Per un amministratore di sistema, è molto comune eseguire il reindirizzamento di input o output durante il suo lavoro quotidiano.
Il reindirizzamento di input e output è uno strumento molto potente, che consente di collegare più comandi insieme e di sintetizzare l'output di più comandi.
Reindirizzamento input/output è un concetto fondamentale dei sistemi basati su Unix e può essere utilizzato come un modo per aumentare la produttività dei programmatori tremendamente.
Tuttavia, il reindirizzamento di input e output è un argomento ampio e ci sono alcune nozioni di base che devi capire se vuoi essere produttivo.
Con questo tutorial capirai tutto che c'è da sapere sul reindirizzamento di input e output sui sistemi Linux.
Rifletteremo sul design del kernel Linux sui file e sul modo in cui funzionano i processi per avere una comprensione profonda e completa di cosa sia il reindirizzamento di input e output.
Lungo il percorso verranno forniti alcuni esempi per garantire che le conoscenze teoriche siano collegate ad esercizi pratici.
Pronto?
Cosa imparerai
Se segui questo tutorial fino alla fine, imparerai i seguenti concetti.
- Quali descrittori di file sono e come sono correlati a input e output standard;
- Come controllare input e output standard per un determinato processo su Linux;
- Come reindirizzare input e output standard su Linux;
- Come utilizzare le pipeline per concatenare ingressi e uscite per comandi lunghi;
È un programma piuttosto lungo, senza ulteriori indugi, diamo un'occhiata a cosa sono i descrittori di file e come i file sono concettualizzati dal kernel Linux.
1 – Cosa sono i processi Linux?
Prima di comprendere l'input e l'output su un sistema Linux, è molto importante avere alcune nozioni di base su cosa sono i processi Linux e su come interagiscono con il tuo hardware.
Se sei interessato solo alle righe di comando di reindirizzamento di input e output, puoi passare alle sezioni successive. Questa sezione è per gli amministratori di sistema disposti ad approfondire l'argomento.
a – Come vengono creati i processi Linux?
Probabilmente l'hai già sentito prima, poiché è un adagio piuttosto popolare, ma su Linux tutto è un file .
Significa che processi, dispositivi, tastiere, dischi rigidi sono rappresentati come file che vivono nel filesystem.
Il kernel Linux può differenziare questi file assegnando loro un tipo di file (un file, una directory, un soft link o un socket per esempio) ma sono memorizzati nella stessa struttura dati dal Kernel.
Come probabilmente già saprai, i processi Linux vengono creati come fork di processi esistenti che possono essere il processo init o il processo systemd su distribuzioni più recenti.
Quando si crea un nuovo processo, il kernel Linux eseguirà il fork di un processo padre e duplicherà una struttura che è la seguente.
b – Come vengono archiviati i file su Linux?
Credo che un diagramma dica più di cento parole, quindi ecco come i file vengono concettualmente archiviati su un sistema Linux.

Come puoi vedere, per ogni processo creato, una nuova task_struct viene creato sul tuo host Linux.
Questa struttura contiene due riferimenti, uno per i metadati del filesystem (chiamato fs ) dove puoi trovare informazioni come ad esempio la maschera del filesystem.
L'altro è una struttura per i file che contengono quelli che chiamiamo descrittori di file .
Contiene anche metadati sui file utilizzati dal processo, ma ci concentreremo sui descrittori di file per questo capitolo.
In informatica, i descrittori di file sono riferimenti ad altri file attualmente utilizzati dal kernel stesso.
Ma cosa rappresentano quei file?
c – Come vengono utilizzati i descrittori di file su Linux?
Come probabilmente già saprai, il kernel agisce come un interfaccia tra i tuoi dispositivi hardware (uno schermo, un mouse, un CD-ROM o una tastiera).
Significa che il tuo kernel è in grado di capire che desideri trasferire alcuni file tra dischi o che potresti voler creare un nuovo video sull'unità secondaria, ad esempio.
Di conseguenza, il kernel Linux sposta permanentemente i dati dai dispositivi di input (una tastiera ad esempio) ai dispositivi di output (un disco rigido ad esempio).
