo clona in un nuovo processo con un ID processo nuovo di zecca.
Durante il fork, tutto viene copiato dal processo padre:lo stack , il mucchio , ma anche i descrittori di file che significano lo standard input, lo standard output e lo standard error.
Significa che se il mio processo padre stava scrivendo sulla console della shell corrente, anche il processo figlio scriverà sulla console della shell.
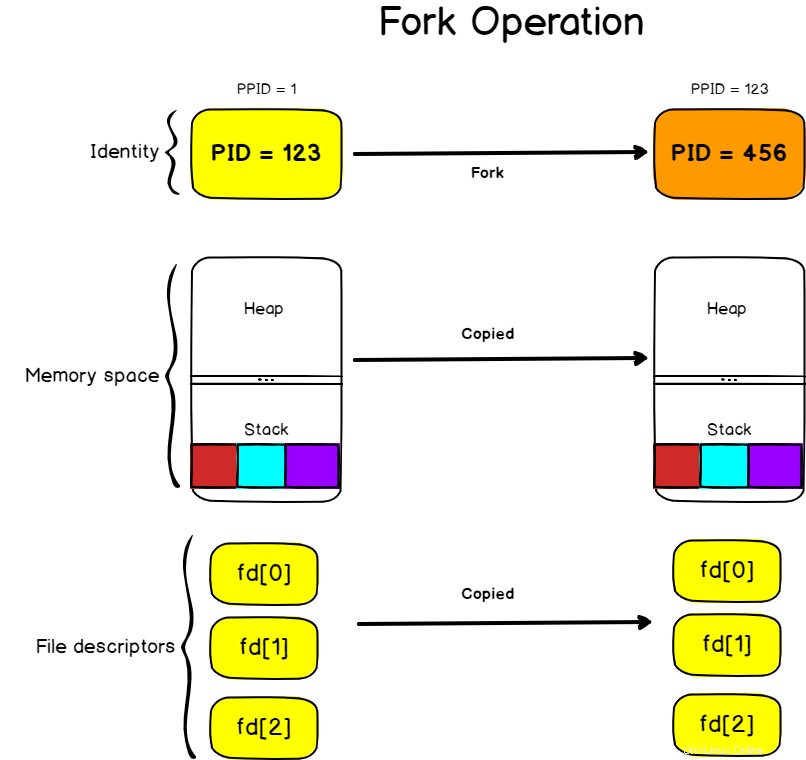
Anche l'esecuzione del processo clonato inizierà alla stessa istruzione del processo padre.
Esegui operazione
L'operazione di esecuzione viene utilizzata su Linux per sostituire l'immagine di processo corrente con l'immagine di un altro processo.
Nel diagramma precedente, abbiamo visto che lo stack del processo padre conteneva tre istruzioni rimaste.
Di conseguenza, le istruzioni sono state copiate nel nuovo processo ma non sono rilevanti per ciò che vogliamo eseguire.
L'operazione exec sostituirà l'immagine di processo (ovvero l'insieme di istruzioni che devono essere eseguite) con un'altra.
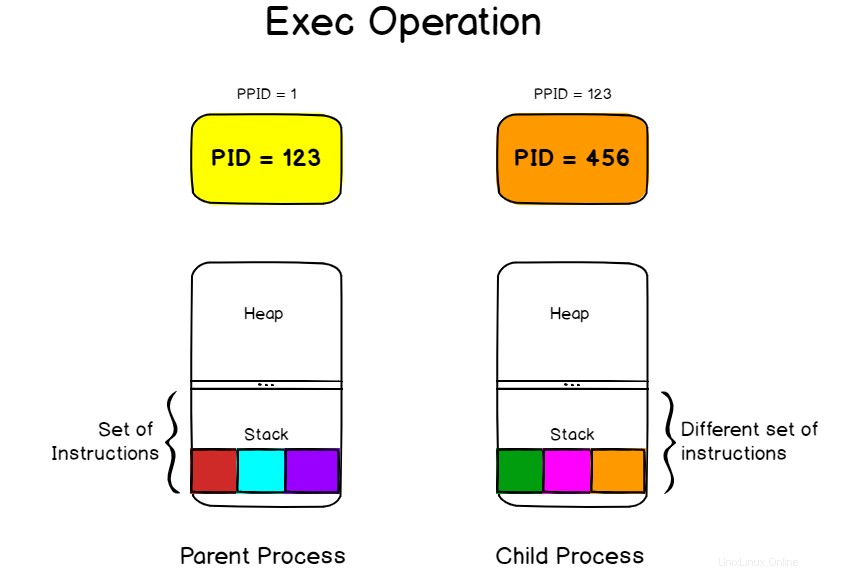
Se ad esempio dovessi eseguire il comando exec nel tuo terminale bash, la tua shell terminerebbe non appena il comando è completato poiché l'immagine del tuo processo corrente (il tuo interprete bash) verrebbe sostituita con il contesto del comando che stai tentando di avviare .
