Durante il download dei file, non è raro vedere il .tar , .zip o .gz estensioni. Ma conosci la differenza tra Tar e Zip e Gz? Perché li usiamo e quale è più efficiente, tar o zip o gz?
Differenza tra tar, zip e gz
Se hai fretta o vuoi semplicemente ottenere qualcosa di facile da ricordare, ecco la differenza tra zip e tar e gz:
.tar ==file di archivio non compresso
.zip ==(di solito) file di archivio compresso
.gz ==file (archivio o meno) compresso con gzip

Un po' di cronologia dei file di archivio
Come molte cose sui sistemi Unix e simili a Unix, la storia inizia molto, molto tempo fa, in una galassia non così lontana chiamata anni Settanta. In una fredda mattina del gennaio 1979, il catrame l'utilità ha fatto la sua comparsa come parte della nuova versione Unix V7.
Il tar L'utilità è stata progettata come un modo per scrivere in modo efficiente molti file su nastri. Anche se al giorno d'oggi le unità nastro sono sconosciute alla stragrande maggioranza dei singoli utenti Linux, tarball — il soprannome di tar archivi — sono ancora comunemente usati per impacchettare diversi file o persino l'intero albero di directory (o persino le foreste) in un unico file.
Una cosa fondamentale da ricordare è un semplice tar il file è solo un archivio i cui dati non sono compressi. In altre parole, se esegui il tar di 100 file da 50kB, ti ritroverai con un archivio la cui dimensione sarà di circa 5000kB. L'unico vantaggio che puoi aspettarti usando tar da solo sarebbe evitare lo spazio sprecato dal file system poiché la maggior parte di essi alloca spazio con una certa granularità (ad esempio, sul mio sistema, un file lungo un byte utilizza 4 kB di spazio su disco, 1000 di utilizzeranno 4 MB ma l'archivio tar corrispondente "solo" 1 MB).
| Vale la pena menzionare qui tar non è certamente l'unico strumento Unix standard per creare archivi. I programmatori probabilmente sanno ar in quanto viene utilizzato principalmente oggi per creare librerie statiche, che non sono altro che archivi di compilati File. Ma ar può essere utilizzato per creare archivi di qualsiasi tipo. Infatti, .deb i file di pacchetto utilizzati sui sistemi Debian sono ar archivi! E su MacOS X, mpkg i pacchetti sono (erano?) compressi con gzip cpio archivi. Detto questo, né ar né cpio guadagnato tanto quanto la popolarità di tar tra gli utenti. Forse perché il comando tar era abbastanza buono e più semplice da usare. |

Creare archivi è bello. Ma con il passare del tempo e con l'avvento dell'era dei personal computer, le persone si sono rese conto che potevano risparmiare enormi quantità di spazio di archiviazione comprimendo dati. Quindi un decennio dopo l'introduzione o tar , comprimi è uscito nel mondo MS-DOS come un formato di archivio che supporta la compressione . Lo schema di compressione più comune per zip è sgonfia che a sua volta è un'implementazione dell'algoritmo LZ77. Ma essendo sviluppato commercialmente da PKWARE, zip formato ha sofferto per anni di brevetti gravosi.
Quindi, in parallelo, gzip è stato creato per implementare l'algoritmo LZ77 in un software libero senza violare alcun brevetto PKWARE.
Un elemento chiave della filosofia Unix è "Fai una cosa e falla bene" , gzip è stato progettato per solo comprimere i file. Quindi, per creare un archivio compresso , devi prima creare un archivio utilizzando tar utilità per esempio. E dopo, dovrai comprimere quell'archivio. Questo è un .tar.gz file (a volte abbreviato in .tgz per aggiungere ancora a quella confusione e per rispettare le limitazioni dei nomi di file MS-DOS 8.3 da tempo dimenticate).
Con l'evoluzione dell'informatica, altri algoritmi di compressione sono stati progettati per un rapporto di compressione più elevato. Ad esempio, l'algoritmo Burrows–Wheeler implementato in bzip2 (che porta a .tar.bz2 archivi). O più recentemente xz che è un LZMA implementazione di un algoritmo simile a quella usata in 7zip utilità.