Utilizzando questa astrazione, i processi sono essenzialmente un modo per manipolare gli input (come leggi operazioni) per eseguire il rendering di vari output (come scrittura operazioni)
Ma in che modo i processi sanno dove devono essere inviati i dati?
I processi sanno dove devono essere inviati i dati utilizzando descrittori di file.
Su Linux, il descrittore di file 0 (o fd[0]) è assegnato allo input standard.
Allo stesso modo il descrittore di file 1 (o fd[1]) viene assegnato allo output standard e il descrittore di file 2 (o fd[2]) è assegnato a l'errore standard.
È una costante su un sistema Linux, per ogni processo, i primi tre descrittori di file sono riservati per input, output ed errori standard.
Questi descrittori di file sono mappati sui dispositivi sul tuo sistema Linux.
I dispositivi registrati quando è stata istanziata il kernel, possono essere visualizzati in /dev directory del tuo host.
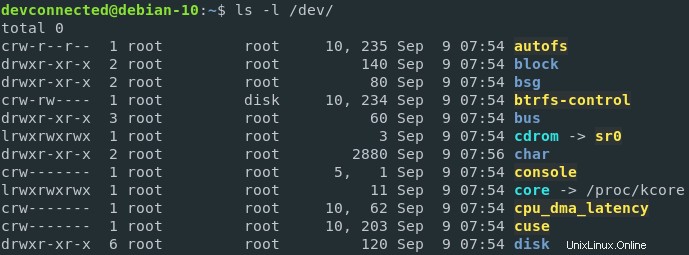
Se dovessi dare un'occhiata ai descrittori di file di un determinato processo, ad esempio un processo bash, puoi vedere che i descrittori di file sono essenzialmente collegamenti software a dispositivi hardware reali sul tuo host.
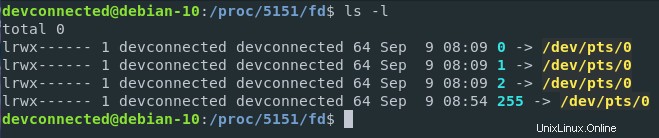
Come puoi vedere, quando si isolano i descrittori di file del mio processo bash (che ha il PID 5151 sul mio host), sono in grado di vedere i dispositivi che interagiscono con il mio processo (o i file aperti dal kernel per il mio processo).
In questo caso, /dev/pts/0 rappresenta un terminale che è un dispositivo virtuale (o tty) sul mio filesystem virtuale. In termini più semplici, significa che la mia istanza bash (in esecuzione in un'interfaccia terminale Gnome) attende gli input dalla mia tastiera, li stampa sullo schermo e li esegue quando richiesto.
Ora che hai una comprensione più chiara dei descrittori di file e di come vengono utilizzati dai processi, siamo pronti a descrivere come eseguire il reindirizzamento di input e output su Linux .
2 – Che cos'è il reindirizzamento dell'output su Linux?
Il reindirizzamento di input e output è una tecnica utilizzata per reindirizzare/cambiare input e output standard, cambiando essenzialmente la posizione in cui vengono letti i dati o dove vengono scritti i dati.
Ad esempio, se eseguo un comando sulla mia shell Linux, l'output potrebbe essere stampato direttamente sul mio terminale (un comando cat per esempio).
Tuttavia, con il reindirizzamento dell'output, potrei scegliere di archiviare l'output del mio comando cat in un file per l'archiviazione a lungo termine.
a – Come funziona il reindirizzamento dell'output?
Il reindirizzamento dell'output è l'atto di reindirizzare l'output di un processo in un luogo prescelto come file, database, terminali o qualsiasi dispositivo (o dispositivo virtuale) su cui è possibile scrivere.
