L'analisi forense di un'immagine disco di Linux fa spesso parte della risposta agli incidenti per determinare se si è verificata una violazione. La scientifica di Linux è un mondo diverso e affascinante rispetto alla scientifica di Microsoft Windows. In questo articolo, analizzerò un'immagine disco da un sistema Linux potenzialmente compromesso per determinare chi, cosa, quando, dove, perché e come dell'incidente e creare sequenze temporali di eventi e filesystem. Infine, estrarrò gli artefatti di interesse dall'immagine del disco.
In questo tutorial, utilizzeremo alcuni nuovi strumenti e alcuni vecchi strumenti in modi nuovi e creativi per eseguire un'analisi forense di un'immagine disco.
Lo scenario
Più risorse Linux
- Comandi Linux cheat sheet
- Cheat sheet sui comandi avanzati di Linux
- Corso online gratuito:Panoramica tecnica RHEL
- Cheat sheet della rete Linux
- Cheat sheet di SELinux
- Cheat sheet dei comandi comuni di Linux
- Cosa sono i container Linux?
- I nostri ultimi articoli su Linux
Premiere Fabrication Engineering (PFE) sospetta che si sia verificato un incidente o una compromissione che ha coinvolto il server principale dell'azienda denominato pfe1. Ritengono che il server potrebbe essere stato coinvolto in un incidente e potrebbe essere stato compromesso tra il primo marzo e l'ultimo marzo. Hanno ingaggiato i miei servizi come esaminatore forense per indagare se il server è stato compromesso e coinvolto in un incidente. L'indagine determinerà chi, cosa, quando, dove, perché e come dietro il possibile compromesso. Inoltre, PFE ha richiesto i miei consigli per ulteriori misure di sicurezza per i propri server.
L'immagine del disco
Per condurre l'analisi forense del server, chiedo a PFE di inviarmi un'immagine forense del disco di pfe1 su un'unità USB. Sono d'accordo e dicono "l'USB è nella posta". La chiavetta USB arriva e inizio ad esaminarne il contenuto. Per condurre l'analisi forense, utilizzo una macchina virtuale (VM) che esegue la distribuzione SANS SIFT. SIFT Workstation è un gruppo di strumenti forensi e di risposta agli incidenti gratuiti e open source progettati per eseguire esami forensi digitali dettagliati in una varietà di impostazioni. SIFT ha una vasta gamma di strumenti forensi e, se non ha uno strumento che desidero, posso installarne uno senza troppe difficoltà poiché è una distribuzione basata su Ubuntu.
Dopo l'esame, trovo che l'USB non contenga un'immagine disco, piuttosto copie dei file host VMware ESX, che sono file VMDK dal cloud ibrido di PFE. Questo non era quello che mi aspettavo. Ho diverse opzioni:
- Posso contattare PFE ed essere più esplicito su cosa mi aspetto da loro. All'inizio di un fidanzamento come questo, potrebbe non essere la cosa migliore da fare.
- Posso caricare i file VMDK in uno strumento di virtualizzazione come VMPlayer ed eseguirlo come una VM live utilizzando i suoi programmi Linux nativi per eseguire analisi forensi. Ci sono almeno tre ragioni per non farlo. Innanzitutto, i timestamp sui file e sui contenuti dei file verranno modificati durante l'esecuzione dei file VMDK come sistema live. In secondo luogo, poiché si ritiene che il server sia compromesso, ogni file e programma dei filesystem VMDK deve essere considerato compromesso. Terzo, l'utilizzo dei programmi nativi su un sistema compromesso per eseguire un'analisi forense può avere conseguenze impreviste.
- Per analizzare i file VMDK, potrei usare il pacchetto libvmdk-utils che contiene gli strumenti per accedere ai dati archiviati nei file VMDK.
- Tuttavia, un approccio migliore consiste nel convertire il formato file VMDK in formato RAW. Ciò renderà più semplice eseguire i diversi strumenti nella distribuzione SIFT sui file nell'immagine del disco.