Disponibilità e limitazioni
Oggi puoi utilizzare liberamente qualsiasi formato di file di archivio sia su Linux che su Windows.
Ma come zip Il formato è supportato nativamente su Windows, questo è presente soprattutto in ambienti multipiattaforma. Puoi persino trovare il zip formato di file in luoghi imprevisti. Ad esempio, quel formato di file è stato mantenuto da Sun per JAR archivi utilizzati per distribuire le applicazioni Java compilate. O per i file OpenDocument(.odf , .odp …) utilizzato da LibreOffice o altre suite per ufficio. Tutti questi formati di file sono archivi zip sotto mentite spoglie. Se sei curioso, non esitare a decomprimere uno di loro per vedere cosa c'è dentro:
sh$ unzip some-file.odt Archive:some-file.odt extracting: mimetype inflating: meta.xml inflating: settings.xml inflating: content.xm [...] inflating: styles.xml inflating: META-INF/manifest.xml
Tutto ciò detto, nel mondo simile a Unix, Io preferirei comunque tar tipo di archivio perché zip il formato file non supporta tutti i metadati del file system Unix in modo affidabile. Per alcune spiegazioni concrete di quest'ultima affermazione, devi sapere che il formato del file ZIP definisce solo un piccolo insieme di attributi di file obbligatori da memorizzare per ogni voce:nome file, data di modifica, autorizzazioni. Oltre a questi attributi di base, un archiviatore può memorizzare metadati aggiuntivi nel cosiddetto campo aggiuntivo dell'intestazione ZIP. Tuttavia, poiché i campi aggiuntivi sono definiti dall'implementazione, non ci sono garanzie nemmeno per gli archivi conformi di archiviare o recuperare lo stesso set di metadati. Controlliamolo su un archivio di esempio:
sh$ ls -lsn data/team total 0 0 -rw-r--r-- 1 1000 2000 0 Jan 30 12:29 team sh$ zip -0r archive.zip data/
sh$ zipinfo -v archive.zip data/team Central directory entry #5: --------------------------- data/team [...] apparent file type: binary Unix file attributes (100644 octal): -rw-r--r-- MS-DOS file attributes (00 hex): none The central-directory extra field contains: - A subfield with ID 0x5455 (universal time) and 5 data bytes. The local extra field has UTC/GMT modification/access times. - A subfield with ID 0x7875 (Unix UID/GID (any size)) and 11 data bytes: 01 04 e8 03 00 00 04 d0 07 00 00.
Come puoi vedere, le informazioni sulla proprietà (UID/GID) fanno parte del campo aggiuntivo:potrebbe non essere ovvio se non conosci l'esadecimale, né i metadati ZIP sono memorizzati little-endian, ma in breve "e803" è "03e8" con è "1000", l'UID del file. E "07d0" è "d007" che è 2000, il file GID.
In quel caso particolare, Info-ZIP zip lo strumento disponibile sul mio sistema Debian ha memorizzato alcuni metadati utili nel campo extra. Ma non vi è alcuna garanzia che questo campo aggiuntivo venga scritto da ogni archiviatore. E anche se presente, non vi è alcuna garanzia che ciò venga compreso dallo strumento utilizzato per estrarre l'archivio.
Mentre non possiamo rifiutare la tradizione come motivazione per continuare a usare tarball , con questo piccolo esempio, capisci perché ci sono ancora alcuni casi (d'angolo?) in cui tar non può essere sostituito da zip . Ciò è particolarmente vero quando vuoi preservare tutto metadati di file standard.
Tar vs Zip vs Test di efficienza Gz
Parlerò qui dell'efficienza dello spazio, non dell'efficienza del tempo, ma come regola pratica, più potenzialmente efficiente è un algoritmo di compressione, richiede più CPU.
