Awk è l'utilità più popolare sviluppata allo scopo di estrarre dati, elaborare testi e, inoltre, creare report formattati. È molto più simile a sed ma più potente di sed poiché sed ha dei limiti nell'elaborazione del testo. AWK non ha un significato specifico per il suo nome in quanto viene nominato utilizzando la prima lettera dei suoi sviluppatori Alfred Aho, Peter J. Weinberger e Brian Kernighan.
In questo articolo impareremo 10 fantastici comandi awk che devi conoscere. Ho creato e aggiunto il seguente set di dati in student.txt come esempio. Il set di dati ha 4 colonne in cui il primo campo contiene il nome, il secondo campo contiene il secondo nome, il terzo campo contiene età e l'ultimo contiene la classe.

Stampa di un campo specifico utilizzando la variabile
Awk ha molte variabili predefinite che hanno il loro rispettivo scopo. Usando questo comando possiamo stampare tutti i dati del campo specifico usando $x dove x si riferisce alla posizione di numerazione del campo.
$ awk '{print $1, $2}' student.txt

Variabile BEGIN
La variabile BEGIN viene utilizzata per aggiungere un'intestazione o un titolo ai dati risultanti mentre eseguiva lo script prima di elaborare i dati. Aiuta nell'indicizzazione durante la formattazione delle tabelle di dati. Nell'esempio seguente, ho stampato del testo come indicizzazione e quindi ho stampato tutti i nomi degli studenti.
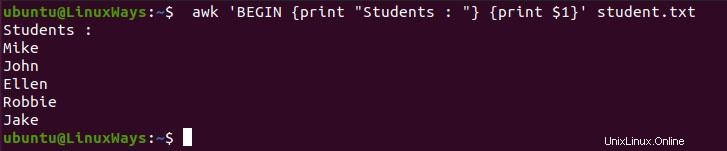
$ awk 'BEGIN {print "Students : "} {print $1}' student.txt
Variabile FINE
END è esattamente l'opposto di BEGIN poiché esegue lo script dopo l'elaborazione dei dati. Può essere utilizzato per la rendicontazione finale del set di dati. Nell'esempio seguente, ho stampato tutta l'età degli studenti e poi ho stampato alcuni messaggi finali.
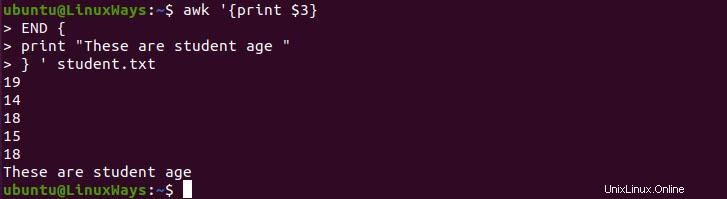
$ awk '{print $3}
END {
print "These are student age "
} ' student.txt
Separatore di file
Spazio e Tab spazio sono separatori predefiniti del comando awk, tuttavia possiamo separare il testo in base ad altri separatori come virgola, barra, ecc. Per ottenere ciò dobbiamo aggiungere il flag -F al comando e il separatore di fornitura tra virgolette singole .
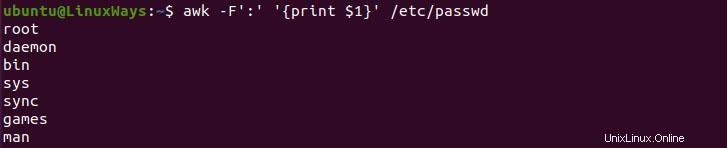
$ awk -F':' '{print $1}' /etc/passwd
Esecuzione di script da file
Possiamo anche eseguire lo script awk dal file che ci fornisce la tendenza a creare report in modo efficiente. Per questo, è necessario creare il file, quindi scrivere lo script ed eseguirlo utilizzando il comando awk. Per la demo, puoi creare un nome file demo_script e copiare e incollare il seguente script.
$ vi demo_script
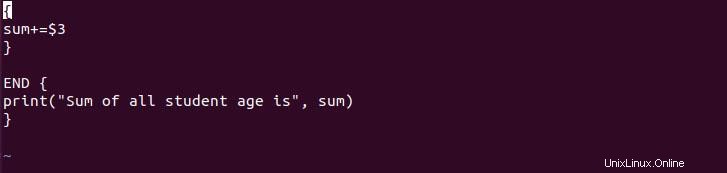
{
sum+=$3
}
END {
print("Sum of all student age is", sum)
}
Il comando awk fornisce un flag -f per eseguire lo script dal file.
$ awk -f demo_script student.txt

