Kubernetes è una piattaforma open source per la gestione di carichi di lavoro e servizi containerizzati che facilita la configurazione dichiarativa e l'automazione. Il nome Kubernetes aveva origine dal greco, che significa timoniere o pilota. È portatile ed estensibile e ha un ecosistema in rapida crescita. I servizi e gli strumenti di Kubernetes sono ampiamente disponibili.
In questo articolo, analizzeremo una vista di 10.000 piedi dei componenti principali di Kubernetes, dalla composizione di ciascun container, al modo in cui un container in un pod viene distribuito e pianificato in ciascuno dei lavoratori. È fondamentale comprendere tutti i dettagli del cluster Kubernetes per poter distribuire e progettare una soluzione basata su Kubernetes come orchestratore per applicazioni containerizzate.
Ecco un breve riassunto delle cose che tratteremo in questo articolo:
- Componenti del pannello di controllo
- I componenti del lavoratore Kubernetes
- I pod come elementi costitutivi di base
- Servizi Kubernetes, bilanciatori di carico e controller Ingress
- Distribuzioni Kubernetes e set di daemon
- Archiviazione persistente in Kubernetes
Il piano di controllo di Kubernetes
I nodi principali di Kubernetes sono i luoghi in cui risiedono i servizi del piano di controllo principale; non tutti i servizi devono risiedere sullo stesso nodo; tuttavia, per centralizzazione e praticità, vengono spesso implementati in questo modo. Questo ovviamente solleva domande sulla disponibilità dei servizi; tuttavia, possono essere facilmente superati disponendo di più nodi e fornendo richieste di bilanciamento del carico per ottenere un set di nodi master ad alta disponibilità .
I nodi master sono composti da quattro servizi di base:
- Il kube-apiserver
- Il programmatore di kube
- Il kube-controller-manager
- Il database etcd
I nodi master possono essere eseguiti su server bare metal, macchine virtuali o un cloud privato o pubblico, ma non è consigliabile eseguire carichi di lavoro container su di essi. Vedremo di più su questo più avanti.
Il diagramma seguente mostra i componenti dei nodi principali di Kubernetes:
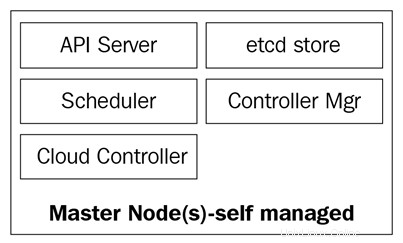
Il kube-apiserver
Il server API è ciò che unisce tutto insieme. È l'API REST front-end del cluster che riceve i manifest per creare, aggiornare ed eliminare oggetti API come servizi, pod, Ingress e altri.
Il kube-apiserver è l'unico servizio con cui dovremmo parlare; è anche l'unico che scrive e comunica con il database etcd per la registrazione dello stato del cluster. Con il comando kubectl, invieremo comandi per interagire con esso. Questo sarà il nostro coltellino svizzero quando si tratta di Kubernetes.
Il kube-controller-manager
Il daemon kube-controller-manager , in poche parole, è un insieme di cicli di controllo infiniti che vengono forniti per semplicità in un unico binario. Controlla lo stato desiderato definito del cluster e si assicura che sia realizzato e soddisfatto spostando tutti i bit e i pezzi necessari per raggiungerlo. Il kube-controller-manager non è solo un controller; contiene diversi loop che controllano diversi componenti nel cluster. Alcuni di essi sono il controller del servizio, il controller dello spazio dei nomi, il controller dell'account del servizio e molti altri. Puoi trovare ciascun controller e la sua definizione nel repository GitHub di Kubernetes:https://github.com/kubernetes/kubernetes/tree/master/pkg/controller.
Il kube-scheduler
Il kube-scheduler programma i tuoi pod appena creati in nodi con spazio sufficiente per soddisfare le esigenze di risorse dei pod. Fondamentalmente ascolta kube-apiserver e kube-controller-manager per i pod appena creati che vengono inseriti in una coda e quindi programmati su un nodo disponibile dallo scheduler. La definizione di kube-scheduler può essere trovata qui:https://github.com/kubernetes/kubernetes/blob/master/pkg/scheduler.