$ exec ls -lSe dovessi tracciare le chiamate di sistema eseguite durante la creazione di un processo, scopriresti che il primo comando C chiamato è quello exec.

Creazione di processi da un ambiente shell
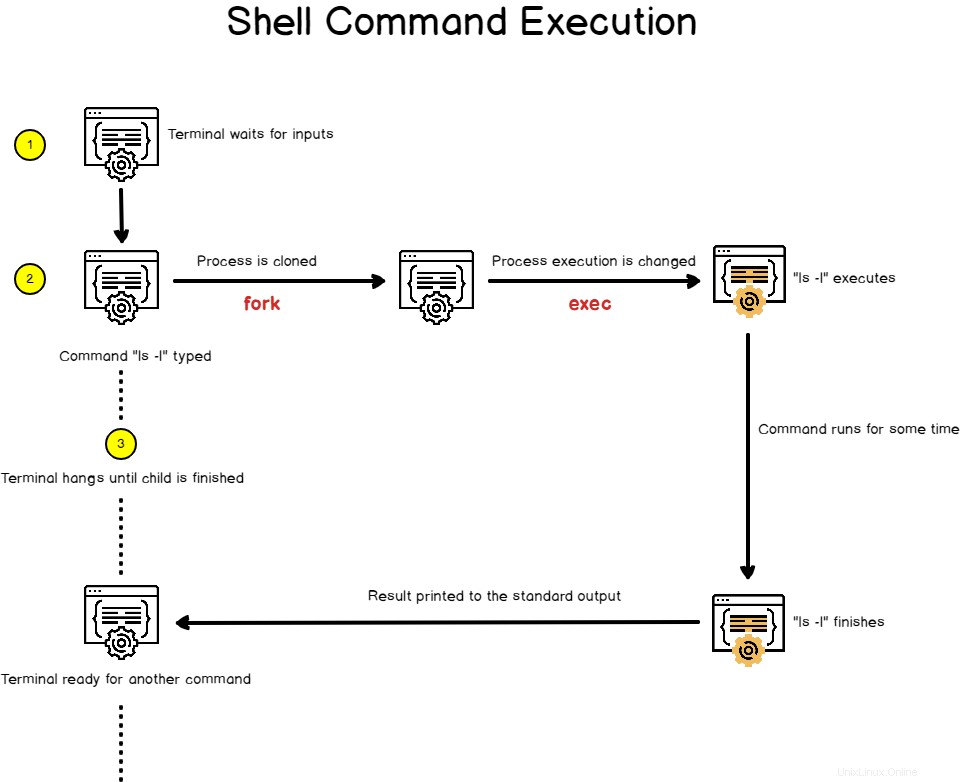
Quando avvii una console shell, si applicano gli stessi identici principi quando avvii un comando.
Una console shell è un processo che attende l'input dell'utente.
Lancia anche un interprete bash quando premi Invio e fornisce un ambiente per l'esecuzione dei tuoi comandi.
Ma la shell segue i passaggi che abbiamo descritto in precedenza.
Quando premi invio, la shell viene biforcuta su un processo figlio che sarà responsabile dell'esecuzione del comando. La shell attenderà pazientemente fino al termine dell'esecuzione del processo figlio.
D'altra parte, il processo figlio è collegato agli stessi descrittori di file e può condividere variabili che sono state dichiarate in un ambito globale.
Il processo figlio esegue "exec ” per sostituire l'immagine di processo corrente (che è l'immagine di processo della shell) nell'immagine di processo del comando che si sta tentando di eseguire.
Il processo figlio alla fine terminerà e stamperà il suo risultato sullo standard output che ha ereditato dal processo genitore, in questo caso la console della shell stessa.
Ora che hai alcune nozioni di base su come vengono creati i processi nel tuo ambiente Linux, vediamo alcuni dettagli sui processi e su come possono essere identificati facilmente.
Identificazione dei processi in esecuzione su Linux
Il modo più semplice per identificare i processi in esecuzione su Linux è eseguire ps comando.
$ ps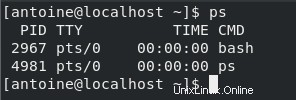
Per impostazione predefinita, il comando ps ti mostrerà l'elenco dei processi in esecuzione correnti di proprietà dell'utente corrente.