Utilizzo di più script
Possiamo eseguire più script usando il punto e virgola. Nell'esempio seguente, ho stampato del testo, quindi reindirizza l'output, con awk e stampato il risultato modificato.
$ echo "Hello, Dr. John" | awk '{$3="George"; print $0}'

Conta numero di righe
Possiamo assegnare il numero al report utilizzando la variabile NR che è una variabile incorporata awk che stampa automaticamente il numero di riga sul report.
$ awk '{print NR "\t" $0}' student.txt

Conta numero di campi
A volte, durante la preparazione dei dati, ci siamo dimenticati di aggiungere i dati nella colonna specifica che potrebbe causare irregolarità nel rapporto. Possiamo contare i campi utilizzando la variabile NF che ci semplifica la revisione e l'organizzazione dei rapporti.
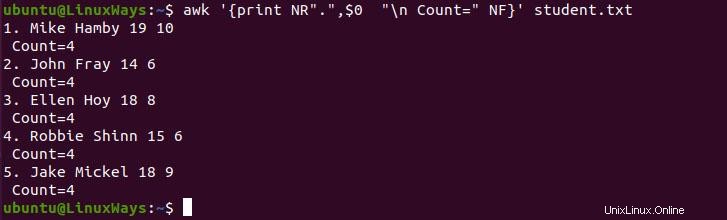
$ awk '{print NR".",$0 "\n Count=" NF}' student.txt
Se Condizione
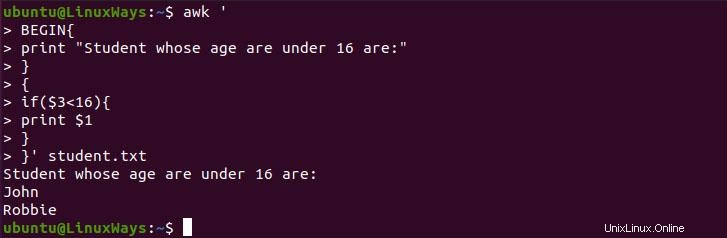
Possiamo usare if condition nella preparazione di un report condizionale. Nell'esempio seguente, stampiamo tutti gli studenti la cui età è inferiore a 16 anni
$ awk '
BEGIN{
print "Student whose age are under 16 are:"
}
{
if($3<16){
print $1
}
}' student.txt
Per il ciclo
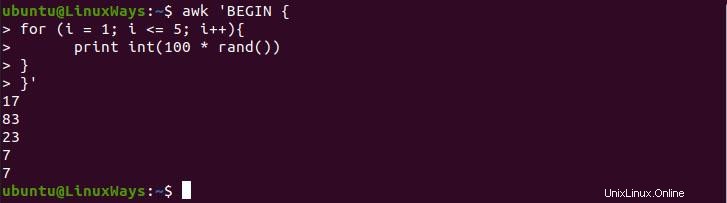
Nell'esempio seguente, usiamo il ciclo for per stampare 5 numeri casuali in successione. Per generare numeri casuali useremo la funzione rand() che è una funzione integrata nel sistema. Questa funzione genererà un numero casuale in decimale, quindi dobbiamo moltiplicare 100 per ottenere numeri casuali da 1 a 100.
$ awk 'BEGIN {
for (i = 1; i <= 5; i++){
print int(100 * rand())
}
}'
Conclusione
In questo articolo, abbiamo appreso dei 10 fantastici comandi e script awk. Spero che questo articolo ti piaccia.