
In questo tutorial, ti mostreremo come installare Apache Hadoop su Debian 11. Per chi non lo sapesse, Apache Hadoop è una piattaforma software open source basata su Java che gestisce l'elaborazione e l'archiviazione dei dati per le applicazioni Big Data. È progettato per scalare da server singoli a migliaia di macchine, ognuna delle quali offre elaborazione e archiviazione locali.
Questo articolo presuppone che tu abbia almeno una conoscenza di base di Linux, sappia come usare la shell e, soprattutto, che ospiti il tuo sito sul tuo VPS. L'installazione è abbastanza semplice e presuppone che tu sono in esecuzione nell'account root, in caso contrario potrebbe essere necessario aggiungere 'sudo ' ai comandi per ottenere i privilegi di root. Ti mostrerò passo passo l'installazione di Apache Hadoop su una Debian 11 (Bullseye).
Prerequisiti
- Un server che esegue uno dei seguenti sistemi operativi:Debian 11 (Bullseye).
- Si consiglia di utilizzare una nuova installazione del sistema operativo per prevenire potenziali problemi.
- Accesso SSH al server (o semplicemente apri Terminal se sei su un desktop).
- Un
non-root sudo usero accedere all'root user. Ti consigliamo di agire comenon-root sudo user, tuttavia, poiché puoi danneggiare il tuo sistema se non stai attento quando agisci come root.
Installa Apache Hadoop su Debian 11 Bullseye
Passaggio 1. Prima di installare qualsiasi software, è importante assicurarsi che il sistema sia aggiornato eseguendo il seguente apt comandi nel terminale:
sudo apt update sudo apt upgrade
Passaggio 2. Installazione di Java.
Apache Hadoop è un'applicazione basata su Java. Quindi dovrai installare Java nel tuo sistema:
sudo apt install default-jdk default-jre
Verifica l'installazione di Java:
java -version
Passaggio 3. Creazione dell'utente Hadoop.
Esegui il comando seguente per creare un nuovo utente con il nome Hadoop:
adduser hadoop
Successivamente, passa all'utente Hadoop una volta creato l'utente:
su - hadoop
Ora è il momento di generare una chiave ssh perché Hadoop richiede l'accesso ssh per gestire il suo nodo, macchina remota o locale, quindi per il nostro singolo nodo della configurazione di Hadoop configuriamo in modo tale da avere accesso al localhost:
ssh-keygen -t rsa
Dopodiché, dai il permesso al file authorized_keys:
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys chmod 0600 ~/.ssh/authorized_keys
Quindi, verifica la connessione SSH senza password con il seguente comando:
ssh your-server-IP-address
Passaggio 4. Installazione di Apache Hadoop su Debian 11.
Per prima cosa, passa all'utente Hadoop e scarica l'ultima versione di Hadoop dalla pagina ufficiale utilizzando il seguente wget comando:
su - hadoop wget https://www.apache.org/dyn/closer.cgi/hadoop/common/hadoop-3.3.1/hadoop-3.3.1-src.tar.gz
Successivamente, estrai il file scaricato con il seguente comando:
tar -xvzf hadoop-3.3.1.tar.gz
Una volta decompresso, cambia la directory corrente nella cartella Hadoop:
su root cd /home/hadoop mv hadoop-3.3.1 /usr/local/hadoop
Quindi, crea una directory in cui archiviare i log con il seguente comando:
mkdir /usr/local/hadoop/logs
Cambia la proprietà della directory Hadoop in Hadoop:
chown -R hadoop:hadoop /usr/local/hadoop su hadoop
Dopodiché, configuriamo le variabili di ambiente Hadoop:
nano ~/.bashrc
Aggiungi la seguente configurazione:
export HADOOP_HOME=/usr/local/hadoop export HADOOP_INSTALL=$HADOOP_HOME export HADOOP_MAPRED_HOME=$HADOOP_HOME export HADOOP_COMMON_HOME=$HADOOP_HOME export HADOOP_HDFS_HOME=$HADOOP_HOME export YARN_HOME=$HADOOP_HOME export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib/native"
Salva e chiudi il file. Quindi, attiva le variabili d'ambiente:
source ~/.bashrc
Passaggio 5. Configura Apache Hadoop.
