Le espressioni regolari possono essere uno degli strumenti più potenti nella tua cassetta degli attrezzi come utente Linux, amministratore di sistema o anche come programmatore. Può anche essere una delle cose più scoraggianti da imparare, ma non deve esserlo! Sebbene ci siano un numero infinito di modi per scrivere un'espressione, non è necessario imparare ogni singolo interruttore e flag. In questo breve tutorial, ti mostrerò alcuni semplici modi per usare regex che ti faranno funzionare in pochissimo tempo e condividerò alcune risorse di follow-up che ti renderanno un maestro dell'espressione regolare, se lo desideri.
Una rapida panoramica
Le espressioni regolari, denominate anche pattern "regex" o anche "dichiarazioni regolari", sono in termini semplici "una sequenza di caratteri che definisce un pattern di ricerca". L'idea è nata negli anni '50, quando Stephen Cole Kleene ha scritto una descrizione di un'idea che ha chiamato "linguaggio regolare", di cui una parte è diventata nota come "teorema di Kleene". Ad un livello molto alto, dice che se gli elementi della lingua possono essere definiti, allora un'espressione può essere scritta per abbinare i modelli all'interno di quella lingua.
Più risorse Linux
- Comandi Linux cheat sheet
- Cheat sheet sui comandi avanzati di Linux
- Corso online gratuito:Panoramica tecnica RHEL
- Cheat sheet della rete Linux
- Cheat sheet di SELinux
- Cheat sheet dei comandi comuni di Linux
- Cosa sono i container Linux?
- I nostri ultimi articoli su Linux
Da allora, le espressioni regolari hanno fatto parte anche dei primi programmi Unix, inclusi vi, sed, awk, grep e altri. In effetti, la parola grep deriva dal comando utilizzato nel primo editor "ed", ovvero g/re/p , che essenzialmente significa "esegui una ricerca globale per questa espressione regolare e stampa le righe". Fantastico!
Perché abbiamo bisogno delle espressioni regolari
Come accennato in precedenza, le espressioni regolari vengono utilizzate per definire un modello che ci aiuti a trovare una corrispondenza oa "trovare" oggetti che corrispondono a quel modello. Questi oggetti possono essere file in un filesystem quando si usa find comando per esempio, o un blocco di testo in un file che potremmo cercare usando grep, awk, vi o sed, per esempio.
Inizia con le basi
Cominciamo proprio dall'inizio; è un ottimo punto di partenza.
La prima regex che tutti sembrano imparare è probabilmente quella che già conosci e non ti sei reso conto di cosa fosse. Hai mai desiderato stampare un elenco di file in una directory, ma era troppo lungo? Forse hai visto qualcuno digitare \*.gif per elencare le immagini GIF in una directory, come:
$ ls *.gif
Questa è un'espressione regolare!
Quando si scrivono espressioni regolari, alcuni caratteri hanno un significato speciale per permetterci di andare oltre la corrispondenza dei soli caratteri per la corrispondenza di interi set di caratteri. In questo caso, il * il carattere, chiamato anche "stella" o "splat", prende il posto dei nomi dei file e consente di abbinare tutti i file che terminano con .gif .
Cerca modelli in un file
Il passaggio successivo nell'addestramento di regex foo è la ricerca di modelli all'interno di un file, in particolare utilizzando il modello di sostituzione per apportare modifiche rapide.
Due modi comuni per farlo sono:
- Utilizzare vi per aprire il file, cercare un pattern e apportare la modifica (anche automaticamente utilizzando la sostituzione).
- Utilizza "stream editor", alias sed, per eseguire una ricerca programmatica all'interno del file e apportare le modifiche.
Iniziamo imparando un po' di regex usando vi per modificare il seguente file:
The quick brown fox jumped over the lazy dog.
Simple test
Harder test
Extreme test case
ABC 123 abc 567
The dog is lazy
Ora, con questo file aperto in vi, diamo un'occhiata ad alcuni esempi di espressioni regolari che ci aiuteranno a trovare alcune stringhe corrispondenti all'interno e persino a sostituirle automaticamente.
Per semplificare le cose, impostiamo vi per ignorare le maiuscole. Digita set ic per abilitare la ricerca senza distinzione tra maiuscole e minuscole.
Ora, per iniziare a cercare in vi, digita / carattere seguito dal tuo modello di ricerca.
Cerca elementi all'inizio o alla fine di una riga
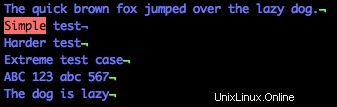
Per trovare una riga che inizi con "Semplice", utilizza questo modello regex:
/^Simple
Si noti nell'immagine sottostante che è evidenziata solo la riga che inizia con "Semplice". Il simbolo del carato (^ ) è l'equivalente regolare di "inizia con".
Quindi, utilizziamo il $ simbolo, che in regex speak è "ends with".
/test$
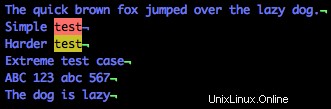
Vedi come evidenzia entrambe le righe che terminano con "test"? Inoltre, nota che la quarta riga contiene la parola test, ma non alla fine, quindi questa riga non è evidenziata.
Questo è il potere delle espressioni regolari, che ti dà la possibilità di esaminare rapidamente un gran numero di corrispondenze con facilità, ma in modo specifico di approfondire solo le corrispondenze esatte.