In questo caso, per il mio utente sono in esecuzione solo due processi:l'interprete bash e il comando ps Ci sono imbattuto.
La parte importante qui è che i processi hanno proprietari , il più delle volte l'utente che li esegue in primo luogo.
Per illustrare questo, diamo un elenco dei primi dieci processi sul tuo sistema operativo Linux, con un formato di visualizzazione diverso.
$ ps -ef | head -n 10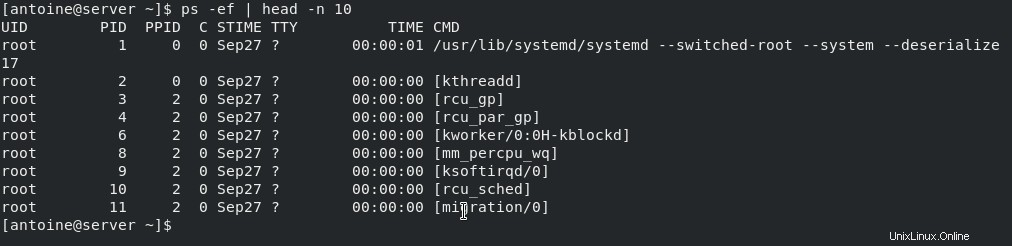
Come puoi vedere qui, i primi dieci processi sono di proprietà dell'utente "root “.
Queste informazioni saranno particolarmente importanti quando si tratta di interagire con i processi con i segnali.
Per visualizzare i processi che sono di proprietà ed eseguiti dall'utente connesso corrente, eseguire il comando seguente
$ ps u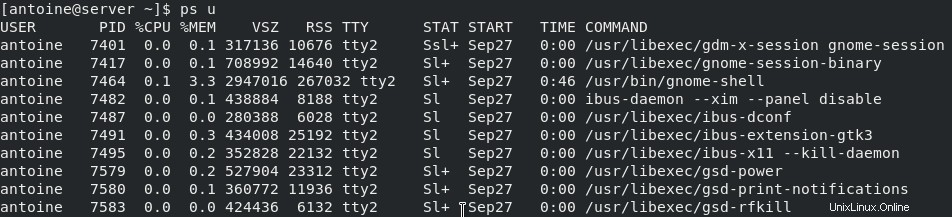
Ci sono molte opzioni diverse per il comando ps e possono essere visualizzate eseguendo il comando manuale.
$ man psPer esperienza, i due comandi più importanti per vedere i processi in esecuzione sono
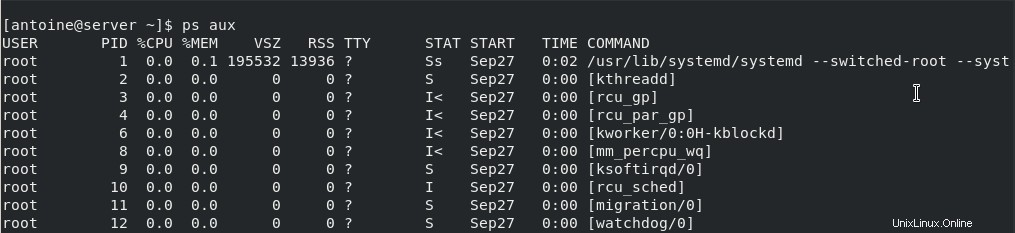
ps aux
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMANDCiò corrisponde a un elenco di processi in stile BSD , dove il seguente comando
ps -ef
UID PID PPID C STIME TTY TIME CMDCorrisponde a un elenco di processi in stile POSIX .
Entrambi rappresentano gli attuali processi in esecuzione su un sistema, ma il primo ha l'opzione "u" per "orientato all'utente" che semplifica la lettura delle metriche di processo.
Ora che hai visto cosa sono i processi e come possono essere elencati, vediamo quali processi in background e in primo piano si trovano sul tuo host.
Processi in background e in primo piano
La definizione dei processi in background e in primo piano è abbastanza autoesplicativa.
Lavori e processi nella shell corrente
Un processo in background su Linux è un processo che viene eseguito in background, il che significa che non è gestito attivamente da un utente tramite una shell, ad esempio.
Sul lato opposto, un processo in primo piano è un processo con cui è possibile interagire tramite l'input diretto dell'utente.
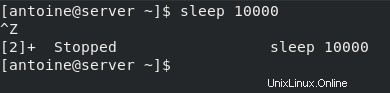
Diciamo ad esempio che hai aperto un terminale di shell e che hai digitato il seguente comando nella tua console.