Oltre alle risorse di calcolo, kube-scheduler legge anche le regole di affinità e anti-affinità dei nodi per scoprire se un nodo può o non può eseguire quel pod.
Il database etcd
Il database etcd è un archivio chiave-valore molto affidabile e coerente utilizzato per archiviare lo stato del cluster Kubernetes. Contiene lo stato corrente dei pod in cui è in esecuzione il nodo, quanti nodi ha attualmente il cluster, qual è lo stato di tali nodi, quante repliche della distribuzione sono in esecuzione, i nomi dei servizi e altro.
Come accennato in precedenza, solo kube-apiserver comunica con il database etcd. Se il kube-controller-manager deve controllare lo stato del cluster, passerà attraverso il server API per ottenere lo stato dal database etcd, invece di interrogare direttamente l'archivio etcd. Lo stesso accade con kube-scheduler se lo scheduler ha bisogno di far sapere che un pod è stato arrestato o allocato a un altro nodo; informerà il server API e il server API memorizzerà lo stato corrente nel database etcd.
Con etcd, abbiamo coperto tutti i componenti principali per i nostri nodi master Kubernetes in modo da essere pronti per gestire il nostro cluster. Ma un cluster non è composto solo da maestri; abbiamo ancora bisogno dei nodi che eseguiranno il lavoro pesante eseguendo le nostre applicazioni.
Nodi di lavoro Kubernetes
I nodi di lavoro che eseguono questa attività in Kubernetes sono semplicemente chiamati nodi. In precedenza, intorno al 2014, erano chiamati servitori, ma in seguito questo termine è stato sostituito con semplici nodi, poiché il nome confondeva con le terminologie di Salt e faceva pensare che Salt avesse un ruolo importante in Kubernetes.
Questi nodi sono l'unico posto in cui eseguirai i carichi di lavoro, poiché non è consigliabile avere container o carichi sui nodi master, poiché devono essere disponibili per gestire l'intero cluster. I nodi sono molto semplici in termini di componenti; richiedono solo tre servizi per svolgere il loro compito:
- Kubelet
- Proxy Kube
- Tempo di esecuzione del contenitore
Esaminiamo queste tre componenti in modo un po' più approfondito.
Il kubelet
Il kubelet è un componente Kubernetes di basso livello e uno dei più importanti dopo il kube-apiserver; entrambi questi componenti sono essenziali per il provisioning di pod/contenitori nel cluster. Il kubelet è un servizio che viene eseguito sui nodi Kubernetes e ascolta il server API per la creazione del pod. Il kubelet ha il solo compito di avviare/arrestare e assicurarsi che i contenitori nelle cialde siano sani; il kubelet non sarà in grado di gestire i contenitori che non sono stati creati da esso.
Il kubelet raggiunge gli obiettivi parlando con il runtime del contenitore tramite interfaccia di runtime del contenitore (CRI) . Il CRI fornisce la possibilità di collegamento al kubelet tramite un client gRPC, che è in grado di comunicare con diversi runtime di container. Come accennato in precedenza, Kubernetes supporta più runtime di container per distribuire i container, ed è così che ottiene un supporto così diversificato per motori diversi.
Puoi controllare il codice sorgente di kubelet tramite https://github.com/kubernetes/kubernetes/tree/master/pkg/kubelet.
Il kube-proxy
Il kube-proxy è un servizio che risiede su ciascun nodo del cluster ed è quello che rende possibili le comunicazioni tra pod, container e nodi. Questo servizio controlla kube-apiserver per le modifiche sui servizi definiti (il servizio è una sorta di bilanciamento del carico logico in Kubernetes; approfondiremo i servizi più avanti in questo articolo) e mantiene la rete aggiornata tramite regole iptables che inoltrano il traffico a gli estremi corretti. Kube-proxy imposta anche regole in iptables che eseguono il bilanciamento del carico casuale tra i pod dietro un servizio.