Per convertire dal formato VMDK al formato RAW, utilizzo l'utilità qemu-img, che consente di creare, convertire e modificare immagini offline. La figura seguente mostra il comando per convertire il formato VMDK in un formato RAW.

Successivamente, è necessario elencare la tabella delle partizioni dall'immagine del disco e ottenere informazioni su dove inizia ciascuna partizione (settori) utilizzando l'utilità mmls. Questa utilità visualizza il layout delle partizioni in un sistema di volumi, comprese le tabelle delle partizioni e le etichette dei dischi. Quindi utilizzo il settore iniziale e interrogo i dettagli associati al filesystem utilizzando l'utilità fsstat, che visualizza i dettagli associati a un filesystem. Le figure seguenti mostrano i mmls e fsstat comandi in funzione.
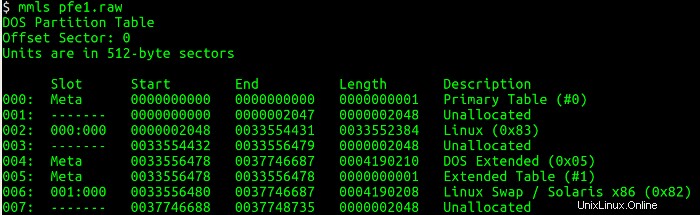
Ho imparato molte cose interessanti da mmls output:una partizione primaria Linux inizia al settore 2048 e ha una dimensione di circa 8 gigabyte. Una partizione DOS, probabilmente la partizione di avvio, ha una dimensione di circa 8 megabyte. Infine, c'è una partizione di swap di circa 8 gigabyte.
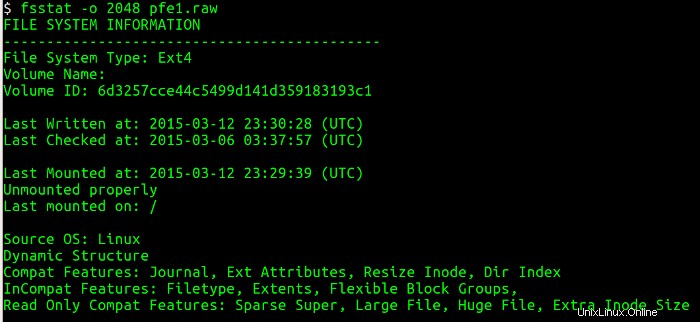
Esecuzione di fsstat mi dice molte cose utili sulla partizione:il tipo di filesystem, l'ultima volta che i dati sono stati scritti nel filesystem, se il filesystem è stato smontato in modo pulito e dove è stato montato.
Sono pronto per montare la partizione e avviare l'analisi. Per fare ciò, è necessario leggere le tabelle delle partizioni sull'immagine grezza specificata e creare mappe dei dispositivi sui segmenti di partizione rilevati. Potrei farlo a mano con le informazioni da mmls e fsstat —oppure potrei usare kpartx per farlo per me.

Uso le opzioni per creare mappature di sola lettura (-r ), aggiungi la mappatura delle partizioni (-a ) e fornire un output dettagliato (-v ). Il loop0p1 è il nome di un file del dispositivo in /dev/mapper Posso usare per accedere alla partizione. Per montarlo, eseguo:
$ mount -o ro -o loop=/dev/mapper/loop0p1 pf1.raw /mnt
Nota che sto montando la partizione come di sola lettura (-o ro ) per prevenire la contaminazione accidentale.
Dopo aver montato il disco, inizio la mia analisi e indagine forense creando una sequenza temporale. Alcuni esaminatori forensi non credono nella creazione di una sequenza temporale. Invece, una volta che hanno una partizione montata, si insinuano nel filesystem alla ricerca di artefatti che potrebbero essere rilevanti per l'indagine. Definisco questi esaminatori forensi "creepers". Sebbene questo sia un modo per indagare in modo forense, è tutt'altro che ripetibile, è soggetto a errori e potrebbe perdere prove preziose.
