Eseguo sempre il backup dei file di configurazione o di tutti i vecchi file da qualche parte nel mio disco rigido prima di modificarli o modificarli, quindi posso ripristinarli dal backup se accidentalmente ho fatto qualcosa di sbagliato. Ma il problema è che ho dimenticato di ripulire quei file e il mio disco rigido è pieno di molti file duplicati dopo un certo periodo di tempo. Mi sento troppo pigro per pulire i vecchi file o ho paura di poter eliminare un file importante. Se sei come me e sei sopraffatto da più copie degli stessi file in diverse directory di backup, puoi trovare ed eliminare i file duplicati utilizzando gli strumenti forniti di seguito in sistemi operativi simili a Unix.
Un avvertimento:
Si prega di fare attenzione durante l'eliminazione dei file duplicati. Se non stai attento, ti porterà a una perdita accidentale di dati . Ti consiglio di prestare particolare attenzione durante l'utilizzo di questi strumenti.
Trova ed elimina file duplicati in Linux
Ai fini di questa guida, parlerò di tre utilità, ovvero,
- Trova,
- Due,
- FSlint.
Queste tre utilità sono gratuite, open source e funzionano sulla maggior parte dei sistemi operativi simili a Unix.
1. Trova
Rdfind , sta per r edundant d ata trova , è un'utilità gratuita e open source per trovare file duplicati in e/o all'interno di directory e sottodirectory. Confronta i file in base al loro contenuto, non ai nomi dei file. Rdfind utilizza la classifica algoritmo per classificare file originali e duplicati. Se hai due o più file uguali, Rdfind è abbastanza intelligente da trovare quale è il file originale e considerare il resto dei file come duplicati. Una volta trovati i duplicati, te li segnalerà. Puoi decidere di eliminarli o sostituirli con collegamenti reali o link simbolici (soft) .
Installazione di Rdfind
Rdfind è disponibile in AUR . Quindi, puoi installarlo in sistemi basati su Arch utilizzando qualsiasi programma di supporto AUR come Yay come mostrato di seguito.
$ yay -S rdfind
Su Debian, Ubuntu, Linux Mint:
$ sudo apt-get install rdfind
Su Fedora:
$ sudo dnf install rdfind
Su RHEL, CentOS:
$ sudo yum install epel-release
$ sudo yum install rdfind
Utilizzo
Una volta installato, esegui semplicemente il comando Rdfind insieme al percorso della directory per cercare i file duplicati.
$ rdfind ~/Downloads
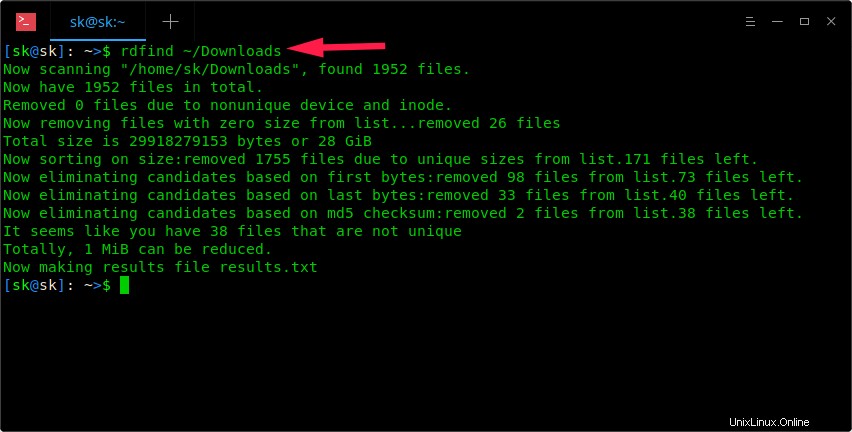
Scansiona una directory con Rdfind
Come puoi vedere nello screenshot sopra, il comando Rdfind analizzerà la directory ~/Download e salverà i risultati in un file chiamato results.txt nella directory di lavoro corrente. È possibile visualizzare il nome dei possibili file duplicati nel file results.txt.
$ cat results.txt # Automatically generated # duptype id depth size device inode priority name DUPTYPE_FIRST_OCCURRENCE 1469 8 9 2050 15864884 1 /home/sk/Downloads/tor-browser_en-US/Browser/TorBrowser/Tor/PluggableTransports/fte/tests/dfas/test5.regex DUPTYPE_WITHIN_SAME_TREE -1469 8 9 2050 15864886 1 /home/sk/Downloads/tor-browser_en-US/Browser/TorBrowser/Tor/PluggableTransports/fte/tests/dfas/test6.regex [...] DUPTYPE_FIRST_OCCURRENCE 13 0 403635 2050 15740257 1 /home/sk/Downloads/Hyperledger(1).pdf DUPTYPE_WITHIN_SAME_TREE -13 0 403635 2050 15741071 1 /home/sk/Downloads/Hyperledger.pdf # end of file
Esaminando il file results.txt, puoi trovare facilmente i duplicati. Puoi rimuovere i duplicati manualmente se lo desideri.