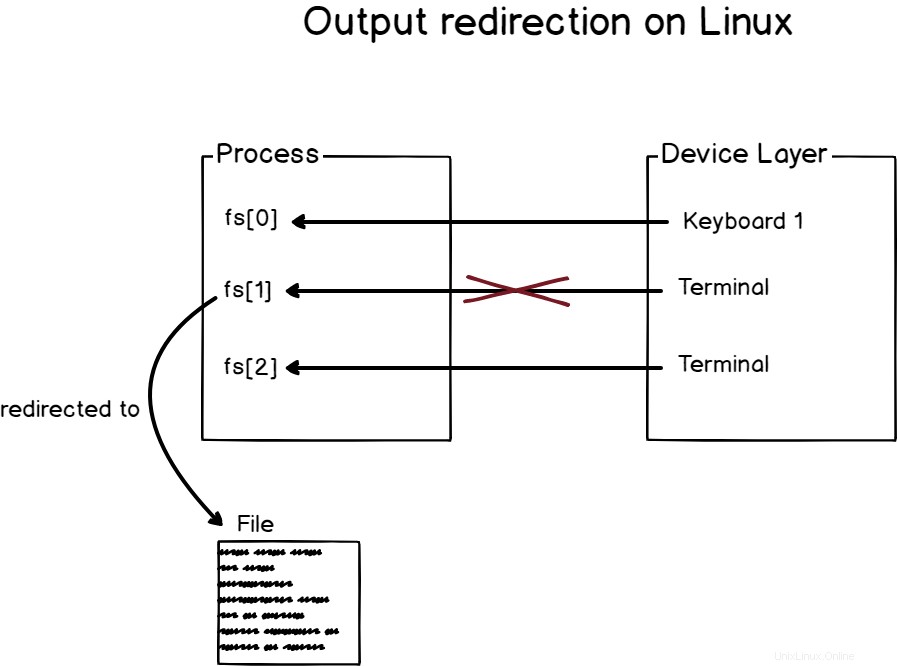
Ad esempio, diamo un'occhiata al comando echo.
Per impostazione predefinita, la funzione echo prenderà un parametro stringa e lo stamperà sul dispositivo di output predefinito.
Di conseguenza, se si esegue la funzione echo è un terminale, l'output verrà stampato nel terminale stesso.

Ora diciamo che voglio invece che la stringa venga stampata su un file, per l'archiviazione a lungo termine.
Per reindirizzare l'output standard su Linux, devi utilizzare l'operatore ">".
Ad esempio, per reindirizzare l'output standard della funzione echo su un file, dovresti eseguire
$ echo devconnected > fileSe il file non è esistente, verrà creato.
Successivamente, puoi dare un'occhiata al contenuto del file e vedere che la stringa "devconnected" è stata stampata correttamente su di esso.

In alternativa, è possibile reindirizzare l'output utilizzando "1> sintassi ".
$ echo test 1> file
b – Reindirizzamento dell'output ai file in modo non distruttivo
Durante il reindirizzamento dell'output standard a un file, probabilmente hai notato che cancella il contenuto esistente del file.
A volte, può essere piuttosto problematico poiché vorresti mantenere il contenuto esistente del file e aggiungere semplicemente alcune modifiche alla fine del file.
Per aggiungere contenuto a un file utilizzando il reindirizzamento dell'output, utilizza l'operatore ">>" anziché l'operatore ">".
Dato l'esempio che abbiamo usato prima, aggiungiamo una seconda riga al nostro file esistente.
$ echo a second line >> file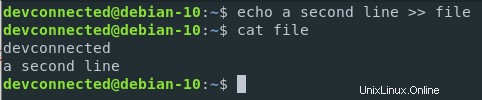
Ottimo!
Come puoi vedere, il contenuto è stato aggiunto al file, anziché sovrascriverlo completamente.
c – Problemi di reindirizzamento dell'output
Quando hai a che fare con il reindirizzamento dell'output, potresti essere tentato di eseguire un comando su un file solo per reindirizzare l'output allo stesso file.
Reindirizzamento allo stesso file
echo 'This a cool butterfly' > file
sed 's/butterfly/parrot/g' file > fileCosa ti aspetti di vedere nel file di prova?
Il risultato è che il file è completamente vuoto.

Perché?
Per impostazione predefinita, durante l'analisi del comando, il kernel non eseguirà i comandi in sequenza.
Significa che non aspetterà la fine del comando sed per aprire il tuo nuovo file e scrivervi il contenuto.
Invece, il kernel aprirà il tuo file, cancellerà tutto il contenuto al suo interno e attenderà che il risultato della tua operazione sed venga elaborato.
Poiché l'operazione sed vede un file vuoto (perché tutto il contenuto è stato cancellato dall'operazione di reindirizzamento dell'output), il contenuto è vuoto.