$ sleep 10000Come probabilmente avrai notato, il tuo terminale si bloccherà fino al termine del processo di sospensione. Di conseguenza, il processo non viene eseguito in background, viene eseguito in primo piano.
Sono in grado di interagire con esso. Se premo Ctrl + Z, ad esempio invierà direttamente un segnale di arresto al processo.
Tuttavia, esiste un modo per eseguire il processo in background.
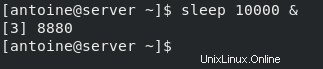
Per eseguire un processo in background, metti semplicemente un "& ” firma alla fine del tuo comando.
$ sleep 10000 &Come puoi vedere, il controllo è stato restituito direttamente all'utente e il processo ha iniziato a essere eseguito in background
Per vedere il tuo processo in esecuzione, nel contesto della shell corrente, puoi eseguire il comando jobs
$ jobs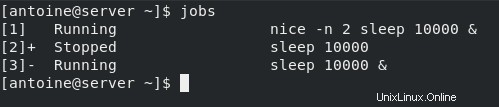
I lavori sono un elenco di processi avviati nel contesto della shell corrente e che potrebbero essere ancora in esecuzione in background.
Come puoi vedere nell'esempio sopra, ho due processi attualmente in esecuzione in background.
Le diverse colonne da sinistra a destra rappresentano l' ID lavoro, lo stato del processo (che scoprirai nella prossima sezione) e il comando eseguito.
Utilizzo dei comandi bg e fg
Per interagire con i lavori, hai a disposizione due comandi:bg e fg .
Il comando bg viene utilizzato su Linux per inviare un processo in background e la sintassi è la seguente
$ bg %<job_id>Allo stesso modo, per portare un processo in primo piano, puoi usare fg allo stesso modo
$ fg %<job_id>Se torniamo all'elenco dei lavori del nostro esempio precedente, se voglio portare il lavoro 3 in primo piano, cioè nella finestra della shell corrente, eseguirei il seguente comando
$ fg %3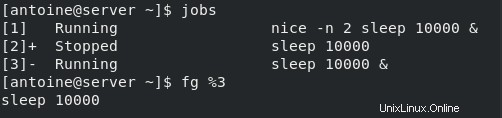
Emettendo un comando Ctrl + Z, sono in grado di interrompere il processo. Posso collegarlo con un comando bg per inviarlo in background.
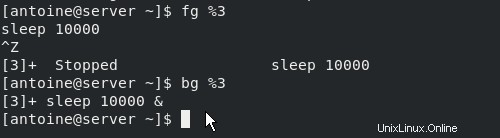
Ora che hai un'idea migliore di cosa sono i processi in background e in primo piano, vediamo come è possibile interagire con il processo utilizzando i segnali.
Interazione con i processi tramite segnali
Su Linux, i segnali sono una forma di comunicazione interprocesso (chiamato anche IPC ) che crea e invia notifiche asincrone ai processi in esecuzione sul verificarsi di un evento specifico.
I segnali vengono spesso utilizzati per inviare un'uccisione o un comando di terminazione a un processo per chiuderlo (chiamato anche kill signal).
Per inviare un segnale a un processo, devi usare il kill comando.
$ kill -<signal number> <pid>|<process_name>Ad esempio, per forzare l'interruzione di un processo HTTPD (PID =123) (senza un arresto pulito), eseguire il comando seguente
$ kill -9 123Spiegazione delle categorie di segnali
Come spiegato, ci sono molti segnali che si possono inviare per notificare un processo specifico.
Ecco l'elenco di quelli più usati :
- SEGNO :l'abbreviazione di signal interrupt è un segnale utilizzato per interrompere un processo in corso. È anche il segnale che viene inviato quando un utente ha premuto Ctrl + C su un terminale;
- SIGHUP :l'abbreviazione di signal hangup è il segnale inviato dal tuo terminale quando è chiuso. Analogamente a un SIGINT, il processo termina;
- SIGKILL :segnale utilizzato per forzare l'arresto di un processo indipendentemente dal fatto che possa essere interrotto con grazia o meno. Questo segnale non può essere ignorato tranne che per il processo init (o quello systemd su distribuzioni recenti);
- SIGQUIT :segnale specifico inviato quando un utente vuole uscire o uscire dal processo in corso. Può essere invocato premendo Ctrl + D ed è spesso usato nelle shell dei terminali o nelle sessioni SSH;
- SIGUSR1, SIGUSR2 :tali segnali sono utilizzati esclusivamente per scopi di comunicazione e possono essere utilizzati in programmi per implementare gestori personalizzati;
- SIGSTOP :indica al processo di interrompere l'esecuzione senza terminare il processo. Il processo è quindi in attesa di essere continuato o terminato completamente;
- SIGCONT :se il processo è contrassegnato come interrotto, indica al processo di ricominciare l'esecuzione.