Inoltre, puoi -dryrun opzione per trovare tutti i duplicati in una determinata directory senza modificare nulla e visualizzare il riepilogo nel tuo Terminale:
$ rdfind -dryrun true ~/Downloads
Una volta trovati i duplicati, puoi sostituirli con collegamenti fisici o collegamenti simbolici.
Per sostituire tutti i duplicati con hardlink, esegui:
$ rdfind -makehardlinks true ~/Downloads
Per sostituire tutti i duplicati con collegamenti simbolici/soft link, eseguire:
$ rdfind -makesymlinks true ~/Downloads
Potresti avere dei file vuoti in una directory e volerli ignorare. In tal caso, utilizza -ignoreempty opzione come di seguito.
$ rdfind -ignoreempty true ~/Downloads
Se non vuoi più i vecchi file, elimina i file duplicati invece di sostituirli con collegamenti fisici o virtuali.
Per eliminare tutti i duplicati, esegui semplicemente:
$ rdfind -deleteduplicates true ~/Downloads
Se non vuoi ignorare i file vuoti ed eliminarli insieme a tutti i duplicati, esegui:
$ rdfind -deleteduplicates true -ignoreempty false ~/Downloads
Per maggiori dettagli, fare riferimento alla sezione della guida:
$ rdfind --help
E, le pagine di manuale:
$ man rdfind
Lettura consigliata:
- Rimuovi i file duplicati dal tuo Android con il correttore di file duplicati
2. Dupe
Fdupe è un'altra utilità della riga di comando per identificare e rimuovere i file duplicati all'interno di directory e sottodirectory specificate. È un'utilità open source gratuita scritta in C linguaggio di programmazione. Fdupes identifica i duplicati confrontando le dimensioni dei file, le firme MD5 parziali, le firme MD5 complete e, infine, eseguendo un confronto byte per byte per la verifica.
Simile all'utilità Rdfind, Fdupes viene fornito con una manciata di opzioni per eseguire operazioni, come:
- Cerca ricorsivamente i file duplicati nelle directory e nelle sottodirectory
- Escludi dalla considerazione i file vuoti ei file nascosti
- Mostra la dimensione dei duplicati
- Elimina immediatamente i duplicati non appena si sono incontrati
- Escludi file con proprietario/gruppo o bit di autorizzazione diversi come duplicati
- E molto altro ancora.
Installazione di Fdupes
Fdupes è disponibile nei repository predefiniti della maggior parte delle distribuzioni Linux.
Su Arch Linux e le sue varianti come Antergos, Manjaro Linux, installalo usando Pacman come di seguito.
$ sudo pacman -S fdupes
Su Debian, Ubuntu, Linux Mint:
$ sudo apt-get install fdupes
Su Fedora:
$ sudo dnf install fdupes
Su RHEL, CentOS:
$ sudo yum install epel-release
$ sudo yum install fdupes
Utilizzo
L'utilizzo di Fdupes è piuttosto semplice. Basta eseguire il comando seguente per scoprire i file duplicati in una directory, ad esempio ~/Downloads .
$ fdupes ~/Downloads
Esempio di output dal mio sistema:
/home/sk/Downloads/Hyperledger.pdf /home/sk/Downloads/Hyperledger(1).pdf
Come puoi vedere, ho un file duplicato in /home/sk/Downloads/ directory. Mostra solo i duplicati dalla directory principale. Come visualizzare i duplicati dalle sottodirectory? Usa semplicemente -r opzione come di seguito.
$ fdupes -r ~/Downloads
Ora vedrai i duplicati da /home/sk/Downloads/ directory e anche le sue sottodirectory.
Fdupes può anche essere in grado di trovare duplicati da più directory contemporaneamente.
$ fdupes ~/Downloads ~/Documents/ostechnix
Puoi anche cercare in più directory, una ricorsivamente come di seguito:
$ fdupes ~/Downloads -r ~/Documents/ostechnix
I comandi precedenti cercano i duplicati nella directory "~/Downloads" e nella directory "~/Documents/otechnix" e nelle sue sottodirectory.
A volte, potresti voler conoscere la dimensione dei duplicati in una directory. In tal caso, usa -S opzione come di seguito.