E per darti un'idea del rapporto di compressione ottenuto utilizzando diversi algoritmi, ho raccolto sul mio disco rigido circa 100 MB di file dai formati di file più diffusi. Ecco i risultati ottenuti sul mio sistema Debian Stretch (tutte le dimensioni riportate da du -sh ):
| tipo di file | .jpg | .mp3 | .mp4 | .odt | .png | .txt |
| numero di file | 2163 | 45 | 279 | 2990 | 2072 | 4397 |
| spazio su disco | 98M | 99M | 99M | 98M | 98M | 98M |
| tar | 94M | 99M | 98M | 93M | 92M | 89M |
| zip (nessuna compressione) | 92M | 99M | 98M | 91M | 91M | 86M |
| zip (sgonfia) | 87M | 98M | 93M | 85M | 77M | 28M |
| tar + gzip | 86M | 98M | 93M | 82M | 77M | 27M |
| tar + bz2 | 87M | 98M | 93M | 42M | 71M | 22M |
| tar + xz | 70M | 98M | 22M | 348K | 51M | 19M |
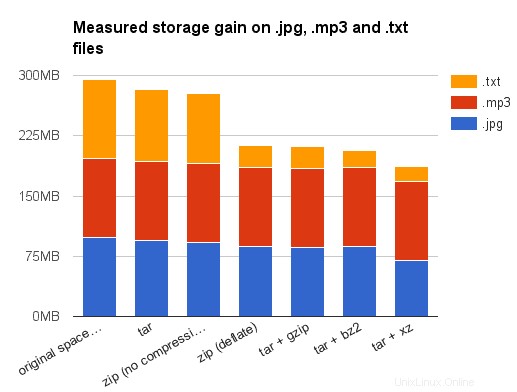 In primo luogo, ti incoraggio a prendere questi risultati con le pinze:i file di dati erano in realtà file sospesi in giro sul mio disco rigido e non affermerei che siano rappresentativi in alcun modo. Quindi, devo confessare che non ho scelto quei tipi di file a caso. L'ho già detto, .odt i file sono già file zip. Quindi il modesto guadagno ottenuto comprimendoli una seconda volta non sorprende (tranne bzip2 o xy, ma io vorrei consideralo come un'anomalia statistica causata dalla bassa eterogeneità dei miei file di dati, contenenti diversi backup o versioni funzionanti degli stessi documenti).
In primo luogo, ti incoraggio a prendere questi risultati con le pinze:i file di dati erano in realtà file sospesi in giro sul mio disco rigido e non affermerei che siano rappresentativi in alcun modo. Quindi, devo confessare che non ho scelto quei tipi di file a caso. L'ho già detto, .odt i file sono già file zip. Quindi il modesto guadagno ottenuto comprimendoli una seconda volta non sorprende (tranne bzip2 o xy, ma io vorrei consideralo come un'anomalia statistica causata dalla bassa eterogeneità dei miei file di dati, contenenti diversi backup o versioni funzionanti degli stessi documenti).
Riguardo a .jpg , .mp3 e .mp4 ora:forse sai che quelli sono già file di dati compresso. Ancora meglio, potresti aver sentito che usano la compressione distruttiva . Ciò significa che non puoi ricostruire esattamente l'immagine originale dopo una compressione JPEG. Ed è vero. Ma ciò che è poco noto è dopo la fase di compressione distruttiva di per sé , i dati vengono compressi una seconda volta utilizzando l'algoritmo non distruttivo Huffman a lunghezza di parola variabile per rimuovere la ridondanza dei dati.
Per tutti questi motivi, ci si aspettava che la compressione di immagini JPEG o file MP3/MP4 non portasse a guadagni elevati. Si prega di notare che un file tipico contiene sia i dati altamente compressi che alcuni metadati non compressi, possiamo ancora guadagnare qualcosa lì. Questo spiega perché ho ancora un notevole vantaggio per le immagini JPEG poiché ne avevo molte, quindi la dimensione complessiva dei metadati non era così trascurabile rispetto alla dimensione totale del file. Ancora una volta, i risultati sorprendenti durante la compressione di file MP4 utilizzando xz sono probabilmente legati alle elevate somiglianze tra i vari file MP4 utilizzati durante i miei test. O no?
Per sollevare eventualmente questi dubbi, ti incoraggio vivamente a fare i tuoi confronti. E non esitare a condividere le tue osservazioni con noi utilizzando la sezione commenti qui sotto!