Di conseguenza, al file non viene aggiunto nulla e il contenuto è completamente vuoto.
Per reindirizzare l'output allo stesso file, potresti voler utilizzare pipes o comandi più avanzati come
command … input_file > temp_file && mv temp_file input_fileProtezione di un file dalla sovrascrittura
In Linux, è possibile proteggere i file dalla sovrascrittura da parte dell'operatore “>”.
Puoi proteggere i tuoi file impostando il parametro "noclobber" nell'ambiente shell corrente.
$ set -o noclobberÈ anche possibile limitare il reindirizzamento dell'output eseguendo
$ set -CNota :per riattivare il reindirizzamento dell'output, esegui semplicemente set +C
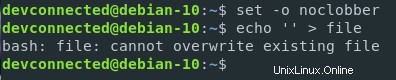
Come puoi vedere, il file non può essere sovrascritto quando si imposta questo parametro.
Se voglio davvero forzare l'override, posso usare ">| ” per forzarlo.

3 – Che cos'è il reindirizzamento dell'input su Linux?
a – Come funziona il reindirizzamento dell'input?
Il reindirizzamento dell'input è l'atto di reindirizzare l'input di un processo a un determinato dispositivo (o dispositivo virtuale) in modo che inizi a leggere da questo dispositivo e non da quello predefinito assegnato dal kernel.
Ad esempio, quando apri un terminale, interagisci con esso con la tua tastiera.
Tuttavia, ci sono alcuni casi in cui potresti voler lavorare con il contenuto di un file, perché vuoi inviare a livello di codice il contenuto del file al tuo comando.
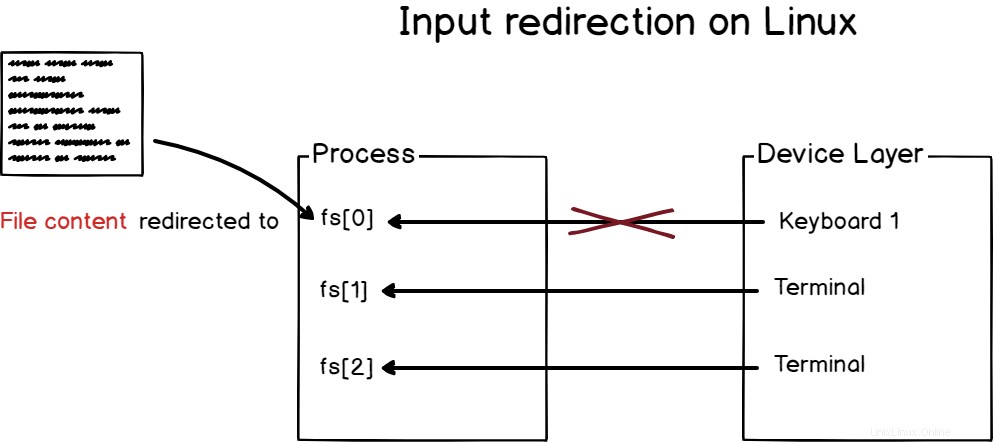
Per reindirizzare l'input standard su Linux, devi utilizzare l'operatore "<".
Ad esempio, supponiamo di voler utilizzare il contenuto di un file ed eseguire un comando speciale su di esso.
In questo caso, utilizzerò un file contenente domini e il comando sarà un semplice comando di ordinamento.
In questo modo i domini verranno ordinati in ordine alfabetico.
Con il reindirizzamento dell'input, posso eseguire il seguente comando
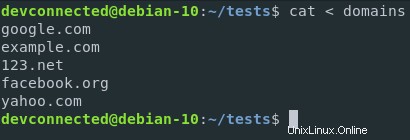
Se voglio ordinare quei domini, posso reindirizzare il contenuto del file dei domini all'input standard della funzione di ordinamento.
$ sort < domains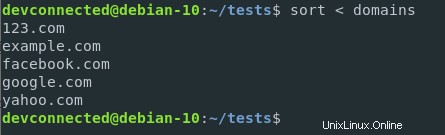
Con questa sintassi, il contenuto del file domains viene reindirizzato all'input della funzione di ordinamento. È abbastanza diverso dalla seguente sintassi
$ sort domainsAnche se l'output può essere lo stesso, in questo caso la funzione di ordinamento accetta un file come parametro.