Ecco un esempio di una regola iptables creata da kube-proxy:
-A KUBE-SERVICES -d 10.0.162.61/32 -p tcp -m comment --comment "default/example:non ha endpoint" -m tcp --dport 80 -j REJECT --reject-with icmp-port-unreachable
Nota che questo è un servizio senza endpoint (nessun pod dietro di esso).
Runtime del contenitore
Per poter avviare i container, abbiamo bisogno di un runtime del container . Questo è il motore di base che creerà i contenitori nel kernel dei nodi per l'esecuzione dei nostri pod. Il kubelet parlerà con questo runtime e avvierà o arresterà i nostri container su richiesta.
Attualmente, Kubernetes supporta qualsiasi runtime di container conforme a OCI, come Docker, rkt, runc, runsc e così via.
Puoi fare riferimento a questo https://github.com/opencontainers/runtime-spec per saperne di più su tutte le specifiche dalla pagina OCI Git-Hub.
Ora che abbiamo esplorato tutti i componenti principali che formano un cluster, diamo ora un'occhiata a cosa si può fare con essi e in che modo Kubernetes ci aiuterà a orchestrare e gestire le nostre applicazioni containerizzate.
Oggetti Kubernetes
Gli oggetti Kubernetes sono esattamente questo:sono oggetti logici persistenti o astrazioni che rappresenteranno lo stato del tuo cluster. Sei tu il responsabile di dire a Kubernetes qual è lo stato desiderato di quell'oggetto in modo che possa funzionare per mantenerlo e assicurarsi che l'oggetto esista.
Per creare un oggetto, ci sono due cose che deve avere:uno stato e le sue specifiche. Lo stato è fornito da Kubernetes ed è lo stato corrente dell'oggetto. Kubernetes gestirà e aggiornerà tale stato in base alle esigenze per essere conforme allo stato desiderato. Il campo delle specifiche, d'altra parte, è ciò che fornisci a Kubernetes ed è ciò che gli dici per descrivere l'oggetto che desideri. Ad esempio, l'immagine che vuoi che il contenitore esegua, il numero di contenitori di quell'immagine che vuoi eseguire e così via.
Ogni oggetto ha campi specifici per il tipo di attività che esegue e fornirai queste specifiche su un file YAML che viene inviato a kube-apiserver con kubectl, che lo trasforma in JSON e lo invia come richiesta API . Approfondiremo ogni oggetto e i relativi campi delle specifiche più avanti in questo articolo.
Ecco un esempio di YAML inviato a kubectl:
gatto <
I campi di base della definizione dell'oggetto sono i primissimi, e questi non variano da oggetto a oggetto e sono molto autoesplicativi. Diamo una rapida occhiata a loro:
Quindi, ora abbiamo esaminato i campi più utilizzati e il loro contenuto; puoi saperne di più sulle convenzioni API Kuberntes su https://github.com/kubernetes/community/blob/master/contributors/devel/api-conventions.md
Alcuni dei campi dell'oggetto possono essere modificati successivamente dopo la creazione dell'oggetto, ma ciò dipenderà dall'oggetto e dal campo che si desidera modificare.
Quello che segue è un breve elenco dei vari oggetti Kubernetes che puoi creare:
E ce ne sono molti altri.
Diamo un'occhiata più da vicino a ciascuno di questi elementi.
I pod sono gli oggetti più basilari di Kubernetes e anche i più importanti. Tutto ruota intorno a loro; possiamo dire che Kubernetes è per i baccelli! Tutti gli altri oggetti sono qui per servirli, e tutti i compiti che svolgono servono per far sì che i pod raggiungano lo stato desiderato.
Allora, cos'è un pod e perché i pod sono così importanti?
Un pod è un oggetto logico che esegue uno o più contenitori insieme sullo stesso spazio dei nomi di rete, la stessa comunicazione interprocesso (IPC) e, a volte, a seconda della versione di Kubernetes, lo stesso ID processo (PID) spazio dei nomi. Questo perché sono quelli che gestiranno i nostri container e quindi saranno al centro dell'attenzione. Il punto centrale di Kubernetes è essere un orchestratore di contenitori e, con i pod, rendiamo possibile l'orchestrazione.
