Il meccanismo per eseguire il backup in Elasticsearch è chiamato Snapshot. Uno snapshot è un backup eseguito da un cluster Elasticsearch in uno stato in esecuzione. Non è necessario rimuovere il cluster, il che aiuta a evitare le finestre di manutenzione delle applicazioni. È possibile acquisire un'istantanea di un singolo indice o dell'intero cluster e archiviarla in un repository su un file system condiviso.
Gli snapshot in Elasticsearch vengono acquisiti in modo incrementale. Ciò significa che quando crea uno snapshot di un indice, Elasticsearch evita di copiare i dati già archiviati come parte di uno snapshot precedente dello stesso indice. Pertanto può essere efficiente acquisire regolarmente istantanee del cluster.
Allo stesso modo in cui possiamo eseguire un backup del cluster in esecuzione, possiamo anche ripristinare uno snapshot in un cluster in esecuzione. Quando ripristiniamo un indice, possiamo persino modificare il nome dell'indice ripristinato e alcune delle sue impostazioni.
Per eseguire backup, è necessario registrare un repository di snapshot prima di poter eseguire le operazioni di snapshot e ripristino. Per registrare il repository del file system condiviso per il cluster, è necessario montare lo stesso file system condiviso nella stessa posizione su tutti i nodi master e dati. Questa posizione deve essere registrata nel file di configurazione su tutti i nodi master e dati.
In questo articolo verificheremo il repository condiviso NFS e vedremo i passaggi per acquisire uno snapshot e ripristinarlo.
Prerequisiti
- Directory condivisa NFS disponibile e montata su tutti e 3 i nodi di Elasticsearch nella stessa posizione
- Elasticsearch Cluster di 3 nodi su 3 server Ubuntu.
Cosa faremo
- Verifica la configurazione del server NFS.
- Verifica la configurazione del cluster di Elasticsearch
- Registra un repository per eseguire i backup.
- Fai un backup e ripristina.
Verifica la configurazione del server/client NFS.
In questo articolo, non parleremo della configurazione di NFS poiché non rientra nell'ambito di questo articolo. Ma per eseguire il backup di Elasticsearch avremmo bisogno della seguente configurazione.
es-node-1(10.11.10.61) : NFS Client
es-node-2(10.11.10.62) : NFS Client
es-node-3(10.11.10.63) : NFS Client
NFS Server(10.11.10.64) : NFS Server
Ecco,
Il server NFS ha condiviso il suo "/home/ubuntu/shared/" directory con nodi Elasticsearch.
Ogni Elasticsearch ha la sua directory locale "/home/ubuntu/mount" montato sulla directory condivisa di NFS "/home/ubuntu/shared/" . Dobbiamo assicurarci che la proprietà di tutte le directory appartenga allo stesso utente con cui vorremmo avviare Elasticsearch.
Una volta implementata questa configurazione, possiamo procedere oltre.
Verify Elasticsearch Cluster Configuration
Esegui le seguenti configurazioni per impostare Elasticsearch in modo che funzioni in modalità Cluster:
Qui, se hai impostato un cluster Elasticsearch devi essere a conoscenza della seguente configurazione.
L'unica configurazione che dobbiamo eseguire per separare Elasticsearch Cluster Backup dalla configurazione esistente di Elasticsearch Cluster è "path.repo:["/home/ubuntu/montato"] ":
vim config/elasticsearch.yml
path.repo: ["/home/ubuntu/mounted"]
Mantieni lo stesso su ogni nodo.
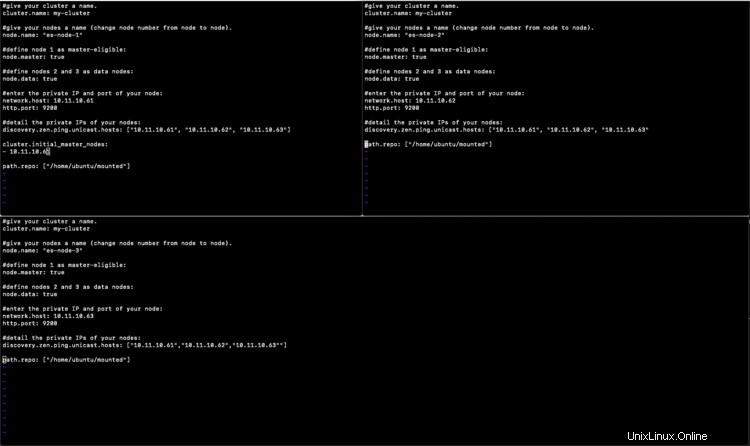
Configurazione su Node1
#give your cluster a name.