Credo che la creazione di una sequenza temporale sia un passaggio cruciale perché include informazioni utili sui file che sono stati modificati, consultati, modificati e creati in un formato leggibile dall'uomo, noto come prove temporali MAC (modificato, accessibile, modificato). Questa attività aiuta a identificare l'ora specifica e a ordinare che si è verificato un evento.
Note sui filesystem Linux
I filesystem Linux come ext2 ed ext3 non hanno timestamp per la creazione/ora di nascita di un file. Il timestamp di creazione è stato introdotto in ext4. Il libroScoperta forense (1a edizione) di Dan Farmer e Wietse Venema delinea i diversi timestamp.
- Ultima modifica: Per le directory, questa è l'ultima volta che una voce è stata aggiunta, rinominata o rimossa. Per altri tipi di file, è l'ultima volta che il file è stato scritto.
- Ora dell'ultimo accesso (lettura): Per le directory, questa è l'ultima volta che è stata cercata. Per altri tipi di file, è l'ultima volta che il file è stato letto.
- Ultima modifica di stato: Esempi di modifiche allo stato sono la modifica del proprietario, la modifica dell'autorizzazione di accesso, la modifica del conteggio dei collegamenti fisici o una modifica esplicita di uno qualsiasi degli orari MAC.
- Tempo di eliminazione: ext2 ed ext3 registrano l'ora in cui un file è stato eliminato in
dtimetimestamp, ma non tutti gli strumenti lo supportano. - Tempo di creazione: ext4fs registra l'ora in cui il file è stato creato nel
crtimetimestamp, ma non tutti gli strumenti lo supportano.
I diversi timestamp sono memorizzati nei metadati contenuti negli inode. Gli inode sono simili al numero di ingresso MFT nel mondo Windows. Un modo per leggere i metadati del file su un sistema Linux è ottenere prima il numero dell'inode usando il comando ls -i file quindi usa istat contro il dispositivo di partizione e specificare il numero di inode. Questo ti mostrerà i diversi attributi dei metadati, inclusi i timestamp, la dimensione del file, il gruppo del proprietario e l'ID utente, le autorizzazioni e i blocchi che contengono i dati effettivi.
Creazione della super sequenza temporale
Il mio prossimo passo è creare una super timeline usando log2timeline/plaso. Plaso è una riscrittura basata su Python dello strumento log2timeline basato su Perl inizialmente creato da Kristinn Gudjonsson e migliorato da altri. È facile creare una sequenza temporale eccellente con log2timeline, ma l'interpretazione è difficile. L'ultima versione del motore plaso può analizzare ext4 oltre a diversi tipi di artefatti, come messaggi syslog, audit, utmp e altri.
Per creare la super timeline, lancio log2timeline sulla cartella del disco montata e utilizzo i parser Linux. Questo processo richiede del tempo; quando finisce ho una timeline con i diversi artefatti in formato database plaso, quindi posso usare psort.py per convertire il database plaso in un numero qualsiasi di formati di output diversi. Per vedere i formati di output che psort.py supporta, inserisci psort -o list . Ho usato psort.py per creare una super timeline in formato Excel. La figura seguente illustra i passaggi per eseguire questa operazione.

(Nota:righe estranee rimosse dalle immagini)

Importo la super sequenza temporale in un programma di fogli di calcolo per semplificare la visualizzazione, l'ordinamento e la ricerca. Sebbene tu possa visualizzare una super sequenza temporale in un foglio di calcolo, è più facile lavorarci in un database reale come MySQL o Elasticsearch. Creo una seconda super timeline e la spedisco direttamente a un'istanza Elasticsearch da psort.py . Una volta che la super timeline è stata indicizzata da Elasticsearch, posso visualizzare e analizzare i dati con Kibana.