Nell'esempio di reindirizzamento dell'input, la funzione di ordinamento viene chiamata senza parametri.
Di conseguenza, quando alla funzione non vengono forniti parametri di file, la funzione lo legge dallo standard input per impostazione predefinita.
In questo caso, sta leggendo il contenuto del file fornito.
b – Reindirizzamento dell'input standard con un file contenente più righe
Se il tuo file contiene più righe, puoi comunque reindirizzare l'input standard dal tuo comando per ogni singola riga del tuo file.
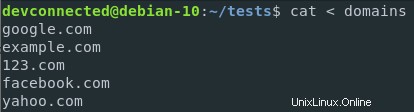
Diciamo ad esempio che vuoi avere una richiesta di ping per ogni singola voce nel file dei domini.
Per impostazione predefinita, il comando ping prevede che venga eseguito il ping di un singolo IP o URL.
Puoi, tuttavia, reindirizzare il contenuto del file dei tuoi domini a una funzione personalizzata che eseguirà una funzione ping per ogni voce.
$ ( while read ip; do ping -c 2 $ip; done ) < ips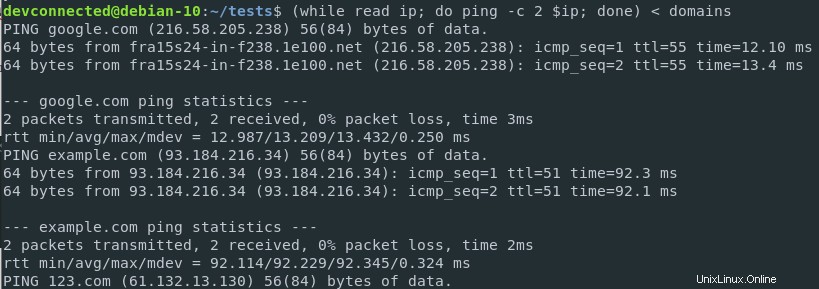
c – Combinare il reindirizzamento dell'input con il reindirizzamento dell'output
Ora che sai che l'input standard può essere reindirizzato a un comando, è utile ricordare che il reindirizzamento dell'input e dell'output può essere eseguito all'interno dello stesso comando.
Ora che stai eseguendo i comandi ping, ottieni le statistiche sul ping per ogni singolo sito web nell'elenco dei domini.
I risultati vengono stampati sullo standard output, che in questo caso è il terminale.
E se volessi salvare i risultati in un file?
Ciò può essere ottenuto combinando i reindirizzamenti di input e output sullo stesso comando .
$ ( while read ip; do ping -c 2 $ip; done ) < domains > stats.txt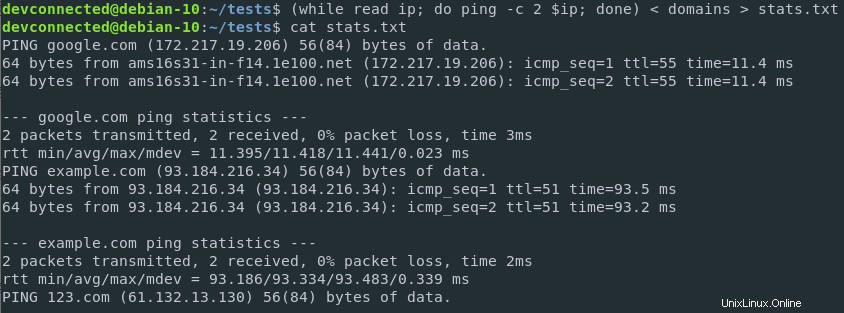
Grande!
I risultati sono stati salvati correttamente in un file e possono essere analizzati in seguito da altri team della tua azienda.
d – Eliminazione completa dello standard output
In alcuni casi, potrebbe essere utile eliminare completamente lo standard output.
Potrebbe essere perché non sei interessato all'output standard di un processo o perché questo processo sta stampando troppe righe sullo standard output.
Per eliminare completamente lo standard output su Linux, reindirizza lo standard output su /dev/null.
Il reindirizzamento a /dev/null fa sì che i dati vengano completamente eliminati e cancellati.