- Configura le variabili di ambiente Java:
sudo nano $HADOOP_HOME/etc/hadoop/hadoop-env.sh
Aggiungi la seguente configurazione:
export JAVA_HOME=/usr/lib/jvm/java-11-openjdk-amd64 export HADOOP_CLASSPATH+=" $HADOOP_HOME/lib/*.jar"
Successivamente, dobbiamo scaricare il file di attivazione Javax:
cd /usr/local/hadoop/lib sudo wget https://jcenter.bintray.com/javax/activation/javax.activation-api/1.2.0/javax.activation-api-1.2.0.jar
Verifica la versione di Apache Hadoop:
hadoop version
Risultato:
Hadoop 3.3.1
- Configura il file core-site.xml:
nano $HADOOP_HOME/etc/hadoop/core-site.xml
Aggiungi il seguente file:
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://0.0.0.0:9000</value>
<description>The default file system URI</description>
</property>
</configuration> - Configura il file hdfs-site.xml:
Prima di configurare, creare una directory per la memorizzazione dei metadati del nodo:
mkdir -p /home/hadoop/hdfs/{namenode,datanode}
chown -R hadoop:hadoop /home/hadoop/hdfs Quindi, modifica il hdfs-site.xml file e definire la posizione della directory:
nano $HADOOP_HOME/etc/hadoop/hdfs-site.xml
Aggiungi la seguente riga:
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.name.dir</name>
<value>file:///home/hadoop/hdfs/namenode</value>
</property>
<property>
<name>dfs.data.dir</name>
<value>file:///home/hadoop/hdfs/datanode</value>
</property>
</configuration> - Configura il file mapred-site.xml:
Ora modifichiamo il mapred-site.xml file:
nano $HADOOP_HOME/etc/hadoop/mapred-site.xml
Aggiungi la seguente configurazione:
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration> - Configura il file yarn-site.xml:
Dovresti modificare yarn-site.xml file e definire le impostazioni relative a YARN:
nano $HADOOP_HOME/etc/hadoop/yarn-site.xml
Aggiungi la seguente configurazione:
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration> - Formatta NameNode HDFS.
Esegui il seguente comando per formattare il Namenode Hadoop:
hdfs namenode -format
- Avvia il cluster Hadoop.
Ora avviamo NameNode e DataNode con il seguente comando:
start-dfs.sh
Avvia quindi la risorsa YARN e i gestori dei nodi:
start-yarn.sh
Ora puoi verificarli con il seguente comando:
jps
Risultato:
hadoop@idroot.us:~$ jps 58000 NameNode 54697 DataNode 55365 ResourceManager 55083 SecondaryNameNode 58556 Jps 55365 NodeManager
Passaggio 6. Accesso all'interfaccia Web di Hadoop.