Indagine con Elasticsearch/Kibana
Come ha detto il sergente maggiore Farrell:"Attraverso la prontezza e la disciplina, siamo padroni del nostro destino". Durante l'analisi, vale la pena essere pazienti e meticolosi ed evitare di essere un rampicante. Una cosa che aiuta un'analisi della sequenza temporale eccellente è avere un'idea di quando potrebbe essere accaduto l'incidente. In questo caso (gioco di parole), il cliente afferma che l'incidente potrebbe essere accaduto a marzo. Considero ancora la possibilità che il cliente abbia torto sui tempi. Armato di queste informazioni, inizio a ridurre il lasso di tempo della super timeline e a restringerlo. Sto cercando manufatti di interesse che hanno una "prossimità temporale" con la presunta data dell'incidente. L'obiettivo è ricreare ciò che è accaduto sulla base di diversi artefatti.
Per restringere l'ambito della super timeline, utilizzo l'istanza Elasticsearch/Kibana che ho configurato. Con Kibana, posso configurare un numero qualsiasi di dashboard intricati per visualizzare e correlare eventi forensi di interesse, ma voglio evitare questo livello di complessità. Seleziono invece gli indici di interesse da visualizzare e creo un grafico a barre dell'attività per data:
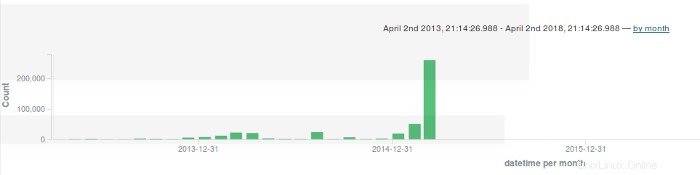
Il passaggio successivo è espandere la barra grande alla fine del grafico:

C'è un grande bar il 05-marzo. Espando quella barra per vedere l'attività in quella data particolare:
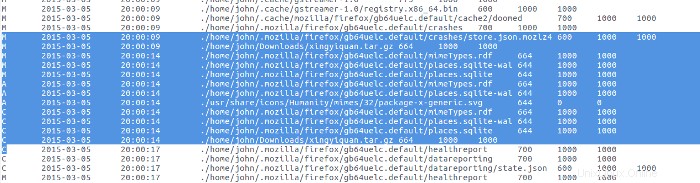
Osservando l'attività del file di registro dalla sequenza temporale super, vedo che questa attività proveniva da un'installazione/aggiornamento del software. C'è molto poco da trovare in quest'area di attività.
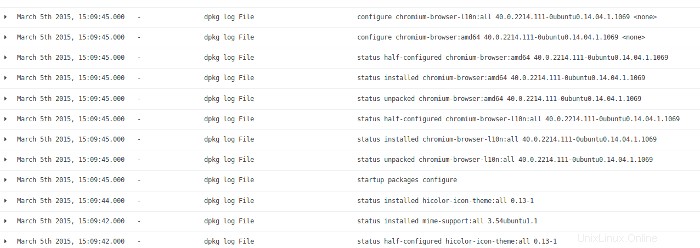
Torno su Kibana per vedere l'ultima serie di attività sul sistema e trovo questo nei log:
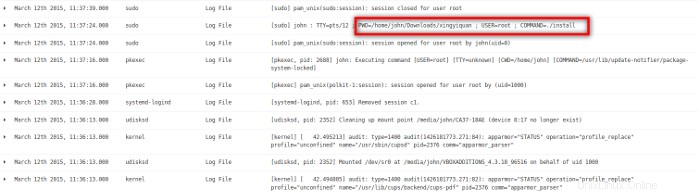
Una delle ultime attività sul sistema è stata che l'utente john ha installato un programma da una directory chiamata xingyiquan. Lo Xing Yi Quan è uno stile di arti marziali cinesi simile al Kung Fu e al Tai Chi Quan. Sembra strano che l'utente john installi un programma di arti marziali su un server aziendale dal proprio account utente. Uso la capacità di ricerca di Kibana per trovare altre istanze di xingyiquan nei file di registro. Ho trovato tre periodi di attività attorno alla stringa xingyiquan il 5 marzo, il 9 marzo e il 12 marzo.