Per vedere l'elenco completo di tutti i segnali disponibili, puoi eseguire il seguente comando
$ kill -l
1) SIGHUP 2) SIGINT 3) SIGQUIT 4) SIGILL
5) SIGTRAP 6) SIGABRT 7) SIGBUS 8) SIGFPE
9) SIGKILL 10) SIGUSR1 11) SIGSEGV 12) SIGUSR2
13) SIGPIPE 14) SIGALRM 15) SIGTERM 16) SIGSTKFLT
17) SIGCHLD 18) SIGCONT 19) SIGSTOP 20) SIGTSTP
21) SIGTTIN 22) SIGTTOU 23) SIGURG 24) SIGXCPU
25) SIGXFSZ 26) SIGVTALRM 27) SIGPROF 28) SIGWINCH
29) SIGIO 30) SIGPWR 31) SIGSYS 34) SIGRTMIN
35) SIGRTMIN+1 36) SIGRTMIN+2 37) SIGRTMIN+3 38) SIGRTMIN+4
39) SIGRTMIN+5 40) SIGRTMIN+6 41) SIGRTMIN+7 42) SIGRTMIN+8
43) SIGRTMIN+9 44) SIGRTMIN+10 45) SIGRTMIN+11 46) SIGRTMIN+12
47) SIGRTMIN+13 48) SIGRTMIN+14 49) SIGRTMIN+15 50) SIGRTMAX-14
51) SIGRTMAX-13 52) SIGRTMAX-12 53) SIGRTMAX-11 54) SIGRTMAX-10
55) SIGRTMAX-9 56) SIGRTMAX-8 57) SIGRTMAX-7 58) SIGRTMAX-6
59) SIGRTMAX-5 60) SIGRTMAX-4 61) SIGRTMAX-3 62) SIGRTMAX-2
63) SIGRTMAX-1 64) SIGRTMAXStati dei segnali e dei processi
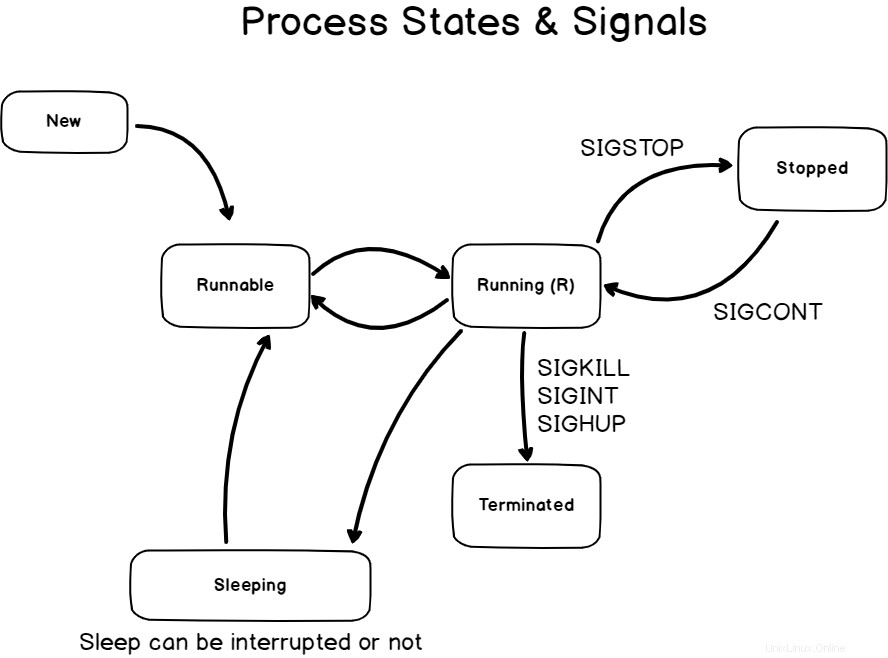
Ora che sai che è possibile interrompere, terminare o interrompere i processi, è tempo che tu impari a conoscere gli stati dei processi.
I processi hanno molti stati diversi, possono essere :
- Correndo :i processi in esecuzione sono quelli che utilizzano una certa potenza di calcolo (come il tempo della CPU) nell'ora corrente. Un processo può anche essere definito "eseguibile" se tutte le condizioni di esecuzione sono soddisfatte e attende un po' di tempo CPU dallo scheduler della CPU.