Come accennato in precedenza, i contenitori sullo stesso pod vivono in una "bolla" in cui possono parlare tra loro tramite localhost, poiché sono locali tra loro. Un contenitore in un pod ha lo stesso indirizzo IP dell'altro contenitore perché condivide uno spazio dei nomi di rete, ma nella maggior parte dei casi verrà eseguito su base individuale, ovvero un singolo contenitore per pod . Contenitori multipli per pod vengono utilizzati solo in scenari molto specifici, ad esempio quando un'applicazione richiede un helper come un pusher di dati o un proxy che deve comunicare in modo rapido e resiliente con l'applicazione principale.
Il modo in cui definisci un pod è lo stesso in cui lo faresti per qualsiasi altro oggetto Kubernetes:tramite un YAML che contiene tutte le specifiche e le definizioni del pod:
tipo:PodapiVersion:v1metadata:name:hello-podlabels: hello:podspec: containers: - name:hello-container image:alpine args: - echo - "Hello World"
Esaminiamo le definizioni di base del pod necessarie nel campo delle specifiche per creare il nostro pod:
Queste sono le specifiche di base che dichiarerai su un pod; altre specifiche richiedono un po' più di conoscenza di base su come usarle e su come interagiscono con vari altri oggetti Kubernetes. Li rivisiteremo più avanti in questo articolo; alcuni di essi sono i seguenti:
Per visualizzare i pod attualmente in esecuzione nel tuo cluster, puoi eseguire kubectl get pods:
[email protected]:~$ kubectl get podsNAME READY STATUS RIAVVIA AGEbusybox 1/1 In esecuzione 120 5d
In alternativa, puoi eseguire kubectl describe pods senza specificare alcun pod. Questo stamperà una descrizione di ogni pod in esecuzione nel cluster. In questo caso, sarà solo il pod occupato, poiché è l'unico attualmente in esecuzione:
[E-mail Protected]:~ $ kubectl Descrivi PodsName:BusyboxNamespace:DefaultPriority:0PriorityClassName:
I baccelli sono mortali. Una volta che muore o viene eliminato, non possono essere recuperati. Il suo IP e i container che erano in esecuzione su di esso spariranno; sono totalmente effimeri. I dati sui pod montati come volume possono sopravvivere o meno, a seconda della configurazione. Se i nostri pod muoiono e li perdiamo, come possiamo assicurarci che tutti i nostri microservizi siano in esecuzione? Bene, le implementazioni sono la risposta.
I pod da soli non sono molto utili poiché non è molto efficiente avere più di una singola istanza della nostra applicazione in esecuzione in un singolo pod. Fornire centinaia di copie della nostra applicazione su pod diversi senza avere un metodo per cercarle tutte sfuggirà di mano molto rapidamente.
È qui che entrano in gioco le distribuzioni. Con le implementazioni, possiamo gestire i nostri pod con un controller. Questo ci consente non solo di decidere quanti vogliamo eseguire, ma possiamo anche gestire gli aggiornamenti modificando la versione dell'immagine o l'immagine stessa che i nostri contenitori stanno eseguendo. Le distribuzioni sono ciò con cui lavorerai per la maggior parte del tempo. Con le distribuzioni, i pod e qualsiasi altro oggetto menzionato prima, hanno la propria definizione all'interno di un file YAML:
apiVersion:apps/v1kind:Deploymentmetadata:name:nginx-deployment labels: deployment:nginxspec:repliche:3 selector: matchLabels: app:nginx template: metadata: label: app:nginx spec: containers: - name:nginx x: image:ngin 1.7.9 porte: - containerPort:80
Iniziamo ad esplorare la loro definizione.
All'inizio di YAML, abbiamo campi più generali, come apiVersion, kind e metadata. Ma sotto le specifiche è dove troveremo le opzioni specifiche per questo oggetto API.