Successivamente, guardo le voci di registro di questi giorni. Inizio con 05-Mar e trovo prove di una ricerca su Internet utilizzando il browser Firefox e il motore di ricerca Google per un rootkit chiamato xingyiquan. La ricerca su Google ha rilevato l'esistenza di un tale rootkit su packetstormsecurity.com. Quindi, il browser è andato su packetstormsecurity.com e ha scaricato un file chiamato xingyiquan.tar.gz da quel sito nella directory di download dell'utente john.
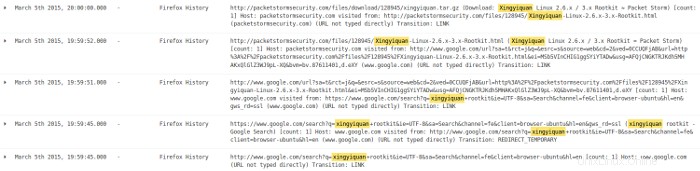
Sebbene sembri che l'utente john sia andato su google.com per cercare il rootkit e poi su packetstormsecurity.com per scaricare il rootkit, queste voci di registro non indicano l'utente dietro la ricerca e il download. Ho bisogno di approfondire questo aspetto.
Il browser Firefox conserva le informazioni sulla cronologia in un database SQLite sotto il .mozilla directory nella home directory di un utente (ad esempio, l'utente john) in un file chiamato places.sqlite . Per visualizzare le informazioni nel database, utilizzo un programma chiamato sqlitebrowser. È un'applicazione GUI che consente a un utente di approfondire un database SQLite e visualizzare i record ivi archiviati. Ho avviato sqlitebrowser e importato places.sqlite dal .mozilla directory nella directory home dell'utente john. I risultati sono mostrati di seguito.

Il numero nella colonna all'estrema destra è il timestamp per l'attività a sinistra. Come test di congruenza, ho convertito il timestamp 1425614413880000 al tempo umano ed è arrivato il 5 marzo 2015 alle 20:00:13.880 PM. Questo corrisponde strettamente all'ora del 5 marzo 2015, 20:00:00.000 da Kibana. Possiamo affermare con ragionevole certezza che l'utente john ha cercato un rootkit chiamato xingyiquan e ha scaricato un file da packetstormsecurity.com chiamato xingyiquan.tar.gz nella directory di download dell'utente john.
Indagine con MySQL
A questo punto, decido di importare la super timeline in un database MySQL per ottenere una maggiore flessibilità nella ricerca e nella manipolazione dei dati rispetto a quella consentita solo da Elasticsearch/Kibana.
Costruzione del rootkit xingyiquan
Carico la super timeline che ho creato dal database plaso in un database MySQL. Dal lavoro con Elasticsearch/Kibana, so che l'utente john ha scaricato il rootkit xingyiquan.tar.gz da packetstormsecurity.com alla directory di download. Ecco la prova dell'attività di download dal database della sequenza temporale di MySQL:
Poco dopo il download del rootkit, il sorgente da tar.gz l'archivio è stato estratto.
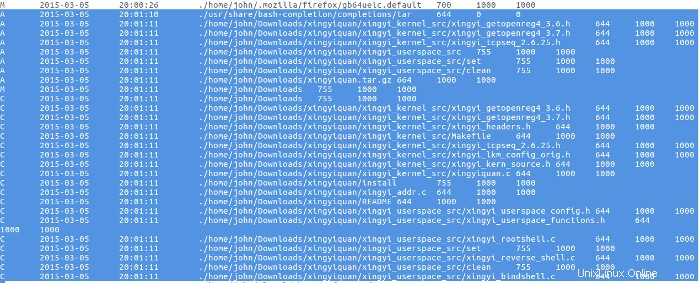
Non è stato fatto nulla con il rootkit fino al 09 marzo, quando il cattivo attore ha letto il file README per il rootkit con il programma More, quindi ha compilato e installato il rootkit.