$ cat file > /dev/nullNota:il reindirizzamento a /dev/null non cancella il contenuto del file ma scarta solo il contenuto dello standard output.
4 – Che cos'è il reindirizzamento degli errori standard su Linux?
Infine, dopo il reindirizzamento di input e output, vediamo come è possibile reindirizzare l'errore standard.
a – Come funziona il reindirizzamento degli errori standard?
In modo molto simile a quanto visto prima, il reindirizzamento degli errori sta reindirizzando gli errori restituiti dai processi a un dispositivo definito sul tuo host.
Ad esempio, se eseguo un comando con parametri errati, quello che vedo sullo schermo è un messaggio di errore ed è stato elaborato tramite il descrittore di file responsabile dei messaggi di errore (fd[2]).>
Nota che non ci sono modi banali per differenziare un messaggio di errore da un messaggio di output standard nel terminale, dovrai fare affidamento sul programmatore che invia messaggi di errore al descrittore di file corretto.
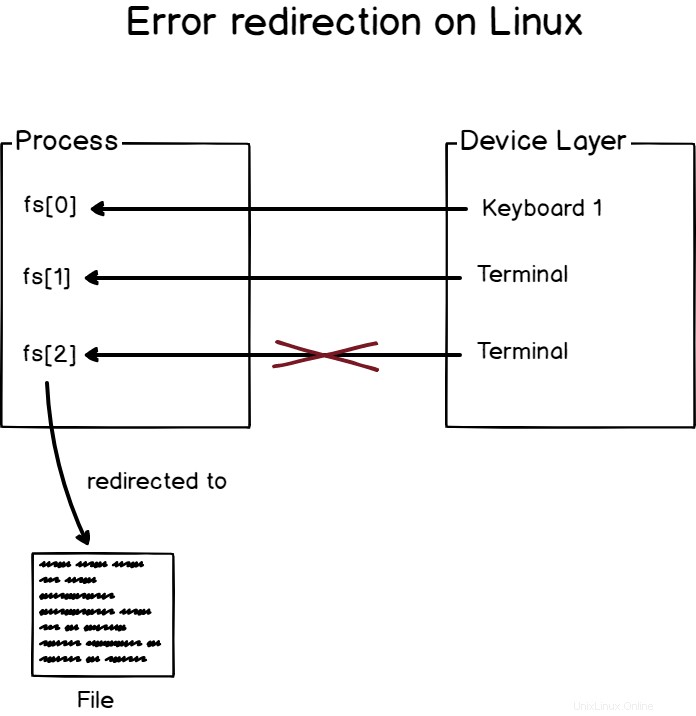
Per reindirizzare l'output di errore su Linux, utilizzare il file "2> ” operatore
$ command 2> fileUsiamo l'esempio del comando ping per generare un messaggio di errore sul terminale.

Ora vediamo una versione in cui l'output dell'errore viene reindirizzato a un file di errore.

Come puoi vedere, ho usato l'operatore "2>" per reindirizzare gli errori al file "file di errore".
Se dovessi reindirizzare solo l'output standard al file, non verrebbe stampato nulla su di esso.

Come puoi vedere, il messaggio di errore è stato stampato sul mio terminale e non è stato aggiunto nulla al mio output "file normale".
b – Combinazione dell'errore standard con l'output standard
In alcuni casi, potresti voler combinare i messaggi di errore con l'output standard e reindirizzarlo a un file.
Può essere particolarmente utile perché alcuni programmi non restituiscono solo messaggi standard o messaggi di errore, ma un mix di due.
Prendiamo l'esempio di trova comando.
Se eseguo un comando find nella directory principale senza i diritti sudo, potrei non essere autorizzato ad accedere ad alcune directory, ad esempio processi che non possiedo.
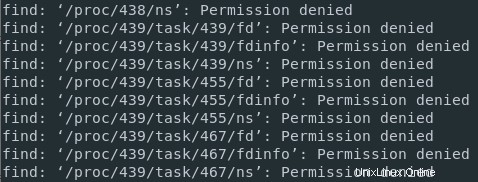
Di conseguenza, ci sarà un mix di messaggi standard (i file di proprietà del mio utente) e messaggi di errore (quando provo ad accedere a una directory che non possiedo).