- Arrestato :un segnale interrotto è collegato al segnale SIGSTOP o alla scorciatoia da tastiera Ctrl + Z. L'esecuzione del processo è sospesa ed è in attesa di un SIGCONT o di un SIGKILL.
- Dormire :un processo inattivo è un processo in attesa della disponibilità di un evento o di una risorsa (come un disco).
Ecco un diagramma che rappresenta i diversi stati del processo collegati ai segnali che potresti inviare loro.
Ora che sai qualcosa in più sugli stati dei processi, diamo un'occhiata ai comandi pgrep e pkill.
Manipolazione del processo con pgrep e pkill
Su Linux c'è già molto che puoi fare semplicemente usando il comando ps.
Puoi restringere la tua ricerca a un particolare processo e puoi utilizzare il PID per ucciderlo completamente.
Tuttavia, ci sono due comandi progettati in modo che i tuoi comandi siano ancora più brevi:pgrep e pkill
Utilizzo del comando pgrep
Il pgrep command è una scorciatoia per usare il comando ps inviato tramite pipe con il comando grep.
Il comando pgrep cercherà tutte le occorrenze di un processo specifico utilizzando un nome o uno schema definito.
La sintassi del comando pgrep è la seguente
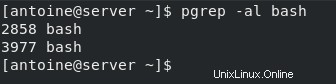
$ pgrep <options> <pattern>Ad esempio, se dovessi cercare tutti i processi denominati "bash" sul tuo host, eseguiresti il seguente comando
$ pgrep bashIl comando pgrep non è limitato ai processi di proprietà dell'utente corrente per impostazione predefinita.
Se un altro utente dovesse eseguire il comando bash, verrebbe visualizzato nell'output del comando pgrep.
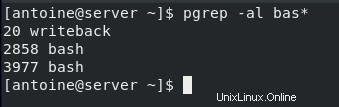
È anche possibile cercare processi utilizzando caratteri glob.
Utilizzo del comando pkill
D'altra parte, il comando pkill è anche una scorciatoia per il comando ps usato con il comando kill.
Il comando pkill viene utilizzato per inviare segnali ai processi in base ai loro ID o ai loro nomi.
La sintassi del comando pkill è la seguente
$ pkill <options> <pattern>Ad esempio, se vuoi eliminare tutte le finestre di Firefox sul tuo host, esegui il seguente comando
$ pkill firefoxAnalogamente al comando pgrep, hai la possibilità di restringere i risultati specificando un utente con l'opzione -u.
Per terminare tutti i processi che iniziano con "fire" e sono di proprietà dell'utente e root correnti, dovresti eseguire il seguente comando
$ pkill user,root fire*Se non disponi dei diritti per interrompere un processo, riceverai un messaggio di errore di autorizzazione negata sul tuo output standard.

Hai anche la possibilità di inviare segnali specifici specificando il numero del segnale nel comando pkill
Ad esempio, per fermare Firefox con un segnale SIGSTOP, dovresti eseguire il seguente comando
$ pkill -19 firefoxRegolazione della priorità del processo utilizzando nice and renice
Su Linux, non tutti i processi hanno la stessa priorità per quanto riguarda il tempo della CPU.
Ad alcuni processi, come i processi molto importanti eseguiti da root, viene assegnata una priorità più alta affinché il sistema operativo possa lavorare su attività veramente importanti per il sistema.
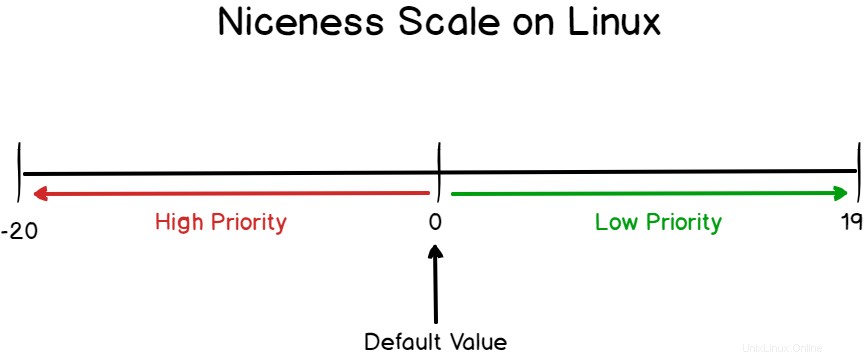
La priorità del processo su Linux è chiamata il livello piacevole.