$ fdupes -S ~/Downloads 403635 bytes each: /home/sk/Downloads/Hyperledger.pdf /home/sk/Downloads/Hyperledger(1).pdf
Allo stesso modo, per visualizzare le dimensioni dei duplicati nelle directory padre e figlio, utilizzare -Sr opzione.
Possiamo escludere dalla considerazione i file vuoti e nascosti utilizzando -n e -A rispettivamente.
$ fdupes -n ~/Downloads
$ fdupes -A ~/Downloads
Il primo comando escluderà dalla considerazione i file di lunghezza zero e il secondo escluderà dalla considerazione i file nascosti durante la ricerca di duplicati nella directory specificata.
Per riassumere le informazioni sui file duplicati, utilizza -m opzione.
$ fdupes -m ~/Downloads 1 duplicate files (in 1 sets), occupying 403.6 kilobytes
Per eliminare tutti i duplicati, utilizza -d opzione.
$ fdupes -d ~/Downloads
Esempio di output:
[1] /home/sk/Downloads/Hyperledger Fabric Installation.pdf [2] /home/sk/Downloads/Hyperledger Fabric Installation(1).pdf Set 1 of 1, preserve files [1 - 2, all]:
Questo comando ti chiederà di conservare ed eliminare tutti gli altri duplicati. Basta inserire un numero qualsiasi per preservare il file corrispondente ed eliminare i file rimanenti. Prestare maggiore attenzione durante l'utilizzo di questa opzione. Potresti eliminare i file originali se non stai attento.
Se vuoi conservare il primo file in ogni serie di duplicati ed eliminare gli altri senza chiedere ogni volta, usa -dN opzione (non consigliata).
$ fdupes -dN ~/Downloads
Per eliminare i duplicati quando vengono rilevati, utilizza -I bandiera.
$ fdupes -I ~/Downloads
Per maggiori dettagli su Fdupes, guarda la sezione della guida e le pagine man.
$ fdupes --help
$ man fdupes
Leggi anche:
- Correttore di foto duplicate:organizza bene la tua libreria di foto
3. Flint
FSlint è un'altra utility per la ricerca di file duplicati che utilizzo di tanto in tanto per eliminare i file duplicati non necessari e liberare spazio su disco nel mio sistema Linux. A differenza delle altre due utilità, FSlint ha entrambe le modalità GUI e CLI. Quindi, è uno strumento più intuitivo per i principianti. FSlint non trova solo i duplicati, ma anche collegamenti simbolici errati, nomi errati, file temporanei, IDS errati, directory vuote e binari non spogliati ecc.
Installazione di FSlint
FSlint è disponibile in AUR , quindi puoi installarlo utilizzando qualsiasi helper AUR.
$ yay -S fslint
Su Debian, Ubuntu, Linux Mint:
$ sudo apt-get install fslint
Su Fedora:
$ sudo dnf install fslint
Su RHEL, CentOS:
$ sudo yum install epel-release
$ sudo yum install fslint
Una volta installato, avvialo dal menu o dall'utilità di avvio dell'applicazione.
Ecco come appare la GUI di FSlint.
Interfaccia FSlint
Come puoi vedere, l'interfaccia di FSlint è intuitiva e autoesplicativa. Nel percorso di ricerca scheda, aggiungi il percorso della directory che desideri scansionare e fai clic su Trova pulsante nell'angolo in basso a sinistra per trovare i duplicati. Seleziona l'opzione ricorsiva per cercare in modo ricorsivo i duplicati nelle directory e nelle sottodirectory. FSlint analizzerà rapidamente la directory data e le elencherà.
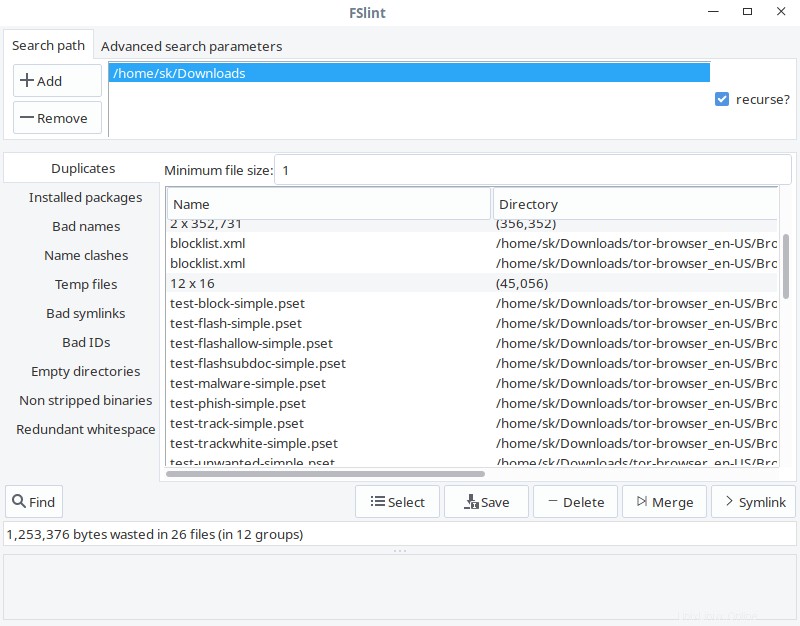
GUI di fslint
Dall'elenco, scegli i duplicati che desideri pulire e seleziona uno qualsiasi di essi in base ad azioni come Salva, Elimina, Unisci e Collegamento simbolico.