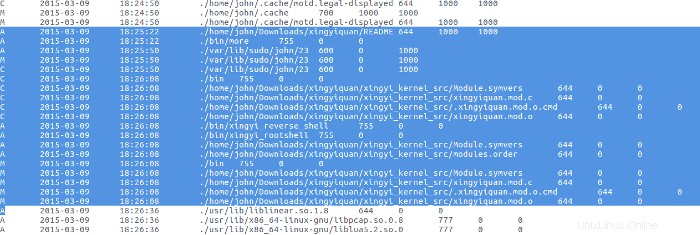
Cronologie dei comandi
Carico le cronologie di tutti gli utenti su pfe1 che hanno bash cronologie dei comandi in una tabella nel database MySQL. Una volta caricate le cronologie, posso visualizzarle facilmente utilizzando una query come:
select * from histories order by recno; Per ottenere una cronologia per un utente specifico, utilizzo una query come:
select historyCommand from histories where historyFilename like '%<username>%' order by recno;
Trovo diversi comandi interessanti da bash dell'utente john storia. Vale a dire, l'utente john ha creato l'account johnn, lo ha eliminato, lo ha creato di nuovo, ha copiato /bin/true a /bin/false , ha fornito le password agli account whoopsie e lightdm, ha copiato /bin/bash a /bin/false , modificato la password e i file di gruppo, spostato la home directory dell'utente johnn da johnn a .johnn , (rendendolo una directory nascosta), ha cambiato il file della password usando sed dopo aver cercato come usare
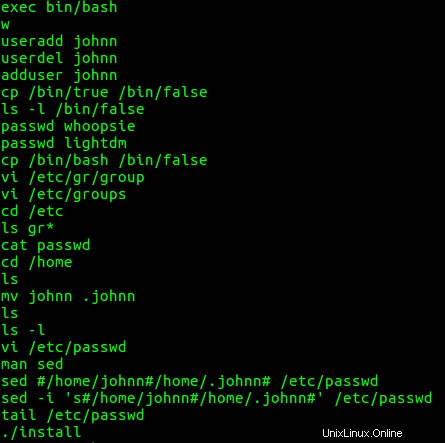
Successivamente, guardo il bash cronologia dei comandi per l'utente johnn. Non ha mostrato attività insolita.
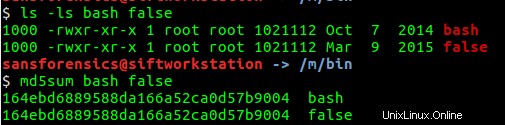
Notando che l'utente john ha copiato /bin/bash a /bin/false , provo se ciò fosse vero controllando le dimensioni di questi file e ottenendo un hash MD5 dei file. Come mostrato di seguito, le dimensioni dei file e gli hash MD5 sono gli stessi. Pertanto, i file sono gli stessi.
Indagine sugli accessi riusciti e non riusciti
Per rispondere a parte della domanda "quando", carico i file di registro contenenti dati su accessi, logout, avviamenti del sistema e arresti in una tabella nel database MySQL. Utilizzando una query semplice come:
select * from logins order by start Trovo la seguente attività:

Da questa figura, vedo che l'utente john ha effettuato l'accesso a pfe1 dall'indirizzo IP 192.168.56.1 . Cinque minuti dopo, l'utente johnn ha effettuato l'accesso a pfe1 dallo stesso indirizzo IP. Due accessi da parte dell'utente lightdm sono seguiti quattro minuti dopo e un altro un minuto dopo, quindi l'utente johnn ha effettuato l'accesso meno di un minuto dopo. Quindi pfe1 è stato riavviato.
Guardando gli accessi non riusciti, trovo questa attività:

Ancora una volta, l'utente lightdm ha tentato di accedere a pfe1 dall'indirizzo IP 192.168.56.1 . Alla luce degli account fasulli che accedono a pfe1, uno dei miei consigli a PFE sarà di controllare il sistema con l'indirizzo IP 192.168.56.1 per la prova del compromesso.
