Bpftrace è un nuovo tracciante open source per Linux per l'analisi dei problemi di prestazioni di produzione e la risoluzione dei problemi del software. I suoi utenti e collaboratori includono Netflix, Facebook, Red Hat, Shopify e altri, ed è stato creato da Alastair Robertson, uno sviluppatore di talento con sede nel Regno Unito che ha vinto vari concorsi di programmazione.
Linux ha già molti strumenti per le prestazioni, ma spesso sono basati su counter e hanno una visibilità limitata. Ad esempio, iostat(1) o un agente di monitoraggio possono indicare la latenza media del disco, ma non la distribuzione di questa latenza. Le distribuzioni possono rivelare più modalità o valori anomali, che potrebbero essere la vera causa dei tuoi problemi di prestazioni. Bpftrace è adatto per questo tipo di analisi:scomporre le metriche in distribuzioni o log per evento e creare nuove metriche per la visibilità negli angoli ciechi.
Puoi usare bpftrace tramite one-liner o script e viene fornito con molti strumenti prescritti. Ecco un esempio che traccia la distribuzione della latenza di lettura per il PID 181 e lo mostra come un istogramma power-of-two:
# bpftrace -e 'kprobe:vfs_read /pid == 30153/ { @start[tid] = nsecs; }
kretprobe:vfs_read /@start[tid]/ { @ns = hist(nsecs - @start[tid]); delete(@start[tid]); }'
Attaching 2 probes...
^C
@ns:
[256, 512) 10900 |@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@ |
[512, 1k) 18291 |@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@|
[1k, 2k) 4998 |@@@@@@@@@@@@@@ |
[2k, 4k) 57 | |
[4k, 8k) 117 | |
[8k, 16k) 48 | |
[16k, 32k) 109 | |
[32k, 64k) 3 | | Questo esempio strumenta un evento su migliaia disponibili. Se hai qualche strano problema di prestazioni, probabilmente c'è qualche one-liner bpftrace che può far luce su di esso. Per ambienti di grandi dimensioni, questa capacità può aiutarti a risparmiare milioni. Per gli ambienti più piccoli, può essere più utile nell'eliminare i valori anomali di latenza.
Il terminale Linux
- I 7 migliori emulatori di terminale per Linux
- 10 strumenti da riga di comando per l'analisi dei dati in Linux
- Scarica ora:cheat sheet SSH
- Cheat sheet sui comandi avanzati di Linux
- Esercitazioni sulla riga di comando di Linux
In precedenza ho scritto di bpftrace rispetto ad altri traccianti, incluso BCC (BPF Compiler Collection). BCC è ottimo per strumenti e agenti complessi in scatola. Bpftrace è il migliore per sceneggiature brevi e indagini ad hoc. In questo articolo, riassumerò il linguaggio bpftrace, i tipi di variabili, le sonde e gli strumenti.
Bpftrace utilizza BPF (Berkeley Packet Filter), un motore di esecuzione interno al kernel che elabora un set di istruzioni virtuale. BPF è stato esteso (aka eBPF) negli ultimi anni per fornire un modo sicuro per estendere le funzionalità del kernel. È diventato anche un argomento caldo nell'ingegneria dei sistemi, con almeno 24 conferenze su BPF all'ultima conferenza dell'idraulico Linux. BPF è nel kernel Linux e bpftrace è il modo migliore per iniziare a utilizzare BPF per l'osservabilità.
Consulta la guida all'INSTALLAZIONE di bpftrace per come installarlo e ottieni l'ultima versione; 0.9.2 è stato appena rilasciato. Per i cluster Kubernetes, esiste anche kubectl-trace per eseguirlo.
Sintassi
probe[,probe,...] /filter/ { action }La sonda specifica quali eventi strumentare. Il filtro è facoltativo e può filtrare gli eventi in base a un'espressione booleana e l'azione è il mini-programma che viene eseguito.
Ecco ciao mondo:
# bpftrace -e 'BEGIN { printf("Hello eBPF!\n"); }'La sonda è BEGIN , una sonda speciale che viene eseguita all'inizio del programma (come awk). Non c'è nessun filtro. L'azione è un printf() dichiarazione.
Ora un esempio reale:
# bpftrace -e 'kretprobe:sys_read /pid == 181/ { @bytes = hist(retval); }'Questo utilizza un kretprobe per strumentare il ritorno di sys_read() funzione del kernel. Se il PID è 181, una variabile mappa speciale @bytes è popolato con una funzione di istogramma log2 con il valore restituito retval di sys_read() . Questo produce un istogramma della dimensione di lettura restituita per PID 181. La tua app esegue molte letture di un byte? Forse può essere ottimizzato.