Nei Parametri di ricerca avanzata scheda, puoi specificare i percorsi da escludere durante la ricerca di duplicati.
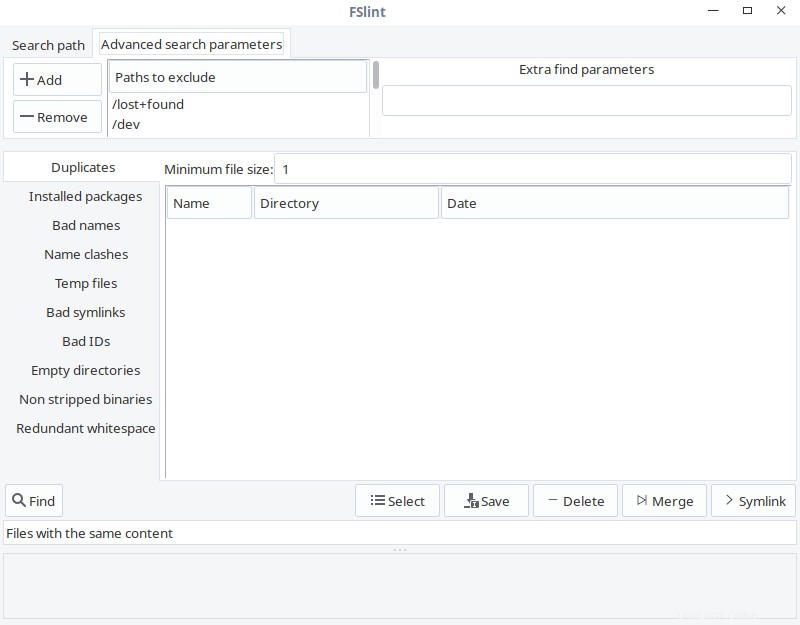
fslint ricerca avanzata
Opzioni della riga di comando di FSlint
FSlint fornisce una raccolta delle seguenti utilità CLI per trovare duplicati nel tuo filesystem:
- scoperta -- trova i file DUplicate
- trovanl -- trova Name Lint (problemi con i nomi dei file)
- findu8 -- trova nomi di file con codifica utf8 non valida
- trovabl -- trova collegamenti errati (vari problemi con i collegamenti simbolici)
- trova -- trova lo stesso nome (problemi con i nomi in conflitto)
- trovato -- trova le directory vuote
- trovato -- trova i file con ID utente morti
- trova -- trova eseguibili non strippati
- trova -- trova spazi bianchi ridondanti nei file
- trova -- trova i file temporanei
- trova -- trova biblioteche possibilmente inutilizzate
- zipdir -- Recupera lo spazio sprecato nelle voci della directory ext2
Tutte queste utilità sono disponibili in /usr/share/fslint/fslint/fslint posizione.
Ad esempio, per trovare duplicati in una determinata directory, eseguire:
$ /usr/share/fslint/fslint/findup ~/Downloads/
Allo stesso modo, per trovare directory vuote, il comando sarebbe:
$ /usr/share/fslint/fslint/finded ~/Downloads/
Per ottenere maggiori dettagli su ciascuna utilità, ad esempio findup , esegui:
$ /usr/share/fslint/fslint/findup --help
Per maggiori dettagli su FSlint, fare riferimento alla sezione della guida e alle pagine man.
$ /usr/share/fslint/fslint/fslint --help
$ man fslint
Conclusione
Ora conosci tre strumenti per trovare ed eliminare file duplicati indesiderati in Linux. Tra questi tre strumenti, utilizzo spesso Rdfind. Ciò non significa che le altre due utilità non siano efficienti, ma finora sono semplicemente soddisfatto di Rdfind. Bene, è il tuo turno. Qual è il tuo strumento preferito e perché? Facci sapere nella sezione commenti qui sotto.