Sotto le specifiche, possiamo aggiungere i seguenti campi:
Selettore :con il campo Selettore, la distribuzione saprà quali pod scegliere come target quando vengono applicate le modifiche. Ci sono due campi che utilizzerai sotto il selettore: matchLabels e matchExpressions. Con matchLabels, il selettore utilizzerà le etichette dei pod (coppie chiave/valore). È importante notare che tutte le etichette che specifichi qui verranno contrassegnate con AND. Ciò significa che il pod richiederà che disponga di tutte le etichette specificate in matchLabels.
Repliche :indicherà il numero di pod necessari alla distribuzione per continuare a funzionare tramite il controller di replica; ad esempio, se si specificano tre repliche e uno dei pod muore, il controller di replica osserverà le specifiche delle repliche come lo stato desiderato e informerà lo scheduler di pianificare un nuovo pod, poiché lo stato corrente è ora 2 poiché il pod è morto.
RevisionHistoryLimit :ogni volta che apporti una modifica alla distribuzione, questa modifica viene salvata come revisione della distribuzione, che puoi ripristinare in seguito allo stato precedente o tenere un registro di ciò che è stato modificato. Puoi consultare la tua cronologia con kubectl distribuzione della cronologia di implementazione/
Strategia :questo ti consentirà di decidere come gestire qualsiasi aggiornamento o scala orizzontale del pod. Per sovrascrivere l'impostazione predefinita, che è rollingUpdate, devi scrivere la chiave di tipo, in cui puoi scegliere tra due valori: recreate o rollingUpdate.
Sebbene ricreare sia un modo rapido per aggiornare la tua distribuzione, eliminerà tutti i pod e li sostituirà con nuovi, ma implica che dovrai tenere in considerazione che sarà in atto un tempo di inattività del sistema per questo tipo di strategia. RollingUpdate, d'altra parte, è più fluido e lento ed è l'ideale per le applicazioni con stato che possono ribilanciare i propri dati. Il rollingUpdate apre la porta ad altri due campi, che sono maxSurge e maxUnavailable.
Il primo sarà il numero di pod sopra l'importo totale che desideri durante l'esecuzione di un aggiornamento; ad esempio, una distribuzione con 100 pod e un 20% maxSurge aumenterà fino a un massimo di 120 pod durante l'aggiornamento. L'opzione successiva ti consentirà di selezionare quanti pod nella percentuale sei disposto a uccidere per sostituirli con quelli nuovi in uno scenario da 100 pod. Nei casi in cui c'è il 20% di maxNon disponibile, solo 20 pod verranno eliminati e sostituiti con nuovi prima di continuare a sostituire il resto della distribuzione.
Modello :questo è solo un campo di specifiche pod nidificato in cui includerai tutte le specifiche e i metadati dei pod che la distribuzione gestirà.
Abbiamo visto che, con le implementazioni, gestiamo i nostri pod e ci aiutano a mantenerli nello stato che desideriamo. Tutti questi pod sono ancora in qualcosa chiamato il cluster rete , che è una rete chiusa in cui solo i componenti del cluster Kubernetes possono comunicare tra loro, anche con il proprio set di intervalli IP. Come parliamo con i nostri baccelli dall'esterno? Come raggiungiamo la nostra applicazione? È qui che entrano in gioco i servizi.
Servizi :
Il nome servizio non descrive completamente cosa fanno effettivamente i servizi in Kubernetes. I servizi Kubernetes sono ciò che indirizza il traffico ai nostri pod. Possiamo dire che i servizi sono ciò che lega insieme i pod.
Immaginiamo di avere un tipico tipo di applicazione frontend/backend in cui i nostri pod frontend parlano con i nostri backend tramite gli indirizzi IP dei pod. Se un pod nel back-end muore, perdiamo la comunicazione con il nostro back-end. Questo non solo perché il nuovo pod non avrà lo stesso indirizzo IP del pod che è morto, ma ora dobbiamo anche riconfigurare la nostra app per utilizzare il nuovo indirizzo IP. Questo problema e problemi simili vengono risolti con i servizi.