Una volta installato correttamente, apri il tuo browser web e accedi ad Apache Hadoop utilizzando l'URL http://your-server-ip-address:9870 . Verrai reindirizzato all'interfaccia web di Hadoop:
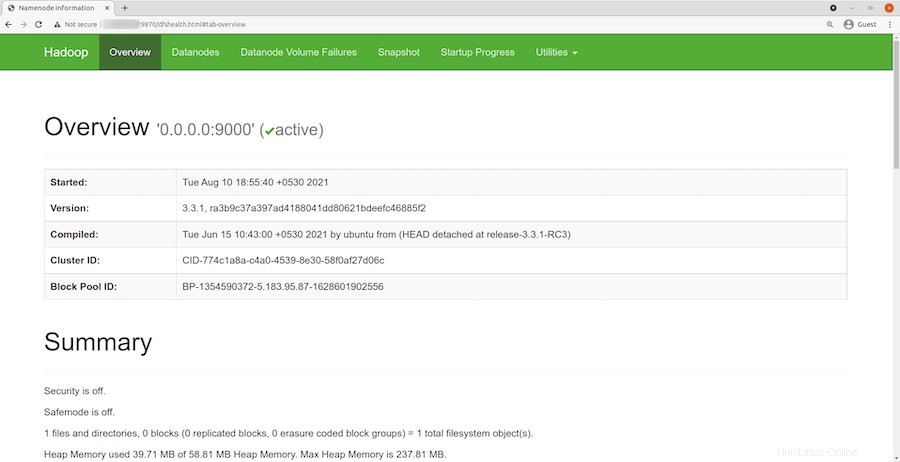
Naviga nel tuo URL o IP localhost per accedere ai singoli DataNode :http://your-server-ip-address:9864
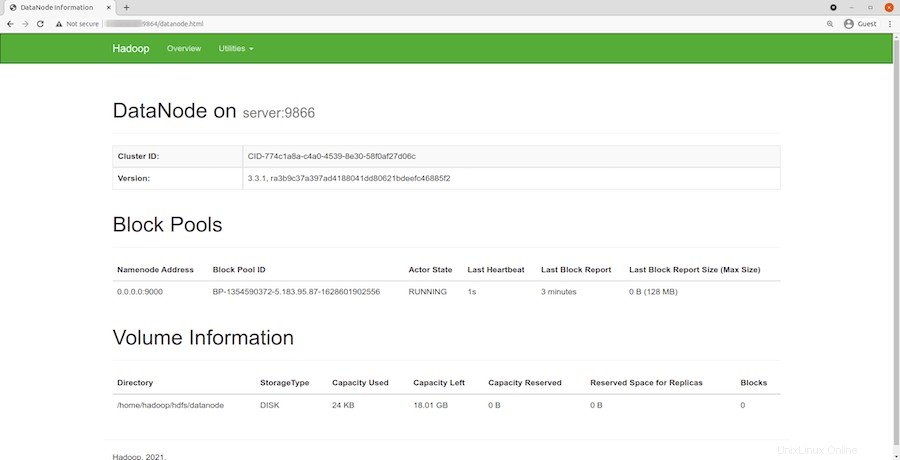
Per accedere a YARN Resource Manager, utilizza l'URL http://your-server-ip-adddress:8088 . Dovresti vedere la seguente schermata:
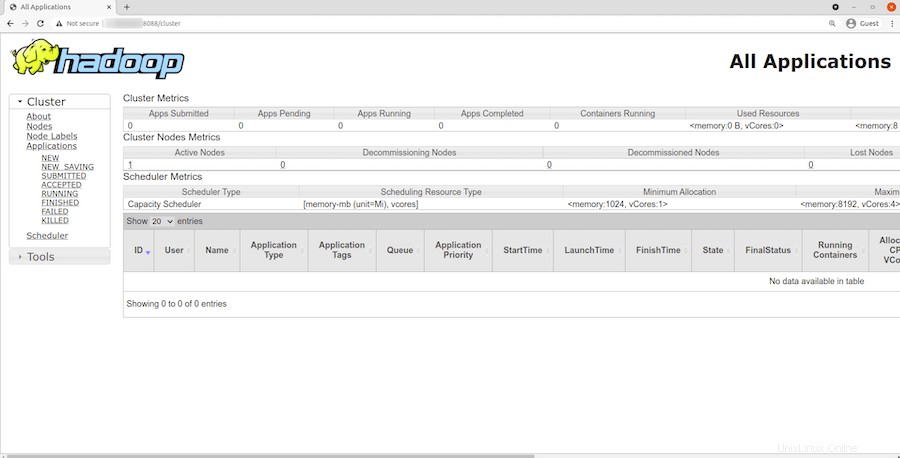
Congratulazioni! Hai installato correttamente Hadoop. Grazie per aver utilizzato questo tutorial per installare l'ultima versione di Apache Hadoop su Debian 11 Bullseye. Per ulteriore aiuto o informazioni utili, ti consigliamo di controllare l'Apache ufficiale sito web.