In questo caso, voglio che entrambi gli output siano archiviati in un file.
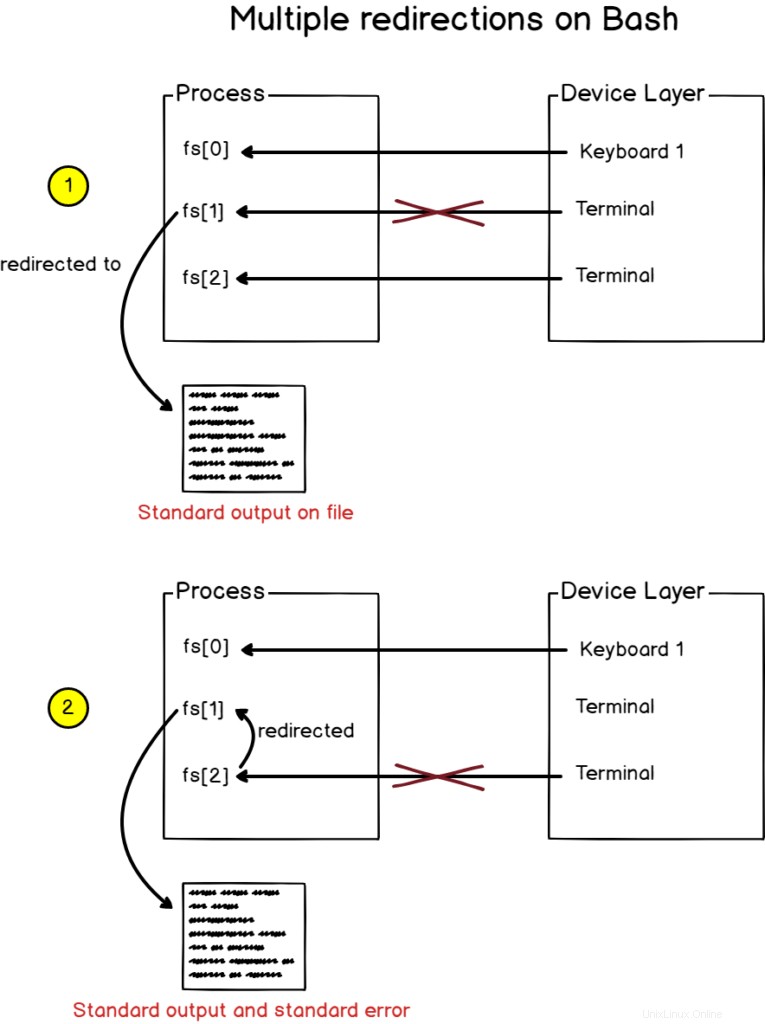
Per reindirizzare l'output standard e l'output dell'errore in un file, utilizza la sintassi "2<&1" preceduta da ">".
$ find / -user devconnected > file 2>&1In alternativa, puoi utilizzare “&>” sintassi come un modo più breve per reindirizzare sia l'output che gli errori.
$ find / -user devconnected &> fileAllora cosa è successo qui?
Quando bash vede più reindirizzamenti, li elabora da sinistra a destra.
Di conseguenza, l'output della funzione di ricerca viene prima reindirizzato al file.
Successivamente, viene elaborato il secondo reindirizzamento e reindirizza l'errore standard allo standard output (che era stato precedentemente assegnato al file).
5 – Cosa sono le pipeline su Linux?
Le pipeline sono leggermente diverse dai reindirizzamenti.
Quando eseguivi il reindirizzamento dell'input o dell'output standard, in pratica stavi sovrascrivendo l'input o l'output predefinito in un file personalizzato.
Con le pipeline, non stai sovrascrivendo input o output, ma li stai collegando insieme.
Le pipeline vengono utilizzate sui sistemi Linux per collegare i processi tra loro, collegando gli output standard di un programma all'input standard di un altro.