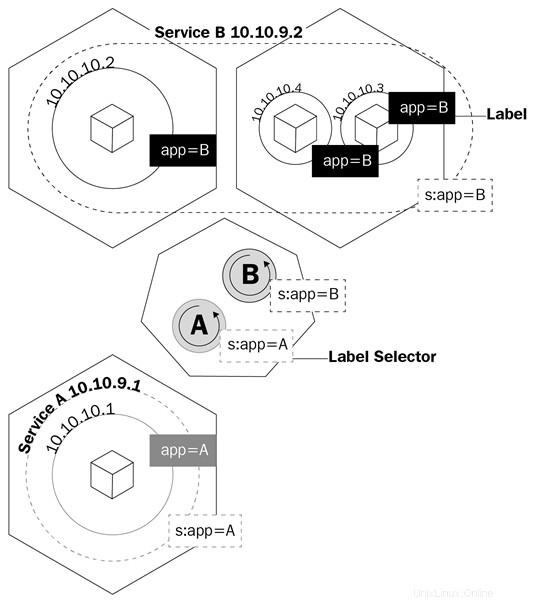
Un servizio è un oggetto logico che indica a kube-proxy di creare regole iptables in base a quali pod si trovano dietro il servizio. I servizi configurano i propri endpoint, ovvero come vengono chiamati i pod dietro un servizio, allo stesso modo in cui le distribuzioni sanno quali pod controllare, il campo del selettore e le etichette dei pod.
Questo diagramma mostra come i servizi utilizzano le etichette per gestire il traffico:
I servizi non solo renderanno kube-proxy creare regole per instradare il traffico; attiverà anche qualcosa chiamato kube-dns.
Kube-dns è un insieme di pod con contenitori SkyDNS che vengono eseguiti sul cluster che fornisce un server DNS e un forwarder, che creerà record per i servizi e talvolta pod per facilità d'uso. Ogni volta che crei un servizio, verrà creato un record DNS che punta all'indirizzo IP del cluster interno del servizio con il modulo service-name.namespace.svc.cluster.local. Puoi saperne di più sulle specifiche DNS di Kubernetes qui: https://github.com/kubernetes/dns/blob/master/docs/specification.md.
Tornando al nostro esempio, ora dovremo solo configurare la nostra applicazione per parlare con il servizio nome di dominio completo (FQDN) per parlare con i nostri pod di backend. In questo modo, non importa quale indirizzo IP hanno i pod e i servizi. Se un pod dietro il servizio muore, il servizio si occuperà di tutto utilizzando il record A, poiché saremo in grado di dire al nostro frontend di instradare tutto il traffico a my-svc. La logica del servizio penserà a tutto il resto.
Esistono diversi tipi di servizio che puoi creare ogni volta che dichiari l'oggetto da creare in Kubernetes. Esaminiamoli per vedere quale sarà più adatto al tipo di lavoro di cui abbiamo bisogno:
IP del cluster :Questo è il servizio predefinito. Ogni volta che crei un servizio ClusterIP, verrà creato un servizio con un indirizzo IP interno al cluster che sarà instradabile solo all'interno del cluster Kubernetes. Questo tipo è ideale per i pod che devono solo parlare tra loro e non uscire dal cluster.
NodePort :quando crei questo tipo di servizio, per impostazione predefinita verrà allocata una porta casuale da 30000 a 32767 per inoltrare il traffico ai pod endpoint del servizio. Puoi ignorare questo comportamento specificando una porta del nodo nell'array delle porte. Una volta definito, sarai in grado di accedere ai tuoi pod tramite
Bilanciamento del carico :Nella maggior parte dei casi, eseguirai Kubernetes su un provider cloud. Il tipo LoadBalancer è l'ideale per queste situazioni, poiché sarai in grado di allocare indirizzi IP pubblici al tuo servizio tramite l'API del tuo provider di servizi cloud. Questo è il servizio ideale per quando vuoi comunicare con i tuoi pod dall'esterno del tuo cluster. Con LoadBalancer, sarai in grado non solo di allocare un indirizzo IP pubblico ma anche, usando Azure, di allocare un indirizzo IP privato dalla tua rete privata virtuale. Quindi, puoi parlare con i tuoi pod da Internet o internamente sulla tua sottorete privata.