Tipi di sonda
Queste sono librerie di sonde correlate. I tipi attualmente supportati sono (ne verranno aggiunti altri):
| Tipo | Descrizione |
|---|---|
| traccia | Punti di strumentazione statica del kernel |
| usdt | Traccia definita staticamente a livello di utente |
| kprobe | Strumentazione della funzione dinamica del kernel |
| kretprobe | Strumentazione di restituzione della funzione dinamica del kernel |
| stufa | Strumentazione per funzioni dinamiche a livello utente |
| sonda uretrale | Strumentazione di ritorno di funzioni dinamiche a livello di utente |
| software | Eventi basati su software del kernel |
| hardware | Strumentazione basata su contatore hardware |
| punto di osservazione | Eventi del punto di osservazione della memoria (in sviluppo) |
| profilo | Campionamento a tempo su tutte le CPU |
| intervallo | Report a tempo (da una CPU) |
| INIZIA | Inizio di bpftrace |
| FINE | Fine bpftrace |
La strumentazione dinamica (nota anche come tracciamento dinamico) è la superpotenza che ti consente di tracciare qualsiasi funzione software in un binario in esecuzione senza riavviarlo. Questo ti consente di andare a fondo di qualsiasi problema. Tuttavia, le funzioni che espone non sono considerate un'API stabile, poiché possono cambiare da una versione del software all'altra. Da qui la strumentazione statica, in cui i punti evento sono hardcoded e diventano un'API stabile. Quando scrivi programmi bpftrace, prova a usare prima i tipi statici, prima di quelli dinamici, in modo che i tuoi programmi siano più stabili.
Tipi di variabili
| Variabile | Descrizione |
|---|---|
| @nome | globale |
| @nome[chiave] | hash |
| @nome[tid] | thread-locale |
| $nome | graffiare |
Variabili con @ prefisso usa le mappe BPF, che possono comportarsi come array associativi. Possono essere popolati in due modi:
- Assegnazione variabile:@name =x;
- Assegnazione della funzione:@name =hist(x);
Varie funzioni di popolamento delle mappe sono integrate per fornire metodi rapidi per riepilogare i dati.
Variabili e funzioni integrate
Ecco alcune delle variabili e delle funzioni integrate, ma ce ne sono molte altre.
Variabili integrate:
| Variabile | Descrizione |
|---|---|
| pid | ID processo |
| comunicazione | Nome del processo o del comando |
| nsec | Tempo corrente in nanosecondi |
| kstack | Traccia dello stack del kernel |
| usare | Traccia dello stack a livello di utente |
| arg0...argN | Argomenti funzione |
| args | Argomenti di tracepoint |
| Ritorno | Valore di ritorno della funzione |
| nome | Nome completo della sonda |
Funzioni integrate:
| Funzione | Descrizione |
|---|---|
| printf("...") | Stampa stringa formattata |
| ora("...") | Stampa ora formattata |
| sistema("...") | Esegui comando shell |
| @ =conteggio() | Conta eventi |
| @ =hist(x) | Istogramma Power-of-2 per x |
| @ =lista(x, min, max, passo) | Istogramma lineare per x |
Consulta la guida di riferimento per i dettagli.