Test per la frequenza di occorrenza
Per estendere ulteriormente le tue abilità nelle espressioni regolari, diamo un'occhiata ad alcuni caratteri speciali più comuni che ci consentono di cercare non solo il testo corrispondente, ma anche schemi di corrispondenza.
Caratteri di corrispondenza della frequenza:
| Personaggio | Significato | Esempio |
|---|---|---|
* | Zero o più | ab* – la lettera a seguito da zero o più b 's |
+ | Uno o più | ab+ – la lettera a seguito da uno o più b 's |
? | Zero o uno | ab? – zero o solo una b |
{n} | Dato un numero, trova esattamente quel numero | ab{2} – la lettera a seguito esattamente da due b 's |
{n,} | Dato un numero, trova almeno quel numero | ab{2,} – la lettera a seguito da almeno due b 's |
{n,y} | Dati due numeri, trova un intervallo di quel numero | ab{1,3} – la lettera a seguito da uno a tre b 's |
Trova classi di caratteri
Il passaggio successivo nell'addestramento delle espressioni regolari consiste nell'usare classi di caratteri nel nostro pattern matching. Ciò che è importante notare qui è che queste classi possono essere combinate come un elenco, come [a,d,x,z] o come un intervallo, ad esempio [a-z] e che i caratteri di solito fanno distinzione tra maiuscole e minuscole.
Per vedere questo lavoro in vi, dovremo disattivare il caso ignore impostato in precedenza. Digitiamo:set noic per disattivare nuovamente Ignora maiuscole/minuscole.
Alcune classi di caratteri comuni utilizzate come intervalli sono:
- a-z:tutti i caratteri minuscoli
- A-Z:tutti i caratteri MAIUSCOLI
- 0-9 – numeri
Ora, proviamo una ricerca simile a quella che abbiamo eseguito in precedenza:
/tT
Noti che non trova nulla? Questo perché l'espressione regolare precedente cerca esattamente "tT". Se lo sostituiamo con:
/[tT]
Vedremo che le T minuscole e MAIUSCOLE sono abbinate nel documento.
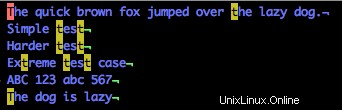
Ora, concateniamo un paio di intervalli di classi e vediamo cosa otteniamo. Prova:
/[A-Z1-3]
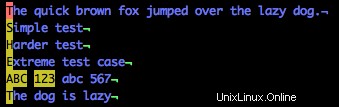
Nota che le lettere maiuscole e 123 sono evidenziate, ma non le lettere minuscole (compresa la fine della riga cinque).
Bandiere
L'ultimo passaggio nell'addestramento iniziale dell'espressione regolare è comprendere i flag che esistono per cercare tipi speciali di caratteri senza doverli elencare in un intervallo.
.– qualsiasi carattere\s– spazio bianco\w– parola\d– cifra (numero)
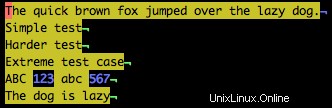
Ad esempio, per trovare tutte le cifre nel testo di esempio, utilizzare:
/\d
Nota nell'esempio seguente che tutti i numeri sono evidenziati.
Per abbinare il contrario, di solito usi la stessa bandiera, ma in MAIUSCOLO. Ad esempio:
\S– non uno spazio\W– non una parola\D– non una cifra
Si noti nell'esempio seguente che utilizzando \D , vengono evidenziati tutti i caratteri TRANNE i numeri.
Ricerca con sed
Una breve nota su sed:è un editor di flussi, il che significa che non interagisci con un'interfaccia utente. Prende il flusso in entrata da un lato e lo scrive sull'altro lato.
L'uso di sed è molto simile a vi, tranne per il fatto che gli dai l'espressione regolare per cercare e sostituire e restituisce l'output. Ad esempio:
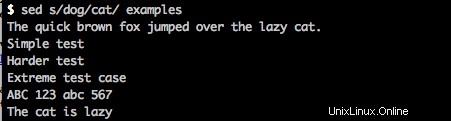
sed s/dog/cat/ examples
ritornerà sullo schermo:
Se vuoi salvare quel file, è solo leggermente più complicato. Dovrai concatenare un paio di comandi per a) scrivere quel file e b) copiarlo sopra il primo file.
Per fare ciò, prova:
sed s/dog/cat/ examples > temp.out; mv temp.out examples
Ora, se guardi i tuoi examples file, vedrai che la parola "cane" è stata sostituita.
The quick brown fox jumped over the lazy cat.
Simple test
Harder test
Extreme test case
ABC 123 abc 567
The cat is lazy
Per ulteriori informazioni
Spero che questa sia stata una panoramica utile delle espressioni regolari. Ovviamente, questa è solo la punta dell'iceberg e spero che continuerai a conoscere questo potente strumento esaminando le risorse aggiuntive di seguito.
Dove trovare assistenza
- La mia risorsa preferita è il PERL Pocket Reference
- Per una padronanza avanzata delle espressioni regolari, dai un'occhiata a Padronanza delle espressioni regolari di Jeff Friedl
Per altri esempi, controlla
- Come trovare file in Linux
- Convalida dei dati in Perl con Regexp::Common
- 7 motivi per amare Vim