Esaminiamo la definizione di servizio di YAML:
apiVersion:v1kind:Servicemetadata: name:my-servicespec:selector: app:front-end type:NodePort ports: - name:http port:80 targetPort:8080 nodePort:30024 protocol:TCP
YAML di un servizio è molto semplice e le specifiche variano a seconda del tipo di servizio che stai creando. Ma la cosa più importante da tenere in considerazione sono le definizioni delle porte. Diamo un'occhiata a questi:
Sebbene ora comprendiamo come possiamo comunicare con i pod nel nostro cluster, dobbiamo comunque capire come gestiremo il problema della perdita dei nostri dati ogni volta che un pod viene chiuso. Qui è dove Persistente Volumi (PV ) viene utilizzato.
Lo stoccaggio persistente nel mondo dei container è un problema serio. L'unico spazio di archiviazione persistente tra le esecuzioni del contenitore sono i livelli dell'immagine e sono di sola lettura. Il livello in cui viene eseguito il contenitore è di lettura/scrittura, ma tutti i dati in questo livello vengono eliminati una volta interrotto il contenitore. Con i pod, questo è lo stesso. Quando un contenitore muore, i dati scritti su di esso spariscono.
Kubernetes ha una serie di oggetti per gestire l'archiviazione tra i pod. Il primo di cui parleremo sono i volumi.
I volumi risolvono uno dei problemi più grandi quando si tratta di archiviazione persistente. Prima di tutto, i volumi non sono in realtà oggetti, ma una definizione delle specifiche di un pod. Quando crei un pod, puoi definire un volume nel campo delle specifiche del pod. I contenitori in questo pod potranno montare il volume nel loro spazio dei nomi di montaggio e il volume sarà disponibile in caso di riavvio o arresto anomalo del contenitore. Tuttavia, i volumi sono legati ai pod e, se il pod viene eliminato, anche il volume scomparirà. I dati sul volume sono un'altra storia; la persistenza dei dati dipenderà dal back-end di quel volume.
Kubernetes supporta diversi tipi di volumi o origini volumetriche e il modo in cui vengono chiamati nelle specifiche API, che vanno dalle mappe del filesystem del nodo locale, ai dischi virtuali dei provider di servizi cloud e ai volumi supportati dallo storage software-defined. I mount locali del filesystem sono i più comuni che vedrai quando si tratta di volumi regolari. È importante notare che lo svantaggio dell'utilizzo del file system del nodo locale è che i dati non saranno disponibili su tutti i nodi del cluster e solo su quel nodo in cui è stato pianificato il pod.
Esaminiamo come viene definito un pod con un volume in YAML:
apiVersion:v1kind:Podmetadata:nome:test-pdspec:contenitori:- immagine:k8s.gcr.io/test-webserver nome:test-container volumeMounts: - mountPath:/test-pd nome:volume di test volumi:- nome:volume-test hostPath: percorso:/data tipo:Directory
Nota come c'è un campo chiamato volumi sotto le specifiche e poi ce n'è un altro chiamato VolumeMounts.
Il primo campo (volumi) è dove si definisce il volume che si desidera creare per quel pod. Questo campo richiederà sempre un nome e quindi un'origine del volume. A seconda della fonte, i requisiti saranno diversi. In questo esempio, l'origine sarebbe hostPath, che è il filesystem locale di un nodo. hostPath supporta diversi tipi di mappature, che vanno da directory, file, dispositivi a blocchi e persino socket Unix.
Sotto il secondo campo, volumeMounts, abbiamo mountPath, che è dove definisci il percorso all'interno del container in cui vuoi montare il tuo volume. Il parametro name è il modo in cui specifichi nel pod quale volume utilizzare. Questo è importante perché puoi avere diversi tipi di volumi definiti in volumi e il nome sarà l'unico modo per il pod di sapere quale
Puoi saperne di più sui diversi tipi di volumi qui https://kubernetes.io/docs/concepts/storage/volumes/#types-of-volumes e nel documento di riferimento dell'API Kubernetes (https://kubernetes.io/docs /reference/generated/kubernetes-api/v1.11/#volume-v1-core).