Il livello piacevole è una scala di priorità che va da -20 a 19.
Più in basso si va sulla scala della gentilezza, maggiore sarà la priorità.
Allo stesso modo, maggiore è la tua scala di gentilezza, minore sarà la tua priorità.
Per ricordarlo, puoi ricordare il fatto che "più sei gentile, più sei disposto a condividere risorse con gli altri".
Per avviare un determinato programma o processo con un determinato livello, esegui il seguente comando
$ nice -n <level> <command>Ad esempio, per eseguire il comando tar con un livello tar personalizzato, eseguire il comando seguente
$ nice -n 19 tar -cvf test.tar fileAllo stesso modo, puoi usare il comando renice per impostare il livello piacevole di un processo in esecuzione su un determinato valore.
$ renice -n <priority> <pid>Ad esempio, se ho un processo in esecuzione con il PID 123, posso utilizzare il comando renice per impostarne la priorità su un determinato valore.
$ renice -n 18 123Bellezza e permessi
Se non sei un membro del gruppo sudo (o un membro del gruppo wheel su distribuzioni basate su Red Hat), ci sono alcune restrizioni quando si tratta di ciò che puoi con il bel comando.
Per illustrarlo, prova a eseguire il comando seguente come utente non sudo
$ nice -n -1 tar -cvf test.tar file
nice: cannot set niceness: Permission denied
Quando si tratta di gentilezza, c'è una regola che devi sapere:
Come utente non root (o sudo), non sarai in grado di impostare un livello inferiore rispetto a quello predefinito assegnato (che è zero) e non sarai in grado di rifinire un processo in esecuzione per un livello inferiore a quello attuale.
Per illustrare l'ultimo punto, avvia un comando di sospensione in background con un buon valore di 2.
$ nice -n 2 sleep 10000 &Quindi, identifica l'ID del processo che hai appena creato.

Ora, prova a impostare il livello piacevole del tuo processo su un valore inferiore a quello che hai specificato in primo luogo.
$ renice -n 1 8363
Come probabilmente avrai notato, non sarai in grado di impostare il livello di gentilezza su 1, ma solo su un valore superiore a quello che hai specificato.
Ora, se scegli di eseguire il comando come sudo, sarai in grado di impostare il livello nice su un valore inferiore.

Ora che hai un'idea chiara dei comandi nice e renice, vediamo come puoi monitorare i tuoi processi in tempo reale su Linux.
Monitoraggio dei processi su Linux utilizzando top e htop
In un articolo precedente, abbiamo discusso di come sia possibile costruire una pipeline di monitoraggio completa per monitorare i processi Linux in tempo reale.
Utilizzo di top su Linux
Top è un comando interattivo che qualsiasi utente può eseguire per avere un elenco completo e ordinato di tutti i processi in esecuzione su un host Linux.
Per eseguire in alto, eseguilo semplicemente senza argomenti.
Top verrà eseguito in modalità interattiva.
$ topSe vuoi eseguire top per un numero personalizzato di iterazioni, esegui il comando seguente
$ top -n <number>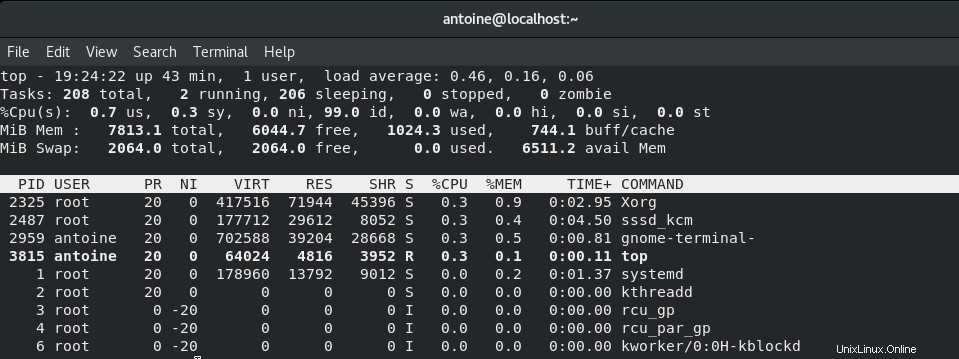
Il comando top mostrerà innanzitutto le statistiche di riepilogo sul tuo sistema in alto, ad esempio il numero di attività in esecuzione, la percentuale di CPU utilizzata o il consumo di memoria.
Subito sotto, hai accesso a un elenco in tempo reale di tutti i processi in esecuzione o inattivi sul tuo host.