Indagine sui file di registro
Questa analisi degli accessi riusciti e non riusciti fornisce informazioni preziose su quando si sono verificati gli eventi. Rivolgo la mia attenzione all'analisi dei file di registro su pfe1, in particolare l'attività di autenticazione e autorizzazione in /var/log/auth* . Carico tutti i file di registro su pfe1 in una tabella di database MySQL e utilizzo una query come:
select logentry from logs where logfilename like '%auth%' order by recno;
e salvalo in un file. Apro quel file con il mio editor preferito e cerco 192.168.56.1 . Di seguito una sezione dell'attività:
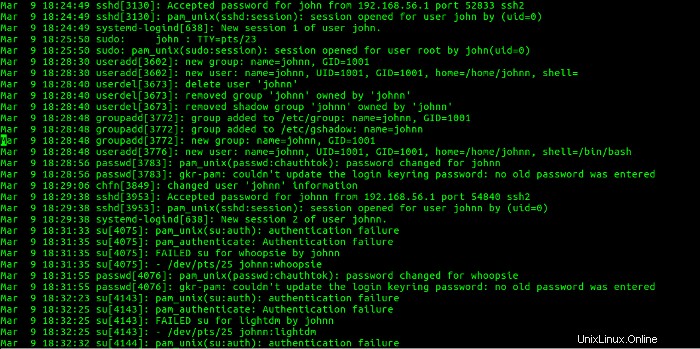
Questa sezione mostra che l'utente john ha effettuato l'accesso dall'indirizzo IP 192.168.56.1 e creato l'account johnn, rimosso l'account johnn e creato di nuovo. Quindi, l'utente johnn ha effettuato l'accesso a pfe1 dall'indirizzo IP 192.168.56.1 . Successivamente, l'utente johnn ha tentato di diventare utente whoopsie con un su comando, che non è riuscito. Quindi, la password per l'utente whoopsie è stata modificata. L'utente johnn ha quindi tentato di diventare utente lightdm con un su comando, anch'esso fallito. Ciò è correlato all'attività mostrata nelle Figure 21 e 22.
Conclusioni dalla mia indagine
- L'utente john ha cercato, scaricato, compilato e installato un rootkit chiamato xingyiquan sul server pfe1. Il rootkit xingyiquan nasconde processi, file, directory, processi e connessioni di rete; aggiunge backdoor; e altro ancora.
- L'utente john ha creato, eliminato e ricreato un altro account su pfe1 denominato johnn. L'utente john ha creato un file nascosto nella home directory dell'utente johnn per oscurare l'esistenza di questo account utente.
- L'utente john ha copiato il file
/bin/truesu/bin/falsee poi/bin/bashsu/bin/falseper facilitare gli accessi di account di sistema normalmente non utilizzati per gli accessi interattivi. - L'utente john ha creato le password per gli account di sistema whoopsie e lightdm. Questi account normalmente non hanno password.
- L'account utente johnn è stato connesso con successo e l'utente johnn ha tentato senza successo di diventare utenti whoopsie e lightdm.
- Il server pfe1 è stato seriamente compromesso.
I miei consigli per PFE
- Ricostruisci il server pfe1 dalla distribuzione originale e applica tutte le patch pertinenti al sistema prima di rimetterlo in servizio.
- Imposta un server syslog centralizzato e fai in modo che tutti i sistemi nel cloud ibrido PFE registrino sul server syslog centralizzato e ai registri locali per consolidare i dati di registro e prevenire la manomissione dei registri di sistema. Utilizzare un prodotto SIEM (Security Information and Event Monitoring) per facilitare la revisione e la correlazione degli eventi di sicurezza.
- Implementare
bashtimestamp dei comandi su tutti i server aziendali. - Abilita il log di controllo dell'account root su tutti i server PFE e indirizza i log di controllo al server syslog centralizzato dove possono essere correlati con altre informazioni di log.
- Esamina il sistema con l'indirizzo IP
192.168.56.1per violazioni e compromessi, in quanto è stato utilizzato come punto cardine nel compromesso di pfe1.
Se hai utilizzato la scientifica per analizzare i compromessi del tuo filesystem Linux, condividi i tuoi suggerimenti e consigli nei commenti.
Gary Smith parlerà al LinuxFest Northwest quest'anno. Guarda gli highlights del programma o registrati per partecipare.