Tutorial di una riga
Un ottimo modo per imparare bpftrace è tramite one-liners, che ho trasformato in un tutorial one-liners che copre quanto segue:
| Elenco delle sonde | bpftrace -l 'tracepoint:syscalls:sys_enter_*' |
| Ciao mondo | bpftrace -e 'BEGIN { printf("hello world\n") }' |
| Il file si apre | bpftrace -e 'tracepoint:syscalls:sys_enter_open { printf("%s %s\n", comm, str(args->filename)) }' |
| Syscall conta per processo | bpftrace -e 'tracepoint:raw_syscalls:sys_enter { @[comm] =count() }' |
| Distribuzione dei byte read() | bpftrace -e 'tracepoint:syscalls:sys_exit_read /pid ==18644/ { @bytes =hist(args->retval) }' |
| Traccia dinamica del kernel dei byte read() | bpftrace -e 'kretprobe:vfs_read { @bytes =lhist(retval, 0, 2000, 200) }' |
| Lettura temporizzazione()s | bpftrace -e 'kprobe:vfs_read { @start[tid] =nsecs } kretprobe:vfs_read /@start[tid]/ { @ns[comm] =hist(nsecs - @start[tid]); delete(@start[tid]) }' |
| Conteggia gli eventi a livello di processo | bpftrace -e 'tracepoint:sched:sched* { @[name] =count() } interval:s:5 { exit() }' |
| Profilo degli stack del kernel su CPU | bpftrace -e 'profile:hz:99 { @[stack] =count() }' |
| Traccia programmatore | bpftrace -e 'tracepoint:sched:sched_switch { @[stack] =count() }' |
| Blocca traccia I/O | bpftrace -e 'tracepoint:block:block_rq_issue { @ =hist(args->bytes); } |
| Tracciamento della struttura del kernel (uno script, non una riga) | Comando: bpftrace path.bt , dove il file path.bt è: #include #include kprobe:vfs_open { printf("open path:%s\n", str(((path *)arg0)->dentry->d_name .nome)); } |
Vedi il tutorial per una spiegazione di ciascuno.
Strumenti forniti
A parte le righe singole, i programmi bpftrace possono essere script multiriga. Bpftrace ne contiene 28 come strumenti:
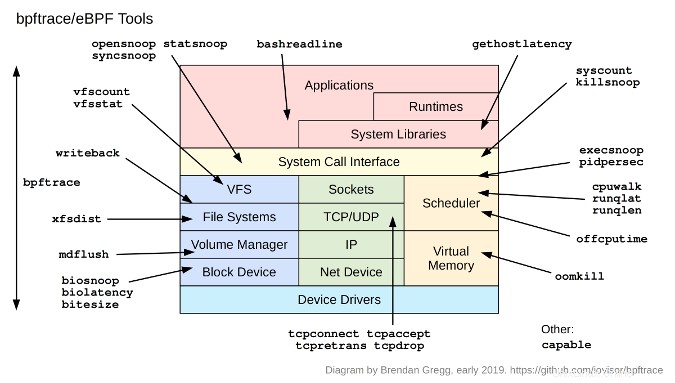
Questi possono essere trovati in /tools directory:
tools# ls *.bt
bashreadline.bt dcsnoop.bt oomkill.bt syncsnoop.bt vfscount.bt
biolatency.bt execsnoop.bt opensnoop.bt syscount.bt vfsstat.bt
biosnoop.bt gethostlatency.bt pidpersec.bt tcpaccept.bt writeback.bt
bitesize.bt killsnoop.bt runqlat.bt tcpconnect.bt xfsdist.bt
capable.bt loads.bt runqlen.bt tcpdrop.bt
cpuwalk.bt mdflush.bt statsnoop.bt tcpretrans.bt
Oltre al loro uso nella diagnosi dei problemi di prestazioni e nella risoluzione dei problemi generali, forniscono anche un altro modo per imparare bpftrace. Ecco alcuni esempi.
Fonte
Ecco il codice per biolatency.bt :
tools# cat -n biolatency.bt
1 /*
2 * biolatency.bt Block I/O latency as a histogram.
3 * For Linux, uses bpftrace, eBPF.
4 *
5 * This is a bpftrace version of the bcc tool of the same name.
6 *
7 * Copyright 2018 Netflix, Inc.
8 * Licensed under the Apache License, Version 2.0 (the "License")
9 *
10 * 13-Sep-2018 Brendan Gregg Created this.
11 */
12
13 BEGIN
14 {
15 printf("Tracing block device I/O... Hit Ctrl-C to end.\n");
16 }
17
18 kprobe:blk_account_io_start
19 {
20 @start[arg0] = nsecs;
21 }
22
23 kprobe:blk_account_io_done
24 /@start[arg0]/
25
26 {
27 @usecs = hist((nsecs - @start[arg0]) / 1000);
28 delete(@start[arg0]);
29 }
30
31 END
32 {
33 clear(@start);
34 }
È semplice, facile da leggere e abbastanza breve da poter essere incluso in una diapositiva. Questa versione utilizza la traccia dinamica del kernel per strumentare blk_account_io_start() e blk_account_io_done() funzioni e passa un timestamp tra di loro digitato su arg0 a ogni. arg0 su kprobe è il primo argomento di quella funzione, che è la richiesta struct * e il suo indirizzo di memoria viene utilizzato come identificatore univoco.