Far morire i volumi con i baccelli non è l'ideale. Abbiamo bisogno di uno storage che persista, ed è così che è nata la necessità di PV.
La principale differenza tra volumi e PV è che, a differenza dei volumi, i PV sono in realtà oggetti API Kubernetes, quindi puoi gestirli individualmente come entità separate e quindi persistono anche dopo l'eliminazione di un pod.
Ti starai chiedendo perché questa sottosezione ha PV, persistente volume reclami (PVC ) e classi di archiviazione, tutte mescolate. Questo perché dipendono tutte l'una dall'altra ed è fondamentale capire come interagiscono tra loro per effettuare il provisioning dello spazio di archiviazione per i nostri pod.
Let's begin with PVs and PVCs. Like volumes, PVs have a storage source, so the same mechanism that volumes have applies here. You will either have a software-defined storage cluster providing a logical unit number (LUN ), a cloud provider giving virtual disks, or even a local filesystem to the Kubernetes node, but here, instead of being called volume sources, they are called persistent volume types instead.
PVs are pretty much like LUNs in a storage array:you create them, but without a mapping; they are just a bunch of allocated storage waiting to be used. PVCs are like LUN mappings:they are backed or bound to a PV and also are what you actually define, relate, and make available to the pod that it can then use for its containers.
The way you use PVCs on pods is exactly the same as with normal volumes. You have two fields:one to specify which PVC you want to use, and the other one to tell the pod on which container to use that PVC.
The YAML for a PVC API object definition should have the following code:
apiVersion:v1kind:PersistentVolumeClaimmetadata:name:gluster-pvc spec:accessModes:- ReadWriteMany resources: requests: storage:1Gi
The YAML for pod should have the following code:
kind:PodapiVersion:v1metadata:name:mypodspec:containers: - name:myfrontend image:nginx volumeMounts: - mountPath:"/mnt/gluster" name:volume volumes: - name:volume persistentVolumeClaim: claimName:gluster-pvc
When a Kubernetes administrator creates PVC, there are two ways that this request is satisfied:
Storage classes are like a way of tiering your storage. You can create a class that provisions slow storage volumes, or another one with hyper-fast SSD drives. However, storage classes are a little bit more complex than just tiering. As we mentioned in the two ways of creating PVC, storage classes are what make dynamic provisioning possible. When working on a cloud environment, you don't want to be manually creating every backend disk for every PV. Storage classes will set up something called a provisioner , which invokes the volume plug-in that's necessary to talk to your cloud provider's API. Every provisioner has its own settings so that it can talk to the specified cloud provider or storage provider.
You can provision storage classes in the following way; this is an example of a storage class using Azure-disk as a disk provisioner:
kind:StorageClassapiVersion:storage.k8s.io/v1metadata:name:my-storage-classprovisioner:kubernetes.io/azure-diskparameters:storageaccounttype:Standard_LRS kind:Shared
Each storage class provisioner and PV type will have different requirements and parameters, as well as volumes, and we have already had a general overview of how they work and what we can use them for. Learning about specific storage classes and PV types will depend on your environment; you can learn more about each one of them by clicking on the following links:
In this article, we learned about what Kubernetes is, its components, and what are the advantages of using orchestration are. With this, identifying each of Kubernetes API objects, their purpose and their use cases should be easy. You should now be able to understand how the master nodes control the cluster and the scheduling of the containers in the worker nodes.
If you found this article useful, ‘ Hands-On Linux for Architects ’ should be helpful for you. With this book, you will be covering everything from Linux components and functionalities to hardware and software support, which will help you implementing and tuning effective Linux-based solutions. You will be taken through an overview of Linux design methodology and core concepts of designing a solution. If you’re a Linux system administrator, Linux support engineer, DevOps engineer, Linux consultant or anyone looking to learn or expand their knowledge in architecting, this book is for you.
Pods:la base di Kubernetes
Distribuzioni
Kubernetes e archiviazione persistente
Volumi
Volumi persistenti, attestazioni di volume persistenti e classi di archiviazione