"Replica dei dati e gestione della capacità" descrive perfettamente i miei primi anni nell'ambiente di supporto aziendale. Sebbene mi sia piaciuto diventare una PMI di replica, ho sempre odiato esaminare i problemi di capacità. Questa avversione era in parte dovuta al fatto che i problemi di capacità venivano quasi sempre ignorati fino a quando un cliente non si trovava in modalità di perdita di dati completa. Era anche dovuto al fatto che lavorare con algoritmi di compressione e deduplicazione può rendere un po' complicata la capacità di archiviazione.
Come ingegnere di supporto junior, mi sono ritrovato a utilizzare il df e du comandi per capire perché non potevo applicare una patch di sistema o esattamente dove si stava verificando tutto l'affollamento dei dati. Oggi esamineremo questi comandi, li suddivideremo nei loro casi d'uso e spiegheremo la discrepanza tra i due.
df
Il comando "senza disco" è un fantastico strumento da riga di comando che ti offre una rapida visualizzazione di 30.000 piedi del tuo filesystem e di tutti i dischi montati. Ti dice la dimensione totale del disco, lo spazio utilizzato, lo spazio disponibile, la percentuale di utilizzo e su quale partizione è montato il disco. Consiglio di accoppiarlo con -h flag per rendere i dati leggibili dall'uomo. Le cifre che vedi qui sono calcolate dal punto di montaggio o dal livello del filesystem:
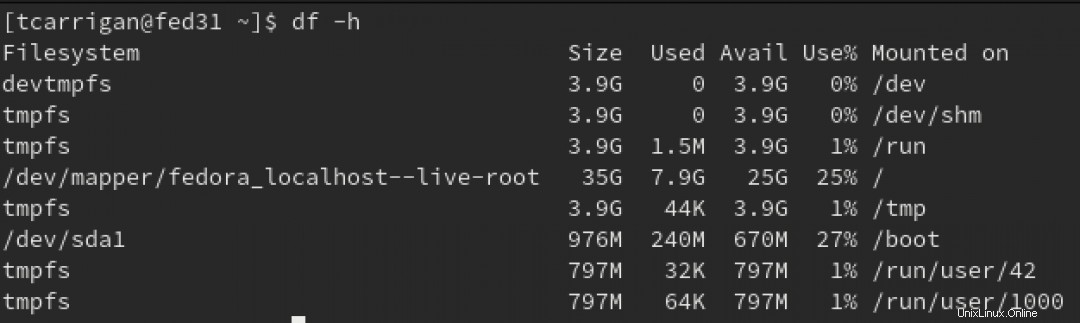
Inoltre, nota che usando il -h flag arrotonda i tuoi dati per renderli più facili da digerire, quindi il tuo 3G potrebbe essere vicino a 2,9G o 3,1G. Non puoi esserne sicuro.
du
Il comando "utilizzo del disco" è eccellente se applicato nel contesto corretto. Questo comando dà il meglio di sé quando devi vedere le dimensioni di una determinata directory o sottodirectory. Viene eseguito a livello di oggetto e segnala solo le statistiche specificate al momento dell'esecuzione. Mi piace accoppiare questo comando con -sh flag per fornire un riepilogo leggibile dall'uomo di un oggetto specificato (la directory e tutte le sottodirectory), come puoi vedere qui:

df rispetto a du
Quindi quali sono i casi d'uso per ciascun comando e in quale output del comando dovresti riporre la tua fiducia? La risposta (molto complicata) può essere riassunta al meglio in questo modo:il df Il comando fornisce un'ampia cifra per quanto spazio viene utilizzato sul filesystem nel suo insieme. Il du comando è un'istantanea molto più accurata di una determinata directory o sottodirectory.
Se dovessi scommettere su quale comando stava dicendo la "verità", scommetterei su du . Ad esempio, se ricevo un errore nel tentativo di installare un pacchetto in /var che dice che la directory è piena, posso eseguire il df comando per confermare che questo è vero. Una volta che posso vedere quel /var è al massimo, posso eseguire du /var per vedere quale sottodirectory mi sta dando il problema. Potrei quindi continuare a utilizzare df per restringere la sottodirectory fino a quando non ho trovato il colpevole.
Comprendere le differenze in questi comandi ci consente di utilizzare questi strumenti in tandem per identificare e risolvere rapidamente la maggior parte dei problemi di capacità che dobbiamo affrontare come amministratori di sistema.
Vuoi provare Red Hat Enterprise Linux? Scaricalo ora gratuitamente.