File di esempio
Puoi vedere schermate e spiegazioni di questi strumenti nel repository GitHub come *_example.txt File. Ad esempio:
tools# more biolatency_example.txt
Demonstrations of biolatency, the Linux BPF/bpftrace version.
This traces block I/O, and shows latency as a power-of-2 histogram. For example:
# biolatency.bt
Attaching 3 probes...
Tracing block device I/O... Hit Ctrl-C to end.
^C
@usecs:
[256, 512) 2 | |
[512, 1K) 10 |@ |
[1K, 2K) 426 |@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@|
[2K, 4K) 230 |@@@@@@@@@@@@@@@@@@@@@@@@@@@@ |
[4K, 8K) 9 |@ |
[8K, 16K) 128 |@@@@@@@@@@@@@@@ |
[16K, 32K) 68 |@@@@@@@@ |
[32K, 64K) 0 | |
[64K, 128K) 0 | |
[128K, 256K) 10 |@ |
While tracing, this shows that 426 block I/O had a latency of between 1K and 2K
usecs (1024 and 2048 microseconds), which is between 1 and 2 milliseconds.
There are also two modes visible, one between 1 and 2 milliseconds, and another
between 8 and 16 milliseconds: this sounds like cache hits and cache misses.
There were also 10 I/O with latency 128 to 256 ms: outliers. Other tools and
instrumentation, like biosnoop.bt, can shed more light on those outliers.
[...]
A volte può essere più efficace passare direttamente al file di esempio quando si cerca di comprendere questi strumenti, poiché l'output potrebbe essere evidente (in base alla progettazione!).
Pagine man
Ci sono anche pagine man per ogni strumento nel repository GitHub in /man/man8. Includono sezioni sui campi di output e sull'overhead previsto dello strumento.
# nroff -man man/man8/biolatency.8
biolatency(8) System Manager's Manual biolatency(8)
NAME
biolatency.bt - Block I/O latency as a histogram. Uses bpftrace/eBPF.
SYNOPSIS
biolatency.bt
DESCRIPTION
This tool summarizes time (latency) spent in block device I/O (disk
I/O) as a power-of-2 histogram. This allows the distribution to be
studied, including modes and outliers. There are often two modes, one
for device cache hits and one for cache misses, which can be shown by
this tool. Latency outliers will also be shown.
[...]
Scrivere tutte queste pagine man è stata la parte meno divertente dello sviluppo di questi strumenti, e alcuni hanno richiesto più tempo per la scrittura rispetto allo sviluppo dello strumento, ma è bello vedere il risultato finale.
bpftrace vs BCC
Dal momento che eBPF si è unito nel kernel, la maggior parte degli sforzi è stata rivolta al frontend BCC, che fornisce una libreria BPF e interfacce Python, C++ e Lua per la scrittura di programmi. Ho sviluppato molti strumenti in BCC/Python; funziona benissimo, anche se la codifica in BCC è dettagliata. Se stai risolvendo un problema di prestazioni, bpftrace è migliore per le tue query personalizzate una tantum. Se stai scrivendo uno strumento con molte opzioni della riga di comando o un agente che utilizza librerie Python, ti consigliamo di considerare l'utilizzo di BCC.
Nel team delle prestazioni di Netflix, utilizziamo entrambi:BCC per lo sviluppo di strumenti predefiniti che altri possono facilmente utilizzare e per lo sviluppo di agenti; e bpftrace per analisi ad hoc. Il team di ingegneri di rete ha utilizzato BCC per sviluppare un agente per le sue esigenze. Il team di sicurezza è più interessato a bpftrace per una rapida strumentazione ad hoc per rilevare le vulnerabilità zero-day. E mi aspetto che i team di sviluppatori li utilizzino entrambi senza saperlo, tramite le GUI self-service che stiamo costruendo (Vector), e occasionalmente possono inviare SSH in un'istanza ed eseguire uno strumento preconfezionato o bpftrace ad hoc one-liner.
Ulteriori informazioni
- Il repository bpftrace su GitHub
- Il tutorial di bpftrace one-liners
- La guida di riferimento di bpftrace
- Il repository BCC per strumenti più complessi basati su BPF
Ho anche un libro in uscita quest'anno che copre bpftrace:BPF Performance Tools:Linux System and Application Observability , che sarà pubblicato da Addison Wesley e che contiene molti nuovi strumenti bpftrace.
Grazie ad Alastair Robertson per aver creato bpftrace e alle comunità bpftrace, BCC e BPF per tutto il lavoro degli ultimi cinque anni.