cluster.name: my-cluster
#give your nodes a name (change node number from node to node).
node.name: "es-node-1"
#define node 1 as master-eligible:
node.master: true
#define nodes 2 and 3 as data nodes:
node.data: true
#enter the private IP and port of your node:
network.host: 10.11.10.61
http.port: 9200
#detail the private IPs of your nodes:
discovery.zen.ping.unicast.hosts: ["10.11.10.61", "10.11.10.62", "10.11.10.63"]
cluster.initial_master_nodes:
- 10.11.10.61
path.repo: ["/home/ubuntu/mounted"]
Configurazione su Node2
#give your cluster a name.
cluster.name: my-cluster
#give your nodes a name (change node number from node to node).
node.name: "es-node-2"
#define node 2 as master-eligible:
node.master: false
#define nodes 2 and 3 as data nodes:
node.data: true
#enter the private IP and port of your node:
network.host: 10.11.10.62
http.port: 9200
#detail the private IPs of your nodes:
discovery.zen.ping.unicast.hosts: ["10.11.10.61", "10.11.10.62", "10.11.10.63"
path.repo: ["/home/ubuntu/mounted"]
Configurazione su Node3
#give your cluster a name.
cluster.name: my-cluster
#give your nodes a name (change node number from node to node).
node.name: "es-node-3"
#define node 3 as master-eligible:
node.master: false
#define nodes 2 and 3 as data nodes:
node.data: true
#enter the private IP and port of your node:
network.host: 10.11.10.63
http.port: 9200
#detail the private IPs of your nodes:
discovery.zen.ping.unicast.hosts: ["10.11.10.61","10.11.10.62","10.11.10.63""]
path.repo: ["/home/ubuntu/mounted"]
Una volta che hai tutta questa configurazione in atto, avvia tutti i nodi Elasticsearch, avviando prima il master iniziale.
Registra un repository per eseguire i backup
Controlla i repository esistenti usando il seguente comando.
curl -XGET 'http://IP_Of_Elasticsearch_Node_Or_Master:9200/_snapshot/_all?pretty=true'
Se riceviamo una risposta vuota, indica che non abbiamo ancora configurato alcun repository
Per configurare un repository, eseguire il comando seguente.
curl -XPUT 'http://IP_Of_Elasticsearch_Node_Or_Master:9200/_snapshot/my_backup' -d {
"type": "fs",
"settings": {
"location": "/home/ubuntu/mounted",
"compress": true
}
}' Qui, "my_backup" nel comando precedente è il nome del repository.
Possiamo controllare i repository registrati usando il seguente comando
curl -XGET 'http://IP_Of_Elasticsearch_Node_Or_Master:9200/_snapshot/_all?pretty=true'
Backup e ripristino di un cluster Elasticsearch
Fai un backup
Una volta creato un repository, siamo pronti per eseguire un backup.
Utilizzare il comando seguente per eseguire un backup denominato "snapshot_name"
curl -XPUT "https://IP_Of_Elasticsearch_Node_Or_Master:9200/_snapshot/my_backup/snapshot_name?wait_for_completion=true"
Ripristina un backup
L'istantanea che abbiamo acquisito può essere ripristinata utilizzando il seguente comando.
Utilizzare il comando seguente per ripristinare il backup denominato "snapshot_name"
curl -XPOST "http://IP_Of_Elasticsearch_Node_Or_Master:9200/_snapshot/my_backup/snapshot_name/_restore?wait_for_completion=true"
Conclusione
In questo articolo, abbiamo visto i passaggi per registrare un repository, eseguire un backup e ripristinarlo.