Questa visualizzazione si aggiornerà ogni tre secondi, ma puoi ovviamente modificare questo parametro.
Per aumentare la frequenza di aggiornamento nel comando in alto, premi il comando "d" e scegli una nuova frequenza di aggiornamento
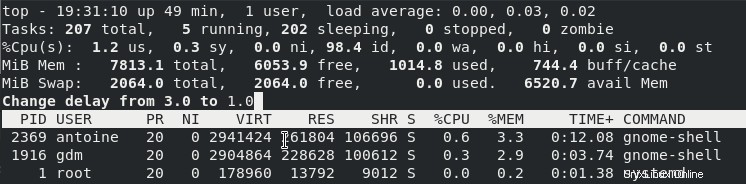
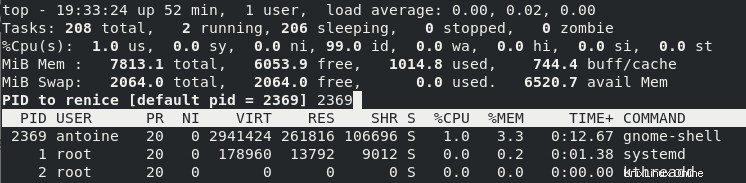
Allo stesso modo, puoi modificare il valore di un processo in esecuzione dal vivo premendo il tasto "r" sulla tastiera.
Le stesse regole di autorizzazione si applicano se si desidera modificare i processi a un valore inferiore a quello già assegnato.
Di conseguenza, potrebbe essere necessario eseguire il comando come sudo.
Utilizzo di htop su Linux
In alternativa, se stai cercando un modo migliore per visualizzare i processi sul tuo host Linux, puoi usare il comando htop.
Per impostazione predefinita, il comando htop non è disponibile sulla maggior parte delle distribuzioni, quindi dovrai installarlo con le seguenti istruzioni.
$ sudo apt-get update
$ sudo apt-get install htopSe stai eseguendo una distribuzione basata su Red Hat, esegui i seguenti comandi.
$ sudo yum -y install epel-release
$ sudo yum -y update
$ sudo yum -y install htopInfine, per eseguire il comando htop, eseguilo semplicemente senza argomenti.
$ htop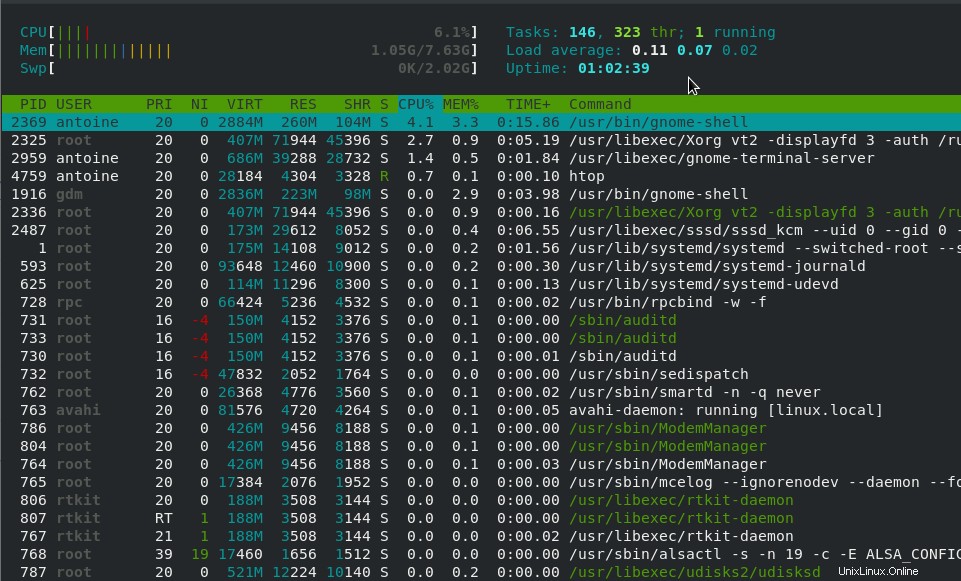
Come puoi vedere, l'output è molto simile, tranne per il fatto che mostra le informazioni in un output più umano.
Conclusione
In questo tutorial hai appreso molti concetti sui processi:come vengono creati, come possono essere gestiti e come possono essere monitorati in modo efficace.
Se stai cercando altri tutorial relativi all'amministrazione del sistema Linux, abbiamo una sezione completa dedicata ad esso sul sito Web, quindi assicurati di dare un'occhiata.