È possibile collegare più processi insieme a condutture (o tubi )
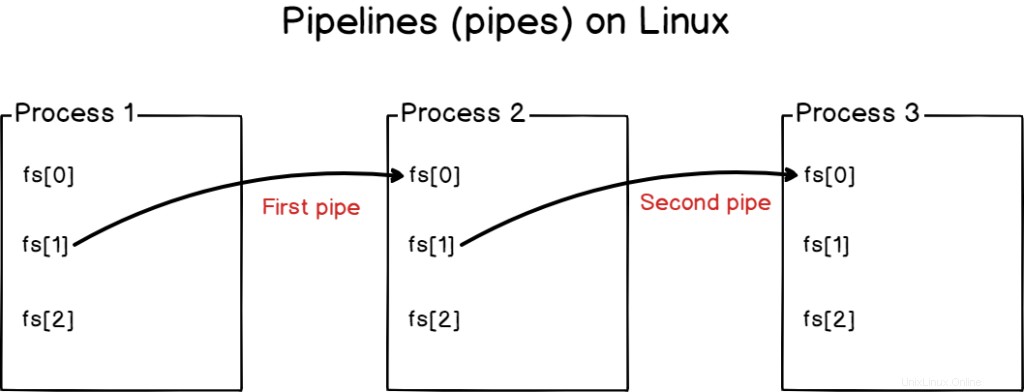
Le pipe sono molto utilizzate dagli amministratori di sistema per creare query complesse combinando insieme query semplici.
Uno degli esempi più popolari è probabilmente il conteggio del numero di righe in un file di testo, dopo aver applicato dei filtri personalizzati al contenuto del file.
Torniamo indietro al file dei domini che abbiamo creato nelle sezioni precedenti e cambiamo le estensioni dei loro paesi per includere i domini .net.
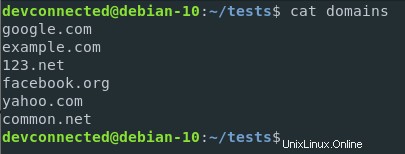
Ora supponiamo che tu voglia contare i numeri di domini .com nel file.
Come lo eseguiresti? Utilizzando i tubi.
Innanzitutto, vuoi filtrare i risultati per isolare solo i domini .com nel file. Quindi, vuoi reindirizzare il risultato al comando "wc" per contarli.
Ecco come conteggiare i domini .com nel file.
$ grep .com domains | wc -l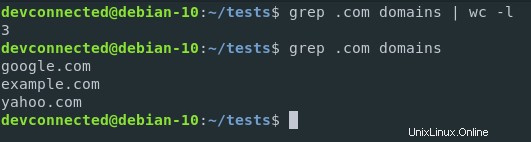
Ecco cosa è successo con un diagramma nel caso non riuscissi ancora a capirlo.
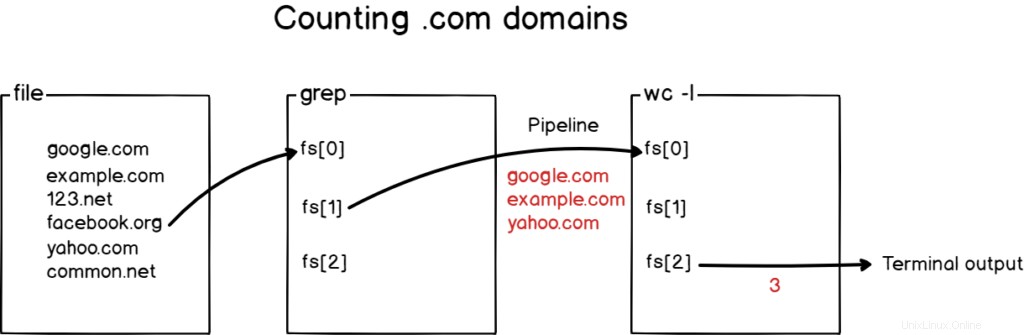
Fantastico!
6 – Conclusione
Nel tutorial di oggi, hai imparato cos'è il reindirizzamento di input e output e come può essere utilizzato efficacemente per eseguire operazioni amministrative sul tuo sistema Linux.
Hai anche imparato a conoscere i oleodotti (o tubi) che vengono utilizzati per concatenare i comandi al fine di eseguire comandi più lunghi e complessi sul tuo host.
Se sei curioso dell'amministrazione di Linux, abbiamo un'intera categoria dedicata ad essa su devconnected, quindi assicurati di dare un'occhiata!